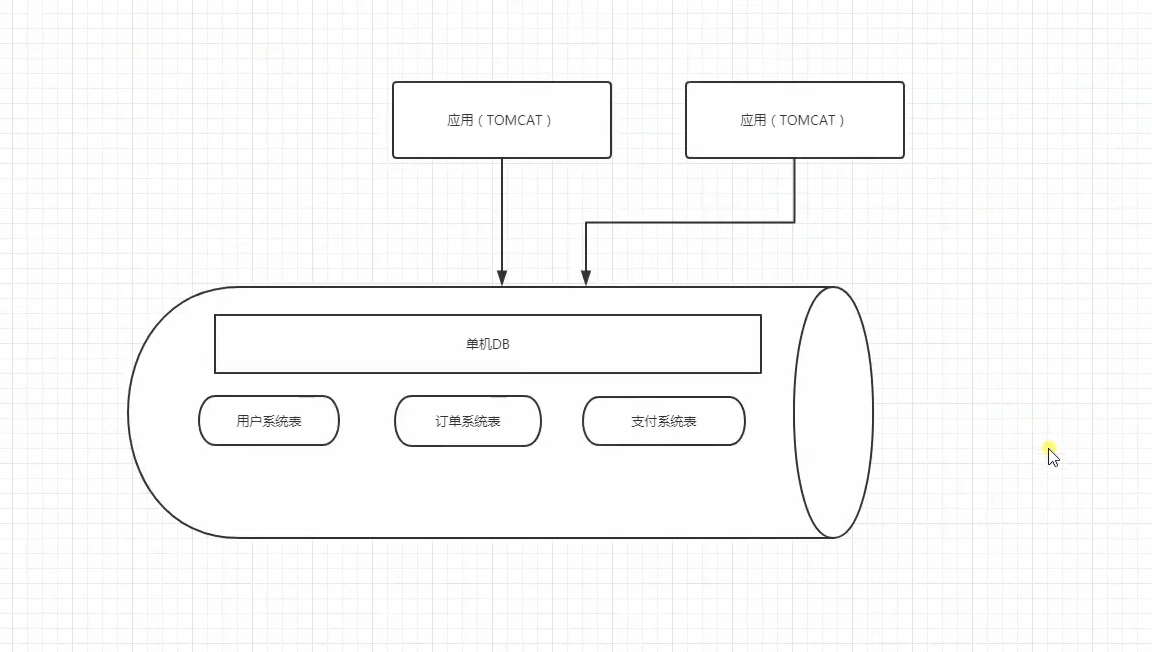
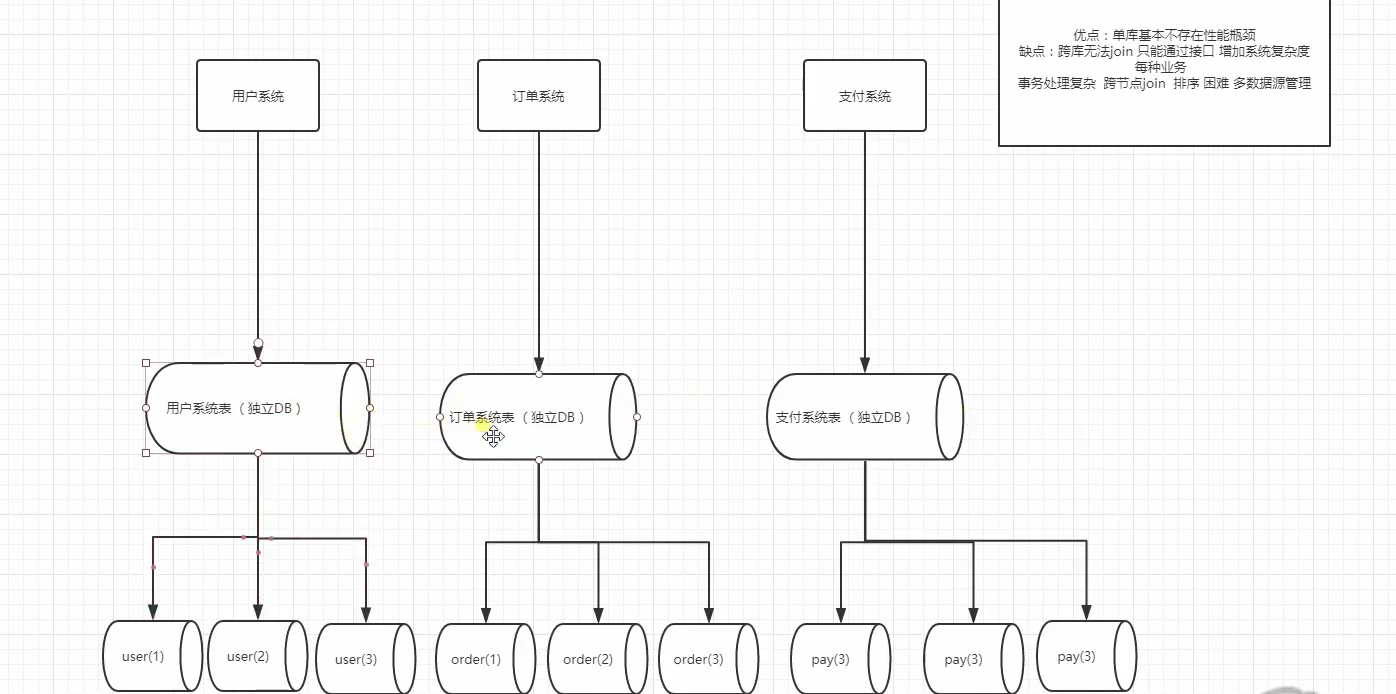
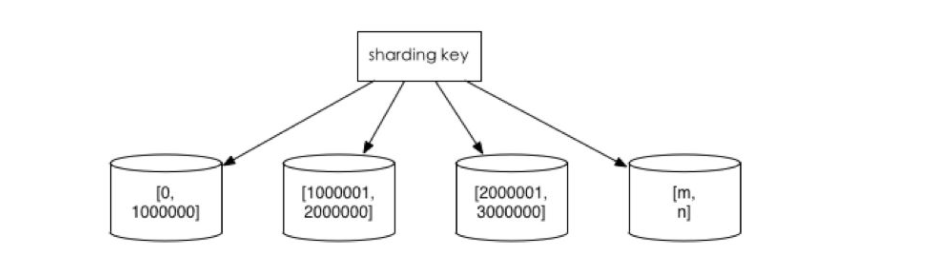
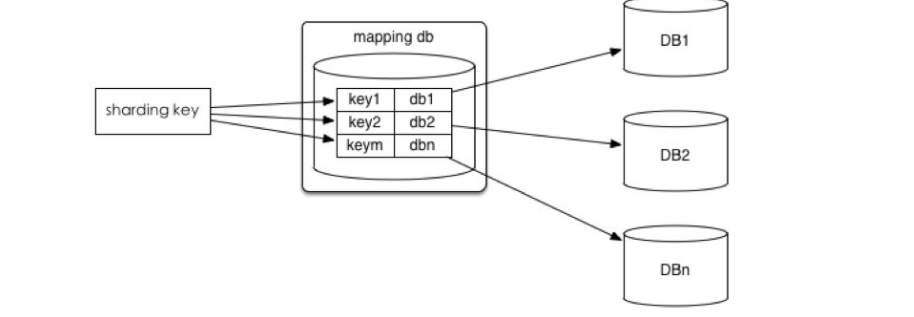
在企业中,数据库高可用一直是企业的重中之重,中小企业很多都是使用mysql主从方案,一主多从,读写分离等,但是单主存在单点故障,从库切换成主库需要作改动。因此,如果是双主或者多主,就会增加mysql入口,增加高可用。不过多主需要考虑自增长ID问题,这个需要特别设置配置文件,比如双主,可以使用奇偶,总之,主之间设置自增长ID相互不冲突就能完美解决自增长ID冲突问题。
主从同步复制原理
在开始之前,我们先来了解主从同步复制原理。
复制分成三步:
1. master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
2. slave将master的binary log events拷贝到它的中继日志(relay log);
3. slave重做中继日志中的事件,将改变反映它自己的数据。
下图描述了这一过程:

该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。
MySQL5.6以前的版本复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。 MySQL5.6版本参数slave-parallel-workers=1 表示启用多线程功能。
MySQL5.6开始,增加了一个新特性,是加入了全局事务 ID (GTID) 来强化数据库的主备一致性,故障恢复,以及容错能力。
官方文档: http://dev.mysql.com/doc/refman/5.6/en/replication-gtids.html
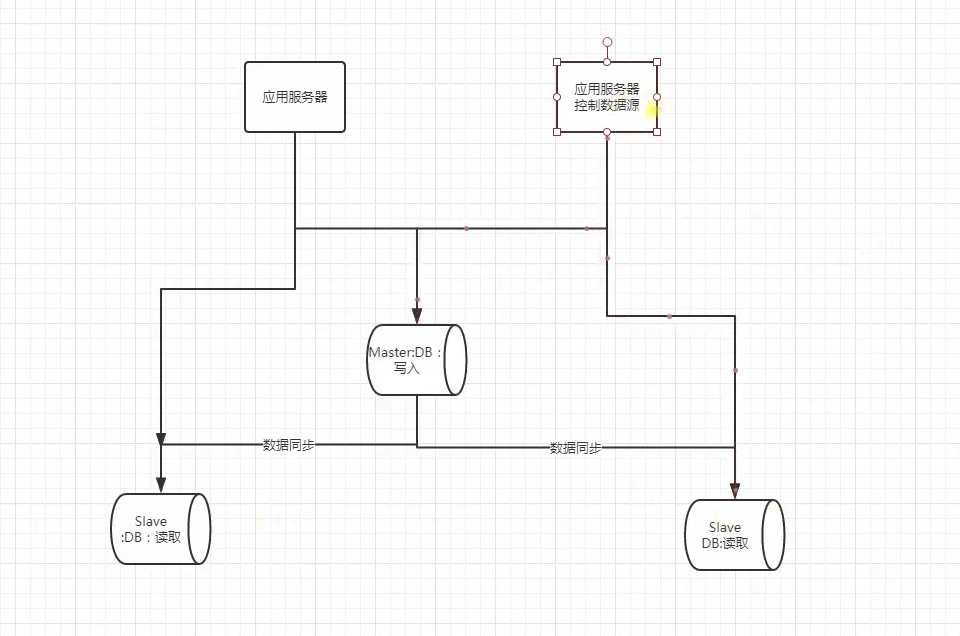
MySQL双主(主主)架构方案思路是:
1.两台mysql都可读写,互为主备,默认只使用一台(masterA)负责数据的写入,另一台(masterB)备用;
2.masterA是masterB的主库,masterB又是masterA的主库,它们互为主从;
3.两台主库之间做高可用,可以采用keepalived等方案(使用VIP对外提供服务);
4.所有提供服务的从服务器与masterB进行主从同步(双主多从);
5.建议采用高可用策略的时候,masterA或masterB均不因宕机恢复后而抢占VIP(非抢占模式);
这样做可以在一定程度上保证主库的高可用,在一台主库down掉之后,可以在极短的时间内切换到另一台主库上(尽可能减少主库宕机对业务造成的影响),减少了主从同步给线上主库带来的压力;
但是也有几个不足的地方:
1.masterB可能会一直处于空闲状态(可以用它当从库,负责部分查询);
2.主库后面提供服务的从库要等masterB先同步完了数据后才能去masterB上去同步数据,这样可能会造成一定程度的同步延时;
架构的简易图如下:

主主环境(这里只介绍2台主的配置方案):
1.CentOS 6.8 64位 2台:masterA(192.168.10.11),masterB(192.168.10.12)
2.官方Mysql5.6版本
搭建过程:
1.安装MySQL服务(建议源码安装)
1.1 yum安装依赖包
yum-yinstallmakegccgcc-c++ ncurses-devel bison openssl-devel
1.2 添加MySQL所需要的用户和组
groupadd -g27mysql adduser-u27-g mysql -s /sbin/nologin mysql
1.3 下载MySQL源码包
mkdir-p /data/packages/src cd/data/packages/wgethttp://distfiles.macports.org/cmake/cmake-3.2.3.tar.gzwgethttp://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.34.tar.gz
1.4 创建mysql数据目录
mkdir-p /usr/local/mysql/data
1.5 解压编译安装cmake、MySQL
cd /data/packages/srctar-zxvf ../cmake-3.2.3.tar.gz cd cmake-3.2.3/./bootstrap gmakemakeinstall
cd ../tarxf mysql-5.6.34.tar.gz cd mysql-5.6.34cmake .-DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DSYSCONFDIR=/etc \-DWITH_SSL=bundled -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci \-DWITH_INNOBASE_STORAGE_ENGINE=1-DWITH_MYISAM_STORAGE_ENGINE=1\-DMYSQL_TCP_PORT=3306-DMYSQL_UNIX_ADDR=/tmp/mysql.sock \-DMYSQL_DATADIR=/usr/local/mysql/datamake&&makeinstall
1.6 添加开机启动脚本
cpsupport-files/mysql.server /etc/rc.d/init.d/mysqld
1.7 添加masterA配置文件/etc/my.cnf
[client] port=3306socket= /tmp/mysql.sock [mysqld] basedir= /usr/local/mysql port=3306socket= /tmp/mysql.sock datadir= /usr/local/mysql/data pid-file= /usr/local/mysql/data/mysql.pid log-error = /usr/local/mysql/data/mysql.err server-id=1auto_increment_offset=1auto_increment_increment=2#奇数ID log-bin = mysql-bin #打开二进制功能,MASTER主服务器必须打开此项 binlog-format=ROW binlog-row-p_w_picpath=minimal log-slave-updates=truegtid-mode=on enforce-gtid-consistency=truemaster-info-repository=TABLE relay-log-info-repository=TABLEsync-master-info=1slave-parallel-workers=0sync_binlog=0binlog-checksum=CRC32 master-verify-checksum=1slave-sql-verify-checksum=1binlog-rows-query-log_events=1#expire_logs_days=5max_binlog_size=1024M #binlog单文件最大值 replicate-ignore-db =mysql #忽略不同步主从的数据库 replicate-ignore-db =information_schema replicate-ignore-db =performance_schema replicate-ignore-db =test replicate-ignore-db =zabbix max_connections=3000max_connect_errors=30skip-character-set-client-handshake #忽略应用程序想要设置的其他字符集 init-connect='SET NAMES utf8'#连接时执行的SQL character-set-server=utf8 #服务端默认字符集 wait_timeout=1800#请求的最大连接时间 interactive_timeout=1800#和上一参数同时修改才会生效 sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES #sql模式 max_allowed_packet=10M bulk_insert_buffer_size=8M query_cache_type=1query_cache_size=128M query_cache_limit=4M key_buffer_size=256M read_buffer_size=16K skip-name-resolve slow_query_log=1long_query_time=6slow_query_log_file=slow-query.log innodb_flush_log_at_trx_commit=2innodb_log_buffer_size=16M [mysql] no-auto-rehash [myisamchk] key_buffer_size=20M sort_buffer_size=20M read_buffer=2M write_buffer=2M [mysqlhotcopy] interactive-timeout [mysqldump] quick max_allowed_packet=16M [mysqld_safe]
1.8 特别参数说明
log-slave-updates =true#将复制事件写入binlog,一台服务器既做主库又做从库此选项必须要开启
#masterA自增长ID auto_increment_offset=1auto_increment_increment=2#奇数ID
#masterB自增加ID auto_increment_offset=2auto_increment_increment=2#偶数ID
1.9 添加masterB配置文件/etc/my.cnf
[client] port=3306socket= /tmp/mysql.sock [mysqld] basedir= /usr/local/mysql port=3306socket= /tmp/mysql.sock datadir= /usr/local/mysql/data pid-file= /usr/local/mysql/data/mysql.pid log-error = /usr/local/mysql/data/mysql.err server-id=2auto_increment_offset=2auto_increment_increment=2#偶数ID log-bin = mysql-bin #打开二进制功能,MASTER主服务器必须打开此项 binlog-format=ROW binlog-row-p_w_picpath=minimal log-slave-updates=truegtid-mode=on enforce-gtid-consistency=truemaster-info-repository=TABLE relay-log-info-repository=TABLEsync-master-info=1slave-parallel-workers=0sync_binlog=0binlog-checksum=CRC32 master-verify-checksum=1slave-sql-verify-checksum=1binlog-rows-query-log_events=1#expire_logs_days=5max_binlog_size=1024M #binlog单文件最大值 replicate-ignore-db =mysql #忽略不同步主从的数据库 replicate-ignore-db =information_schema replicate-ignore-db =performance_schema replicate-ignore-db =test replicate-ignore-db =zabbix max_connections=3000max_connect_errors=30skip-character-set-client-handshake #忽略应用程序想要设置的其他字符集 init-connect='SET NAMES utf8'#连接时执行的SQL character-set-server=utf8 #服务端默认字符集 wait_timeout=1800#请求的最大连接时间 interactive_timeout=1800#和上一参数同时修改才会生效 sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES #sql模式 max_allowed_packet=10M bulk_insert_buffer_size=8M query_cache_type=1query_cache_size=128M query_cache_limit=4M key_buffer_size=256M read_buffer_size=16K skip-name-resolve slow_query_log=1long_query_time=6slow_query_log_file=slow-query.log innodb_flush_log_at_trx_commit=2innodb_log_buffer_size=16M [mysql] no-auto-rehash [myisamchk] key_buffer_size=20M sort_buffer_size=20M read_buffer=2M write_buffer=2M [mysqlhotcopy] interactive-timeout [mysqldump] quick max_allowed_packet=16M [mysqld_safe]
1.10 初始化MySQL
cd /usr/local/mysql scripts/mysql_install_db --user=mysql
1.11 为启动脚本赋予可执行权限并启动MySQL
chmod+x /etc/rc.d/init.d/mysqld/etc/init.d/mysqld start
2. 配置主从同步
2.1 添加主从同步账户
masterA上:
mysql>grantreplicationslaveon*.*to'repl'@'192.168.10.12'identifiedby'123456'; mysql>flushprivileges;
masterB上:
mysql>grantreplicationslaveon*.*to'repl'@'192.168.10.11'identifiedby'123456'; mysql>flushprivileges;
2.2 查看主库的状态
masterA上:
mysql>show master status;+------------------+----------+--------------+------------------+-------------------+|File|Position|Binlog_Do_DB|Binlog_Ignore_DB|Executed_Gtid_Set|+------------------+----------+--------------+------------------+-------------------+|mysql-bin.000003|120||||+------------------+----------+--------------+------------------+-------------------+1rowinset(0.00sec)
masterB上
mysql>show master status;+------------------+----------+--------------+------------------+-------------------+|File|Position|Binlog_Do_DB|Binlog_Ignore_DB|Executed_Gtid_Set|+------------------+----------+--------------+------------------+-------------------+|mysql-bin.000003|437||||+------------------+----------+--------------+------------------+-------------------+1rowinset(0.00sec)
2.3 配置同步信息:
masterA上:
mysql>change mastertomaster_host='192.168.10.12',master_port=3306,master_user='repl',master_password='123456',master_log_file='mysql-bin.000003',master_log_pos=437; mysql>start slave; mysql>show slave status\G;
显示有如下状态则正常:
Slave_IO_Running: Yes Slave_SQL_Running: Yes
masterB上:
#本人是测试环境,可以保证没数据写入,否则需要的步骤是:先masterA锁表-->masterA备份数据-->masterA解锁表 -->masterB导入数据-->masterB设置主从-->查看主从
mysql>change mastertomaster_host='192.168.10.11',master_port=3306,master_user='repl',master_password='123456',master_log_file='mysql-bin.000003',master_log_pos=120; start slave; mysql>show slave status\G;
显示有如下状态则正常:
Slave_IO_Running: Yes Slave_SQL_Running: Yes
3.测试主从同步
3.1 在masterA上创建一个数据库测试同步效果
mysql>show databases;+--------------------+|Database|+--------------------+|information_schema||mysql||performance_schema||test|+--------------------+4rowsinset(0.00sec) mysql>createdatabasetest01; Query OK,1row affected (0.00sec) mysql>show databases;+--------------------+|Database|+--------------------+|information_schema||mysql||performance_schema||test||test01|+--------------------+5rowsinset(0.00sec) mysql>quit Bye[root@masterA data]#
3.2 到masterB查看是否已经同步创建数据库
mysql>show databases;+--------------------+|Database|+--------------------+|information_schema||mysql||performance_schema||test||test01|+--------------------+5rowsinset(0.00sec) mysql>quit Bye[root@masterB data]#
4. 开启MySQL5.6的GTID功能
masterA和masterB分别执行如下命令:
mysql>stop slave; Query OK,0rows affected (0.00sec) mysql>change mastertoMASTER_AUTO_POSITION=1; Query OK,0rows affected (0.01sec) mysql>start slave; Query OK,0rows affected (0.00sec)
5. 遇到的问题
一种主从报错折腾了我半天:
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not open log file'
后面修改主从同步相关 参数,确认原因是my.cnf增加了如下参数:
log-bin = mysql-bin
relay-log = mysql-bin

从正常主主同步时的二进制日志文件显示,有2套二进制日志。因此推断上面2个参数导致不能产生2套二进制文件,故导致二进制文件错乱和丢失。