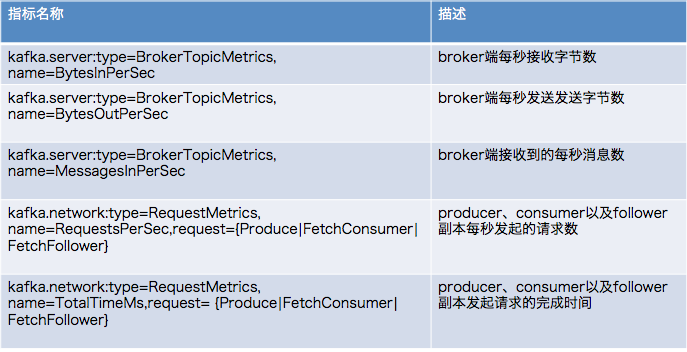
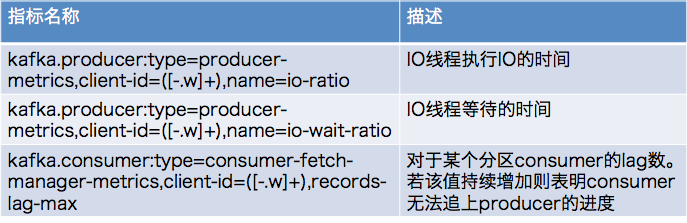
截止到今年,已经有超过 20 亿活跃的安卓设备。安卓手机的迅速普及很大程度上是因为各式各样的智能 app,从地图到图片编辑器应有尽有。随着深度学习的出现,我们的手机 app 将变得更加智能。下一代由深度学习驱动的手机 app 将可以学习并为你定制功能。一个很显著的例子是「Microsoft Swiftkey」,这是一个键盘 app, 能通过学习你常用的单词和词组来帮助你快速打字。
计算机视觉,自然语言处理,语音识别和语音合成等技术能够大大改善用户在移动应用方面的体验。幸运的是,在移动应用方面,有很多工具开发成可以简化深度学习模型的部署和管理。在这篇文章中,我将阐释如何使用 TensorFlow mobile 将 PyTorch 和 Keras 部署到移动设备。
用 TensorFlow mobile 部署模型到安卓设备分为三个步骤:
在这篇文章中,我将介绍整个过程,最后完成一个植入图像识别功能的安卓应用。
安装
本教程会用到 PyTorch 和 Keras 两个框架-遵循下列指导安装你想使用的机器学习框架。安装哪个由你选择。
首先,安装 TensorFlow:
pip3 install tensorflow
如果你是 PyTorch 的开发者,确保你安装的是 PyTorch 的最新版本。关于安装 PyTorch 的指导文件,请查阅我之前的文章:
https://heartbeat.fritz.ai/basics-of-image-classification-with-pytorch-2f8973c51864
如果你是 Keras 的开发者,使用以下命令安装:
pip3 install keras
pip3 install h5py
Android Studio(至少3.0 的版本)
https://developer.android.com/studio
将 PyTorch 模式转成 Keras 模式
这部分仅适用于 PyTorch 开发者。如果你使用的是 Keras,你可以跳到 “将 Keras 模式转成 TensorFlow 模式”章节。
首先我们要做的是将我们的 PyTorch 模式参数转成 Keras 中的同等参数。
为了简化这个过程,我创建了一个脚本来自动运行转化。在此教程中,我们将使用 Squeezenet 。这是一种很小但具备合理精确度的移动架构。在这儿下载预训练模式(只有5M!)。
在转权值之前,我们需要在 PyTorch 和 Keras 中定义 Squeezenet 模型。
如下图所示,在这两种框架下定义 Squeezenet,然后将 PyTorch 权值转成 Keras。
创建文件 convert.py,包括下面的代码并运行脚本。
import torch
import torch.nn as nn
from torch.autograd import Variable
import keras.backend as K
from keras.models import *
from keras.layers import *
import torch
from torchvision.models import squeezenet1_1
class PytorchToKeras(object):
def __init__(self,pModel,kModel):
super(PytorchToKeras,self)
self.__source_layers = []
self.__target_layers = []
self.pModel = pModel
self.kModel = kModel
K.set_learning_phase(0)
def __retrieve_k_layers(self):
for i,layer in enumerate(self.kModel.layers):
if len(layer.weights) > 0:
self.__target_layers.append(i)
def __retrieve_p_layers(self,input_size):
input = torch.randn(input_size)
input = Variable(input.unsqueeze(0))
hooks = []
def add_hooks(module):
def hook(module, input, output):
if hasattr(module,"weight"):
self.__source_layers.append(module)
if not isinstance(module, nn.ModuleList) and not isinstance(module,nn.Sequential) and module != self.pModel:
hooks.append(module.register_forward_hook(hook))
self.pModel.apply(add_hooks)
self.pModel(input)
for hook in hooks:
hook.remove()
def convert(self,input_size):
self.__retrieve_k_layers()
self.__retrieve_p_layers(input_size)
for i,(source_layer,target_layer) in enumerate(zip(self.__source_layers,self.__target_layers)):
weight_size = len(source_layer.weight.data.size())
transpose_dims = []
for i in range(weight_size):
transpose_dims.append(weight_size - i - 1)
self.kModel.layers[target_layer].set_weights([source_layer.weight.data.numpy().transpose(transpose_dims), source_layer.bias.data.numpy()])
def save_model(self,output_file):
self.kModel.save(output_file)
def save_weights(self,output_file):
self.kModel.save_weights(output_file)
"""
We explicitly redefine the Squeezent architecture since Keras has no predefined Squeezent
"""
def squeezenet_fire_module(input, input_channel_small=16, input_channel_large=64):
channel_axis = 3
input = Conv2D(input_channel_small, (1,1), padding="valid" )(input)
input = Activation("relu")(input)
input_branch_1 = Conv2D(input_channel_large, (1,1), padding="valid" )(input)
input_branch_1 = Activation("relu")(input_branch_1)
input_branch_2 = Conv2D(input_channel_large, (3, 3), padding="same")(input)
input_branch_2 = Activation("relu")(input_branch_2)
input = concatenate([input_branch_1, input_branch_2], axis=channel_axis)
return input
def SqueezeNet(input_shape=(224,224,3)):
image_input = Input(shape=input_shape)
network = Conv2D(64, (3,3), strides=(2,2), padding="valid")(image_input)
network = Activation("relu")(network)
network = MaxPool2D( pool_size=(3,3) , strides=(2,2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=16, input_channel_large=64)
network = squeezenet_fire_module(input=network, input_channel_small=16, input_channel_large=64)
network = MaxPool2D(pool_size=(3,3), strides=(2,2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=32, input_channel_large=128)
network = squeezenet_fire_module(input=network, input_channel_small=32, input_channel_large=128)
network = MaxPool2D(pool_size=(3, 3), strides=(2, 2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=48, input_channel_large=192)
network = squeezenet_fire_module(input=network, input_channel_small=48, input_channel_large=192)
network = squeezenet_fire_module(input=network, input_channel_small=64, input_channel_large=256)
network = squeezenet_fire_module(input=network, input_channel_small=64, input_channel_large=256)
#Remove layers like Dropout and BatchNormalization, they are only needed in training
#network = Dropout(0.5)(network)
network = Conv2D(1000, kernel_size=(1,1), padding="valid", name="last_conv")(network)
network = Activation("relu")(network)
network = GlobalAvgPool2D()(network)
network = Activation("softmax",name="output")(network)
input_image = image_input
model = Model(inputs=input_image, outputs=network)
return model
keras_model = SqueezeNet()
#Lucky for us, PyTorch includes a predefined Squeezenet
pytorch_model = squeezenet1_1()
#Load the pretrained model
pytorch_model.load_state_dict(torch.load("squeezenet.pth"))
#Time to transfer weights
converter = PytorchToKeras(pytorch_model,keras_model)
converter.convert((3,224,224))
#Save the weights of the converted keras model for later use
converter.save_weights("squeezenet.h5")
上面是已经转好权值的,你所需要做的是将 Keras 模型保存为 squeezenet.h5。到这一步,我们可以抛弃 PyTorch 模型,继续下一步了。
将 Keras 转成 TensorFlow 模式
到这一步,你已经有了 Keras 模式,无论是从 PyTorch 转化而来的还是直接用 Keras 训练而获得的。你可以在这儿下载预训练的 Keras Squeezenet 模式。下一步是将我们整个的模型架构和权值转成可运行的 TensorFlow 模型。
创建一个新文件 ConvertToTensorflow.py 并添加以下代码。
from keras.models import Model
from keras.layers import *
import os
import tensorflow as tf
def keras_to_tensorflow(keras_model, output_dir, model_name,out_prefix="output_", log_tensorboard=True):
if os.path.exists(output_dir) == False:
os.mkdir(output_dir)
out_nodes = []
for i in range(len(keras_model.outputs)):
out_nodes.append(out_prefix + str(i + 1))
tf.identity(keras_model.output[i], out_prefix + str(i + 1))
sess = K.get_session()
from tensorflow.python.framework import graph_util, graph_io
init_graph = sess.graph.as_graph_def()
main_graph = graph_util.convert_variables_to_constants(sess, init_graph, out_nodes)
graph_io.write_graph(main_graph, output_dir, name=model_name, as_text=False)
if log_tensorboard:
from tensorflow.python.tools import import_pb_to_tensorboard
import_pb_to_tensorboard.import_to_tensorboard(
os.path.join(output_dir, model_name),
output_dir)
"""
We explicitly redefine the Squeezent architecture since Keras has no predefined Squeezenet
"""
def squeezenet_fire_module(input, input_channel_small=16, input_channel_large=64):
channel_axis = 3
input = Conv2D(input_channel_small, (1,1), padding="valid" )(input)
input = Activation("relu")(input)
input_branch_1 = Conv2D(input_channel_large, (1,1), padding="valid" )(input)
input_branch_1 = Activation("relu")(input_branch_1)
input_branch_2 = Conv2D(input_channel_large, (3, 3), padding="same")(input)
input_branch_2 = Activation("relu")(input_branch_2)
input = concatenate([input_branch_1, input_branch_2], axis=channel_axis)
return input
def SqueezeNet(input_shape=(224,224,3)):
image_input = Input(shape=input_shape)
network = Conv2D(64, (3,3), strides=(2,2), padding="valid")(image_input)
network = Activation("relu")(network)
network = MaxPool2D( pool_size=(3,3) , strides=(2,2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=16, input_channel_large=64)
network = squeezenet_fire_module(input=network, input_channel_small=16, input_channel_large=64)
network = MaxPool2D(pool_size=(3,3), strides=(2,2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=32, input_channel_large=128)
network = squeezenet_fire_module(input=network, input_channel_small=32, input_channel_large=128)
network = MaxPool2D(pool_size=(3, 3), strides=(2, 2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=48, input_channel_large=192)
network = squeezenet_fire_module(input=network, input_channel_small=48, input_channel_large=192)
network = squeezenet_fire_module(input=network, input_channel_small=64, input_channel_large=256)
network = squeezenet_fire_module(input=network, input_channel_small=64, input_channel_large=256)
#Remove layers like Dropout and BatchNormalization, they are only needed in training
#network = Dropout(0.5)(network)
network = Conv2D(1000, kernel_size=(1,1), padding="valid", name="last_conv")(network)
network = Activation("relu")(network)
network = GlobalAvgPool2D()(network)
network = Activation("softmax",name="output")(network)
input_image = image_input
model = Model(inputs=input_image, outputs=network)
return model
keras_model = SqueezeNet()
keras_model.load_weights("squeezenet.h5")
output_dir = os.path.join(os.getcwd(),"checkpoint")
keras_to_tensorflow(keras_model,output_dir=output_dir,model_name="squeezenet.pb")
print("MODEL SAVED")
上面的代码将我们的 squeezenet.pb 保存到了 output_dir 中。并在同一文件夹中创建 了 TensorBoard 事件。
为了更加清晰地理解你的模型,你可以用 TensorBoard 将它可视化。
打开命令行并输入
tensorboard –logdir=output_dir_path
output_dir_path would be the path to your output_dir.
一旦 TensorBoard 成功启动,你将看到提示让你打开如下 url COMPUTER_NAME:6006
![640]()
将 URL 地址输入到浏览器中,将显示以下界面。
![640]()
为了可视化你的模式,双击 IMPORT.
仔细看下该模型并记下输入和输出节点的名字(框架中的第一个和最后一个)。
如果你的命名和我之前代码一样的话,他们就应该是 input_1 和output_1 。
到这一步, 我们的模型就可以调用了。
将 TensorFlow Mobile 添加到你的项目中
TensorFlow 有 2 个针对移动设备的库,分别是「TensorFlow Mobile」和「TensorFlow Lite.」Lite 版本设计得非常小,所有的依赖库大约只有 1M。它的模型也更优化。另外,在安卓 8 以上的设备中,还可以用神经网络 API 加速。与「TensorFlow Mobile」不同,「TensorFlow Lite.」目前还不太完善,有些层并不能实现预期的效果。此外,windows 系统还不支持编译库和将模式转成原生格式的操作。因此,在这个教程里,我坚持用 TensorFlow Mobile。
如果没有现存项目的话,使用 Android Studio,创建一个新的安卓项目。然后添加TensorFlow Mobile 依赖库到你的build.gradle 文件。
implementation ‘org.tensorflow:tensorflow-android:+’
Android studio 将提示你同步 gradle,点击 Sync Now 等待同步完成。
到这一步项目就创建完成了。
在你的移动 App 上执行推理
在用代码执行推理前,你需要将转化的模式 (squeezenet.pb) 添加到你的应用的资源文件夹里。
在 Android Studio 中右击你的项目,鼠标移到「添加文件夹」选项,然后选择「资源文件夹」。这时会在你的 app 目录下创建一个资源文件夹。然后,拷贝你的模式到此目录下。
点击 here 下载标签类,并拷贝文件到资源目录。
现在你的项目包含了分类图像的所有工具。
添加一个新的 Java 类到你的项目的主包中,取名为 ImageUtils , 然后将以下代码拷贝到其中。
package com.specpal.mobileai;
import android.content.res.AssetManager;
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.Matrix;
import android.os.Environment;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import org.json.*;
/**
* Utility class for manipulating images.
**/
public class ImageUtils {
/**
* Returns a transformation matrix from one reference frame into another.
* Handles cropping (if maintaining aspect ratio is desired) and rotation.
*
* @param srcWidth Width of source frame.
* @param srcHeight Height of source frame.
* @param dstWidth Width of destination frame.
* @param dstHeight Height of destination frame.
* @param applyRotation Amount of rotation to apply from one frame to another.
* Must be a multiple of 90.
* @param maintainAspectRatio If true, will ensure that scaling in x and y remains constant,
* cropping the image if necessary.
* @return The transformation fulfilling the desired requirements.
*/
public static Matrix getTransformationMatrix(
final int srcWidth,
final int srcHeight,
final int dstWidth,
final int dstHeight,
final int applyRotation,
final boolean maintainAspectRatio) {
final Matrix matrix = new Matrix();
if (applyRotation != 0) {
// Translate so center of image is at origin.
matrix.postTranslate(-srcWidth / 2.0f, -srcHeight / 2.0f);
// Rotate around origin.
matrix.postRotate(applyRotation);
}
// Account for the already applied rotation, if any, and then determine how
// much scaling is needed for each axis.
final boolean transpose = (Math.abs(applyRotation) + 90) % 180 == 0;
final int inWidth = transpose ? srcHeight : srcWidth;
final int inHeight = transpose ? srcWidth : srcHeight;
// Apply scaling if necessary.
if (inWidth != dstWidth || inHeight != dstHeight) {
final float scaleFactorX = dstWidth / (float) inWidth;
final float scaleFactorY = dstHeight / (float) inHeight;
if (maintainAspectRatio) {
// Scale by minimum factor so that dst is filled completely while
// maintaining the aspect ratio. Some image may fall off the edge.
final float scaleFactor = Math.max(scaleFactorX, scaleFactorY);
matrix.postScale(scaleFactor, scaleFactor);
} else {
// Scale exactly to fill dst from src.
matrix.postScale(scaleFactorX, scaleFactorY);
}
}
if (applyRotation != 0) {
// Translate back from origin centered reference to destination frame.
matrix.postTranslate(dstWidth / 2.0f, dstHeight / 2.0f);
}
return matrix;
}
public static Bitmap processBitmap(Bitmap source,int size){
int image_height = source.getHeight();
int image_width = source.getWidth();
Bitmap croppedBitmap = Bitmap.createBitmap(size, size, Bitmap.Config.ARGB_8888);
Matrix frameToCropTransformations = getTransformationMatrix(image_width,image_height,size,size,0,false);
Matrix cropToFrameTransformations = new Matrix();
frameToCropTransformations.invert(cropToFrameTransformations);
final Canvas canvas = new Canvas(croppedBitmap);
canvas.drawBitmap(source, frameToCropTransformations, );
return croppedBitmap;
}
public static float[] normalizeBitmap(Bitmap source,int size,float mean,float std){
float[] output = new float[size * size * 3];
int[] intValues = new int[source.getHeight() * source.getWidth()];
source.getPixels(intValues, 0, source.getWidth(), 0, 0, source.getWidth(), source.getHeight());
for (int i = 0; i < intValues.length; ++i) {
final int val = intValues[i];
output[i * 3] = (((val >> 16) & 0xFF) - mean)/std;
output[i * 3 + 1] = (((val >> 8) & 0xFF) - mean)/std;
output[i * 3 + 2] = ((val & 0xFF) - mean)/std;
}
return output;
}
public static Object[] argmax(float[] array){
int best = -1;
float best_confidence = 0.0f;
for(int i = 0;i < array.length;i++){
float value = array[i];
if (value > best_confidence){
best_confidence = value;
best = i;
}
}
return new Object[]{best,best_confidence};
}
public static String getLabel( InputStream jsonStream,int index){
String label = "";
try {
byte[] jsonData = new byte[jsonStream.available()];
jsonStream.read(jsonData);
jsonStream.close();
String jsonString = new String(jsonData,"utf-8");
JSONObject object = new JSONObject(jsonString);
label = object.getString(String.valueOf(index));
}
catch (Exception e){
}
return label;
}
}
如果不理解上面的代码也没关系,这是一些未在核心 TensorFlow-Mobile 库中实现的功能。因此,在参考了一些官方样例后,我写了这些代码以方便后续工作。
在你的主活动中,创建一个 ImageView 和一个 TextView ,这将被用来显示图像和其预测结果。
在你的主活动中,你需要加载 TensorFlow-inference 库和初始化一些类变量。在你的 onCreate 方法前添加以下内容:
//Load the tensorflow inference library
static {
System.loadLibrary("tensorflow_inference");
}
//PATH TO OUR MODEL FILE AND NAMES OF THE INPUT AND OUTPUT NODES
private String MODEL_PATH = "file:///android_asset/squeezenet.pb";
private String INPUT_NAME = "input_1";
private String OUTPUT_NAME = "output_1";
private TensorFlowInferenceInterface tf;
//ARRAY TO HOLD THE PREDICTIONS AND FLOAT VALUES TO HOLD THE IMAGE DATA
float[] PREDICTIONS = new float[1000];
private float[] floatValues;
private int[] INPUT_SIZE = {224,224,3};
ImageView imageView;
TextView resultView;
Snackbar progressBar;
添加一个计算预测类的函数:
//FUNCTION TO COMPUTE THE MAXIMUM PREDICTION AND ITS CONFIDENCE
public Object[] argmax(float[] array){
int best = -1;
float best_confidence = 0.0f;
for(int i = 0;i < array.length;i++){
float value = array[i];
if (value > best_confidence){
best_confidence = value;
best = i;
}
}
return new Object[]{best,best_confidence};
}
添加函数来接收 Image Bitmap 并在其上执行推理:
public void predict(final Bitmap bitmap){
//Runs inference in background thread
new AsyncTask(){
@Override
protected Integer doInBackground(Integer ...params){
//Resize the image into 224 x 224
Bitmap resized_image = ImageUtils.processBitmap(bitmap,224);
//Normalize the pixels
floatValues = ImageUtils.normalizeBitmap(resized_image,224,127.5f,1.0f);
//Pass input into the tensorflow
tf.feed(INPUT_NAME,floatValues,1,224,224,3);
//compute predictions
tf.run(new String[]{OUTPUT_NAME});
//copy the output into the PREDICTIONS array
tf.fetch(OUTPUT_NAME,PREDICTIONS);
//Obtained highest prediction
Object[] results = argmax(PREDICTIONS);
int class_index = (Integer) results[0];
float confidence = (Float) results[1];
try{
final String conf = String.valueOf(confidence * 100).substring(0,5);
//Convert predicted class index into actual label name
final String label = ImageUtils.getLabel(getAssets().open("labels.json"),class_index);
//Display result on UI
runOnUiThread(new Runnable() {
@Override
public void run() {
progressBar.dismiss();
resultView.setText(label + " : " + conf + "%");
}
});
}
catch (Exception e){
}
return 0;
}
}.execute(0);
}
以上代码在后台线程中运行预测,并将预测的类和它的评估得分写到我们之前定义的 TextView 中。
注意在主 UI 线程运行推理时可能会挂起。记住一个原则 :“永远在你的后台线程运行推理!”
本教程的重点是图像识别,为此我在资源文件夹中添加了一只小鸟的图像。在标准应用程序中,你要用代码从文件系统加载图像。
添加任何你想做预测的图像到资源文件夹中。为了方便的运行算法,在下列的代码中,我们在一个按钮上添加了一个点击监听。该监听可以加载该图像并调用预测功能。
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Toolbar toolbar = (Toolbar) findViewById(R.id.toolbar);
setSupportActionBar(toolbar);
//initialize tensorflow with the AssetManager and the Model
tf = new TensorFlowInferenceInterface(getAssets(),MODEL_PATH);
imageView = (ImageView) findViewById(R.id.imageview);
resultView = (TextView) findViewById(R.id.results);
progressBar = Snackbar.make(imageView,"PROCESSING IMAGE",Snackbar.LENGTH_INDEFINITE);
final FloatingActionButton predict = (FloatingActionButton) findViewById(R.id.predict);
predict.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
try{
//READ THE IMAGE FROM ASSETS FOLDER
InputStream imageStream = getAssets().open("testimage.jpg");
Bitmap bitmap = BitmapFactory.decodeStream(imageStream);
imageView.setImageBitmap(bitmap);
progressBar.show();
predict(bitmap);
}
catch (Exception e){
}
}
});
}
很好!所有步骤都已完成!双击检验一下,如果都没有问题。点击「Bulid APK.」按钮
APK很快就创建完成了,之后在设备上安装并运行App.
结果如下图所示:
![640]()
为了得到更新奇的体验,你的 App 应当从安卓文件系统加载图像或用摄像头抓取图像,而不是从资源文件夹加载。
总结
移动端的深度学习框架将最终转变我们开发和使用 app 的方式。使用上述代码,你能轻松导出你训练的 PyTorch 和 Keras 模型到 TensorFlow。运用 TensorFlow Mobile 和这篇文章中介绍的步骤,你可以将卓越的 AI 功能完美的植入到你的移动端应用中。
安卓项目的完整代码和模型转换工具在我的 GitHub 上可以找到:
https://github.com/johnolafenwa/Pytorch-Keras-ToAndroid



























 =>
=> 





















































