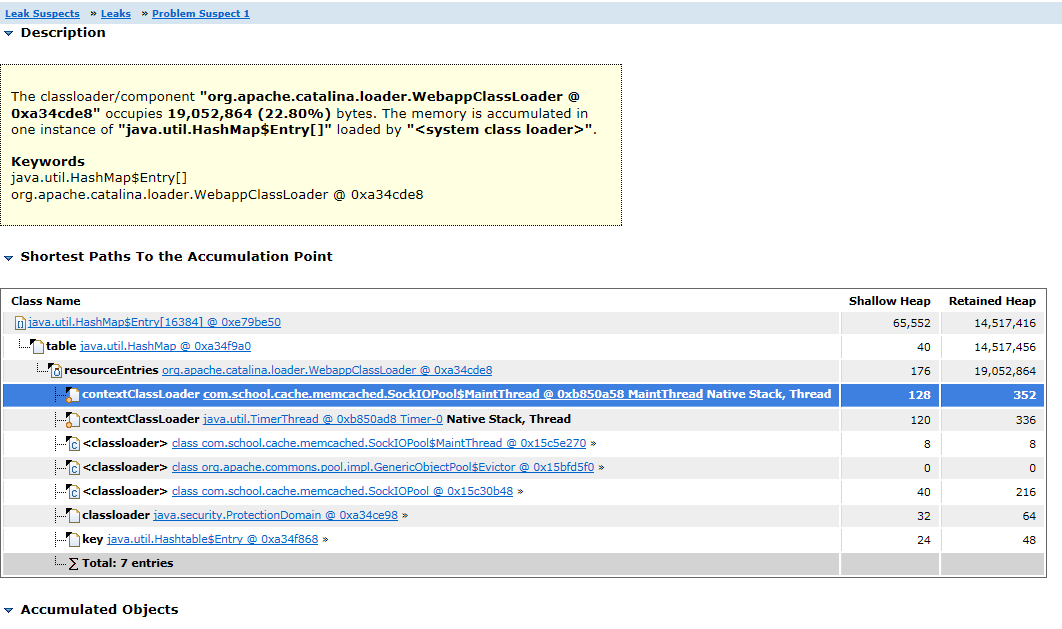
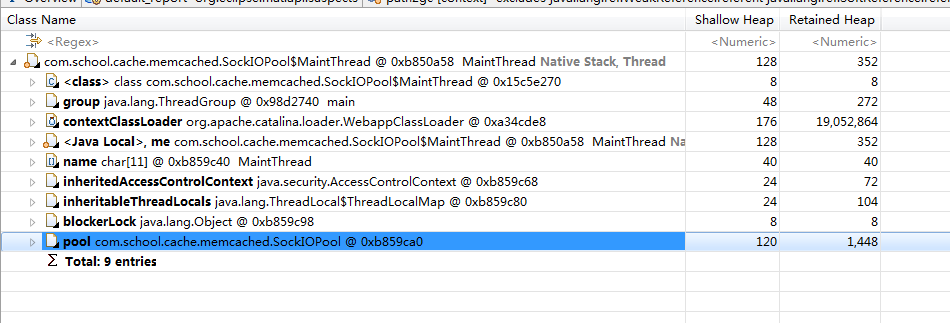
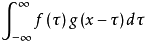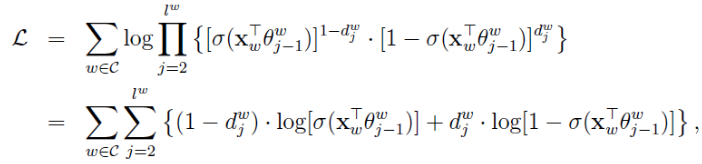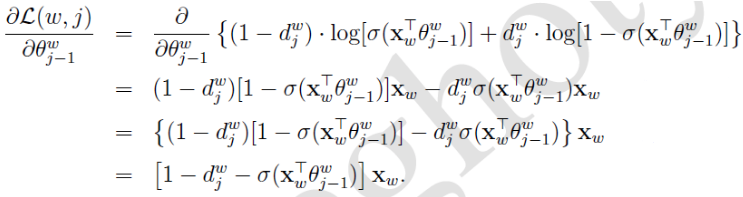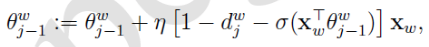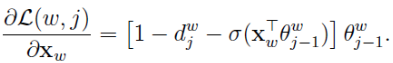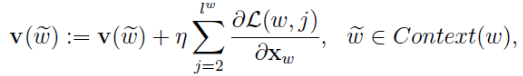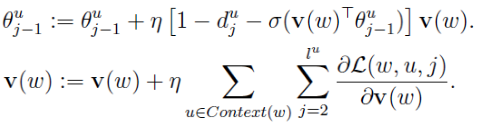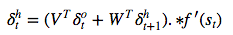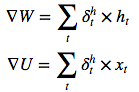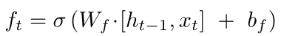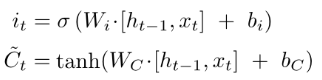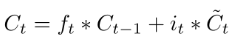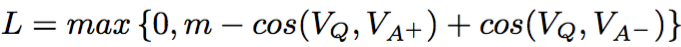原文
涉及知识 人工智能一直以来是人类的梦想,造一台可以为你做一切事情并且有情感的机器人,像哆啦A梦一样,现在这已经不是一个梦了:iPhone里会说话的siri、会下棋的阿法狗、小度机器人、大白……,他们都能够具有智能,和人类交互,帮人类解决问题,这听起来非常神奇,实际上我们自己也可以做一个这样的机器人,从今天开始分享我将我学习和制作的过程
智能机器人可以做到的事情可以很复杂:文字、语音、视频识别与合成;自然语言理解、人机对话;以及驱动硬件设备形成的“机器”人。作为一个只有技术和时间而没有金钱的IT人士,我仅做自然语言和人工智能相关的内容,不涉及硬件,也不涉及不擅长的多媒体识别和合成。所以索性就做一个可以和你说话,帮你解决问题的聊天机器人吧。
聊天机器人涉及到的知识主要是自然语言处理,当然这包括了:语言分析和理解、语言生成、机器学习、人机对话、信息检索、信息传输与信息存储、文本分类、自动文摘、数学方法、语言资源、系统评测等内容,同时少不了的是支撑着一切的编程技术
在我的桌上摆了很多有关自然语言处理、机器学习、深度学习、数学等方面的书籍,为了和大家分享我的经历、学到的知识和每一阶段的成果,我每天会花两个小时以上时间或翻书或总结或编码或整理或写文章,或许文章几天才能更新一篇,但我希望每一篇都是有价值的,或许文章里的知识讲解的不是非常深入,但我希望可以为你指明方向,对于晦涩难懂的内容,我尽量用简朴幽默的方式说出来,目的就是让每一位读者都能有收获,并朝着我们的目标一起前进。
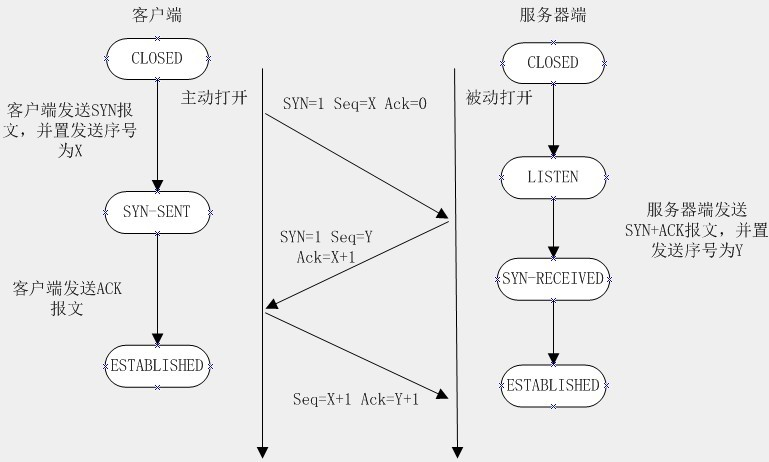
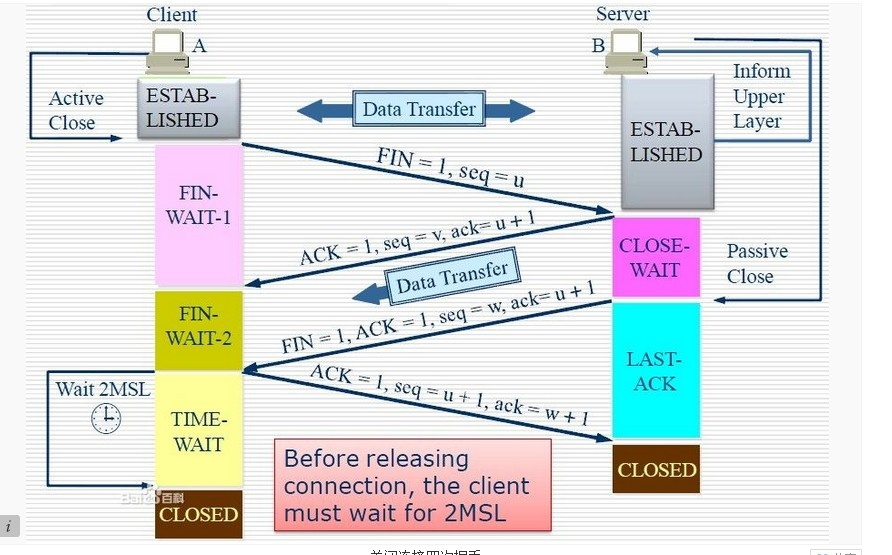
初识NLTK库 安装和使用 安装
下载数据
1
2
import nltk
nltk.download()
选择book下载,下载较慢,推荐找网络资源。
使用
你会看到可以正常加载书籍如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
这里面的text*都是一个一个的书籍节点,直接输入text1会输出书籍标题:
1
<Text: Moby Dick by Herman Melville 1851>
搜索文本 执行
1
text1.concordance("former" )
会显示20个包含former的语句上下文
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Displaying 20 of 20 matches:
s of the sea , appeared . Among the former , one was of a most monstrous size
ce , borrowed from the chaplain ' s former sea - farings . Between the marble
s him with a fresh lance , when the former one has been badly twisted , or elb
, though smaller than those of the former order , nevertheless retain a propo
fficial is still retained , but his former dignity is sadly abridged . At pres
tested reality of his might had in former legendary times thrown its shadow b
g associated with the experience of former perils ; for what knows he , this N
ns and places in which , on various former voyages of various ships , sperm wh
. So that though Moby Dick had in a former year been seen , for example , on w
ed by the defection of seven of his former associates , and stung by the mocki
no part in the mutiny , he told the former that he had a good mind to flog the
so for ever got the start of their former captain , had he been at all minded
head is cut off whole , but in the former the lips and tongue are separately
nd the right . While the ear of the former has an external opening , that of t
in small detached companies , as in former times , are now frequently met with
ence on the coast of Greenland , in former times , of a Dutch village called S
x months before he wheeled out of a former equinox at Aries ! From storm to st
Sperm Whale , for example , that in former years ( the latter part of the last
les no longer haunt many grounds in former years abounding with them , hence t
ering was but the direct issue of a former woe ; and he too plainly seemed to
我们还可以搜索相关词,比如:
1
2
whale boat sea captain world way head time crew man other pequod line
deck body fishery air boats side voyage
输入了ship,查找了boat,都是近义词
我们还可以查看某个词在文章里出现的位置:
1
text4.dispersion_plot(["citizens" ,"democracy" ,"freedom" ,"duties" ,"America" ])
词统计 len(text1):返回总字数
set(text1):返回文本的所有词集合
len(set(text4)):返回文本总词数
text4.count(“is”):返回“is”这个词出现的总次数
FreqDist(text1):统计文章的词频并按从大到小排序存到一个列表里
fdist1 = FreqDist(text1);fdist1.plot(50, cumulative=True):统计词频,并输出累计图像
纵轴表示累加了横轴里的词之后总词数是多少,这样看来,这些词加起来几乎达到了文章的总词数
fdist1.hapaxes():返回只出现一次的词
text4.collocations():频繁的双联词
自然语言处理关键点 词意理解:中国队大胜美国队;中国队大败美国队。“胜”、“败”一对反义词,却表达同样的意思:中国赢了,美国输了。这需要机器能够自动分析出谁胜谁负
自动生成语言:自动生成语言基于语言的自动理解,不理解就无法自动生成
机器翻译:现在机器翻译已经很多了,但是还很难达到最佳,比如我们把中文翻译成英文,再翻译成中文,再翻译成英文,来回10轮,发现和最初差别还是非常大的。
人机对话:这也是我们想做到的最终目标,这里有一个叫做“图灵测试”的方式,也就是在5分钟之内回答提出问题的30%即通过,能通过则认为有智能了。
自然语言处理分两派,一派是基于规则的,也就是完全从语法句法等出发,按照语言的规则来分析和处理,这在上个世纪经历了很多年的试验宣告失败,因为规则太多太多,而且很多语言都不按套路出牌,想象你追赶你的影子,你跑的快他跑的更快,你永远都追不上它。另一派是基于统计的,也就是收集大量的语料数据,通过统计学习的方式来理解语言,这在当代越来越受重视而且已经成为趋势,因为随着硬件技术的发展,大数据存储和计算已经不是问题,无论有什么样的规则,语言都是有统计规律的,当然基于统计也存在缺陷,那就是“小概率事件总是不会发生的”导致总有一些问题解决不了。
下一节我们就基于统计的方案来解决语料的问题。
语料与词汇资源 当代自然语言处理都是基于统计的,统计自然需要很多样本,因此语料和词汇资源是必不可少的,本节介绍语料和词汇资源的重要性和获取方式
NLTK语料库 NLTK包含多种语料库,举一个例子:Gutenberg语料库,执行:
1
2
import nltk
nltk.corpus.gutenberg.fileids()
返回Gutenberg语料库的文件标识符
1
[u'austen-emma.txt', u'austen-persuasion.txt', u'austen-sense.txt', u'bible-kjv.txt', u'blake-poems.txt', u'bryant-stories.txt', u'burgess-busterbrown.txt', u'carroll-alice.txt', u'chesterton-ball.txt', u'chesterton-brown.txt', u'chesterton-thursday.txt', u'edgeworth-parents.txt', u'melville-moby_dick.txt', u'milton-paradise.txt', u'shakespeare-caesar.txt', u'shakespeare-hamlet.txt', u'shakespeare-macbeth.txt', u'whitman-leaves.txt']
nltk.corpus.gutenberg就是gutenberg语料库的阅读器,它有很多实用的方法,比如:
nltk.corpus.gutenberg.raw('chesterton-brown.txt'):输出chesterton-brown.txt文章的原始内容
nltk.corpus.gutenberg.words('chesterton-brown.txt'):输出chesterton-brown.txt文章的单词列表
nltk.corpus.gutenberg.sents('chesterton-brown.txt'):输出chesterton-brown.txt文章的句子列表
类似的语料库还有:
from nltk.corpus import webtext:网络文本语料库,网络和聊天文本
from nltk.corpus import brown:布朗语料库,按照文本分类好的500个不同来源的文本
from nltk.corpus import reuters:路透社语料库,1万多个新闻文档
from nltk.corpus import inaugural:就职演说语料库,55个总统的演说
语料库的一般结构 以上各种语料库都是分别建立的,因此会稍有一些区别,但是不外乎以下几种组织结构:散养式(孤立的多篇文章)、分类式(按照类别组织,相互之间没有交集)、交叉式(一篇文章可能属于多个类)、渐变式(语法随着时间发生变化)
语料库的通用接口
fileids():返回语料库中的文件
categories():返回语料库中的分类
raw():返回语料库的原始内容
words():返回语料库中的词汇
sents():返回语料库句子
abspath():指定文件在磁盘上的位置
open():打开语料库的文件流
加载自己的语料库 收集自己的语料文件(文本文件)到某路径下(比如/tmp),然后执行:
1
2
3
4
from nltk.corpus import PlaintextCorpusReader
corpus_root = '/tmp'
wordlists = PlaintextCorpusReader(corpus_root, '.*')
wordlists.fileids()
就可以列出自己语料库的各个文件了,也可以使用如wordlists.sents('a.txt')和wordlists.words('a.txt')等方法来获取句子和词信息
条件频率分布 条件分布大家都比较熟悉了,就是在一定条件下某个事件的概率分布。自然语言的条件频率分布就是指定条件下某个事件的频率分布。
比如要输出在布朗语料库中每个类别条件下每个词的概率:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import nltk
from nltk.corpus import brown
# 链表推导式,genre是brown语料库里的所有类别列表,word是这个类别中的词汇列表
# (genre, word)就是类别加词汇对
genre_word = [(genre, word)
for genre in brown.categories()
for word in brown.words(categories=genre)
]
# 创建条件频率分布
cfd = nltk.ConditionalFreqDist(genre_word)
# 指定条件和样本作图
cfd.plot(conditions=['news','adventure'], samples=[u'stock', u'sunbonnet', u'Elevated', u'narcotic', u'four', u'woods', u'railing', u'Until', u'aggression', u'marching', u'looking', u'eligible', u'electricity', u'$25-a-plate', u'consulate', u'Casey', u'all-county', u'Belgians', u'Western', u'1959-60', u'Duhagon', u'sinking', u'1,119', u'co-operation', u'Famed', u'regional', u'Charitable', u'appropriation', u'yellow', u'uncertain', u'Heights', u'bringing', u'prize', u'Loen', u'Publique', u'wooden', u'Loeb', u'963', u'specialties', u'Sands', u'succession', u'Paul', u'Phyfe'])
注意:这里如果把plot直接换成tabulate ,那么就是输出表格形式,和图像表达的意思相同
我们还可以利用条件频率分布,按照最大条件概率生成双连词,最终生成一个随机文本
这可以直接使用bigrams()函数,它的功能是生成词对链表。
创建python文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import nltk
# 循环10次,从cfdist中取当前单词最大概率的连词,并打印出来
def generate_model(cfdist, word, num=10):
for i in range(num):
print word,
word = cfdist[word].max()
# 加载语料库
text = nltk.corpus.genesis.words('english-kjv.txt')
# 生成双连词
bigrams = nltk.bigrams(text)
# 生成条件频率分布
cfd = nltk.ConditionalFreqDist(bigrams)
# 以the开头,生成随机串
generate_model(cfd, 'the')
执行效果如下:
1
the land of the land of the land of the
the的最大概率的双连词是land,land最大概率双连词是of,of最大概率双连词是the,所以后面就循环了
其他词典资源 有一些仅是词或短语以及一些相关信息的集合,叫做词典资源。
词汇列表语料库:nltk.corpus.words.words(),所有英文单词,这个可以用来识别语法错误
停用词语料库:nltk.corpus.stopwords.words,用来识别那些最频繁出现的没有意义的词
发音词典:nltk.corpus.cmudict.dict(),用来输出每个英文单词的发音
比较词表:nltk.corpus.swadesh,多种语言核心200多个词的对照,可以作为语言翻译的基础
同义词集:WordNet,面向语义的英语词典,由同义词集组成,并组织成一个网络
何须动手?完全自动化对语料做词性标注 全人工对语料做词性标注就像蚂蚁一样忙忙碌碌,是非常耗费声明的,如果有一个机器能够完全自动化地,给它一篇语料,它迅速给你一片标注,这样才甚好,本节就来讨论一下怎么样能无需动手对语料做自动化的词性标注
英文词干提取器
1
2
3
import nltk
porter = nltk.PorterStemmer()
print porter.stem('lying' )
输出lie
词性标注器
1
2
3
import nltk
text = nltk.word_tokenize("And now for something completely different" )
print nltk.pos_tag(text)
1
[('And', 'CC'), ('now', 'RB'), ('for', 'IN'), ('something', 'NN'), ('completely', 'RB'), ('different', 'JJ')]
其中CC是连接词,RB是副词,IN是介词,NN是名次,JJ是形容词
这是一句完整的话,实际上pos_tag是处理一个词序列,会根据句子来动态判断,比如:
1
print nltk.pos_tag(['i' ,'love' ,'you' ])
1
[('i', 'NN'), ('love', 'VBP'), ('you', 'PRP')]`
这里的love识别为动词
而:
1
print nltk.pos_tag(['love','and','hate'])
1
[('love', 'NN'), ('and', 'CC'), ('hate', 'NN')]
这里的love识别为名词
nltk中多数都是英文的词性标注语料库,如果我们想自己标注一批语料库该怎么办呢?
nltk提供了比较方便的方法:
1
2
tagged_token = nltk.tag.str2tuple('fly/NN' )
print tagged_token
这里的nltk.tag.str2tuple可以把fly/NN这种字符串转成一个二元组,事实上nltk的语料库中都是这种字符串形式的标注,那么我们如果把语料库标记成:
1
2
sent ='我/NN 是/IN 一个/AT 大/JJ 傻×/NN'
print [nltk.tag.str2tuple(t)for tin sent.split()]
1
[('\xe6\x88\x91', 'NN'), ('\xe6\x98\xaf', 'IN'), ('\xe4\xb8\x80\xe4\xb8\xaa', 'AT'), ('\xe5\xa4\xa7', 'JJ'), ('\xe5\x82\xbb\xc3\x97', 'NN')]
这么说来,中文也是可以支持的,恩~
我们来看一下布朗语料库中的标注:
1
nltk.corpus.brown.tagged_words()
1
[(u'The', u'AT'), (u'Fulton', u'NP-TL'), ...]
事实上nltk也有中文的语料库,我们来下载下来:
执行nltk.download(),选择Corpora里的sinica_treebank下载
sinica就是台湾话中的中国研究院
我们看一下这个中文语料库里有什么内容,创建cn_tag.py,内容如下:
1
2
3
4
5
6
7
8
9
import sys
reload(sys)
sys.setdefaultencoding("utf-8" )
import nltk
for wordin nltk.corpus.sinica_treebank.tagged_words():
print word[0 ], word[1 ]
执行后输出:
1
2
3
4
5
6
7
8
9
10
11
一 Neu
友情 Nad
嘉珍 Nba
和 Caa
我 Nhaa
住在 VC1
同一條 DM
巷子 Nab
我們 Nhaa
是 V_11
……
第一列是中文的词汇,第二列是标注好的词性
我们发现这里面都是繁体,因为是基于台湾的语料生成的,想要简体中文还得自己想办法。不过有人已经帮我们做了这部分工作,那就是jieba切词,https://github.com/fxsjy/jieba ,强烈推荐,可以自己加载自己的语料,进行中文切词,并且能够自动做词性标注
词性自动标注 面对一片新的语料库(比如我们从未处理过中文,只有一批批的中文语料,现在让我们做词性自动标注),如何实现词性自动标注?有如下几种标注方法:
默认标注器:不管什么词,都标注为频率最高的一种词性。比如经过分析,所有中文语料里的词是名次的概率是13%最大,那么我们的默认标注器就全部标注为名次。这种标注器一般作为其他标注器处理之后的最后一道门,即:不知道是什么词?那么他是名次。默认标注器用DefaultTagger来实现,具体用法如下:
1
2
3
4
5
6
7
8
9
10
11
12
import sys
reload(sys)
sys.setdefaultencoding("utf-8" )
import nltk
default_tagger = nltk.DefaultTagger('NN' )
raw ='我 累 个 去'
tokens = nltk.word_tokenize(raw)
tags = default_tagger.tag(tokens)
print tags
1
[('\xe6\x88\x91', 'NN'), ('\xe7\xb4\xaf', 'NN'), ('\xe4\xb8\xaa', 'NN'), ('\xe5\x8e', 'NN'), ('\xbb', 'NN')]
正则表达式标注器:满足特定正则表达式的认为是某种词性,比如凡是带“们”的都认为是代词(PRO)。正则表达式标注器通RegexpTagge实现,用法如下:
1
2
3
pattern = [(r'.*们$' ,'PRO' )]
tagger = nltk.RegexpTagger(pattern)
print tagger.tag(nltk.word_tokenize('我们 累 个 去 你们 和 他们 啊' ))
1
[('\xe6\x88\x91\xe4', None), ('\xbb', None), ('\xac', None), ('\xe7\xb4\xaf', None), ('\xe4\xb8\xaa', None), ('\xe5\x8e', None), ('\xbb', None), ('\xe4\xbd\xa0\xe4', None), ('\xbb', None), ('\xac', None), ('\xe5\x92\x8c', None), ('\xe4', None), ('\xbb', None), ('\x96\xe4', None), ('\xbb', None), ('\xac', None), ('\xe5\x95\x8a', None)]
查询标注器:找出最频繁的n个词以及它的词性,然后用这个信息去查找语料库,匹配的就标记上,剩余的词使用默认标注器(回退)。这一般使用一元标注的方式,见下面。
一元标注:基于已经标注的语料库做训练,然后用训练好的模型来标注新的语料,使用方法如下:
1
2
3
4
5
6
7
8
import nltk
from nltk.corpusimport brown
tagged_sents = [[(u'我' ,u'PRO' ), (u'小兔' ,u'NN' )]]
unigram_tagger = nltk.UnigramTagger(tagged_sents)
sents = brown.sents(categories='news' )
sents = [[u'我' ,u'你' ,u'小兔' ]]
tags = unigram_tagger.tag(sents[0 ])
print tags
1
[(u'\u6211', u'PRO'), (u'\u4f60', None), (u'\u5c0f\u5154', u'NN')]
这里的tagged_sents是用于训练的语料库,我们也可以直接用已有的标注好的语料库,比如:
1
brown_tagged_sents = brown.tagged_sents(categories='news' )
二元标注和多元标注:一元标注指的是只考虑当前这个词,不考虑上下文。二元标注器指的是考虑它前面的词的标注,用法只需要把上面的UnigramTagger换成BigramTagger。同理三元标注换成TrigramTagger
组合标注器:为了提高精度和覆盖率,我们对多种标注器组合,比如组合二元标注器、一元标注器和默认标注器,如下:
1
2
3
t0 = nltk.DefaultTagger('NN' )
t1 = nltk.UnigramTagger(train_sents, backoff=t0)
t2 = nltk.BigramTagger(train_sents, backoff=t1)
标注器的存储:训练好的标注器为了持久化,可以存储到硬盘,具体方法如下:
1
2
3
4
from cPickleimport dump
output = open('t2.pkl' ,'wb' )
dump(t2, output,-1 )
output.close()
使用时也可以加载,如下:
1
2
3
4
from cPickle import load
input = open('t2.pkl', 'rb')
tagger = load(input)
input.close()
自然语言处理中的文本分类 文本分类是机器学习在自然语言处理中的最常用也是最基础的应用,机器学习相关内容可以直接看我的有关scikit-learn相关教程,本节直接涉及nltk中的机器学习相关内容
先来一段前戏 机器学习的过程是训练模型和使用模型的过程,训练就是基于已知数据做统计学习,使用就是用统计学习好的模型来计算未知的数据。
机器学习分为有监督学习和无监督学习,文本分类也分为有监督的分类和无监督的分类。有监督就是训练的样本数据有了确定的判断,基于这些已有的判断来断定新的数据,无监督就是训练的样本数据没有什么判断,完全自发的生成结论。
无论监督学习还是无监督学习,都是通过某种算法来实现,而这种算法可以有多重选择,贝叶斯就是其中一种。在多种算法中如何选择最适合的,这才是机器学习最难的事情,也是最高境界。
nltk中的贝叶斯分类器 贝叶斯是概率论的鼻祖,贝叶斯定理是关于随机事件的条件概率的一则定理,贝叶斯公式是:
P(B|A)=P(A|B)P(B)/P(A);即,已知P(A|B),P(A)和P(B)可以计算出P(B|A)。
贝叶斯分类器就是基于贝叶斯概率理论设计的分类器算法,nltk库中已经实现,具体用法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import sys
reload(sys)
sys.setdefaultencoding("utf-8" )
import nltk
my_train_set = [
({'feature1' :u'a' },'1' ),
({'feature1' :u'a' },'2' ),
({'feature1' :u'a' },'3' ),
({'feature1' :u'a' },'3' ),
({'feature1' :u'b' },'2' ),
({'feature1' :u'b' },'2' ),
({'feature1' :u'b' },'2' ),
({'feature1' :u'b' },'2' ),
({'feature1' :u'b' },'2' ),
({'feature1' :u'b' },'2' ),
]
classifier = nltk.NaiveBayesClassifier.train(my_train_set)
print classifier.classify({'feature1' :u'a' })
print classifier.classify({'feature1' :u'b' })
执行后判断特征a和特征b的分类分别是3和2
因为训练集中特征是a的分类是3的最多,所以会归类为3
当然实际中训练样本的数量要多的多,特征要多的多
文档分类 不管是什么分类,最重要的是要知道哪些特征是最能反映这个分类的特点,也就是特征选取。文档分类使用的特征就是最能代表这个分类的词。
因为对文档分类要经过训练和预测两个过程,而特征的提取是这两个过程都需要的,所以,习惯上我们会把特征提取单独抽象出来作为一个公共方法,比如:
以下代码有问题*
1
2
3
4
5
6
7
8
9
import nltk
from nltk.corpusimport movie_reviews
all_words = nltk.FreqDist(w.lower()for win movie_reviews.words())
all_words.plot(50 , cumulative=True )
word_features = all_words.keys()[:2000 ]
def document_features (document) :
for wordin word_features:
features['contains(%s)' % word] = (wordin document_words)
return features
这是一个简单的特征提取过程,前两行找到movie_reviews语料库中出现词频最高的2000个词作为特征,下面定义的函数就是特征提取函数,每个特征都是形如contains(***)的key,value就是True或False,表示这个词是否在文档中出现
那么我们训练的过程就是:
1
2
featuresets = [(document_features(d), c)for (d,c)in documents]
classifier = nltk.NaiveBayesClassifier.train(featuresets)
要预测一个新的文档时:
1
classifier.classify(document_features(d))
通过
1
classifier.show_most_informative_features(5)
可以找到最优信息量的特征,这对我们选取特征是非常有帮助的
其他文本分类 文本分类除了文档分类外还有许多其他类型的分类,比如:
词性标注:属于一种文本分类,一般是基于上下文语境的文本分类
句子分割:属于标点符号的分类任务,它的特征一般选取为单独句子标识符的合并链表、数据特征(下一个词是否大写、前一个词是什么、前一个词长度……)
识别对话行为类型:对话行为类型是指问候、问题、回答、断言、说明等
识别文字蕴含:即一个句子是否能得出另外一个句子的结论,这可以认为是真假标签的分类任务。这是一个有挑战的事情
教你怎么从一句话里提取出十句话的信息 按照之前理解的内容,对一句话做处理,最多是切成一个一个的词,再标注上词性,仅此而已,然而事实并非如此,一句话还可以做更多的文章,我们本节见分晓
什么?还能结构化? 任何语言的每一句话之所以称为“话”,是因为它有一定的句子结构,除了一个个独立的词之外,他们之间还存在着某种关系。如果任何一句话可以由任何词构成,可长可短,那么这是一个非结构化的信息,计算机是很难理解并做计算的,但是如果能够以某种方式把句子转化成结构化的形式,计算机就可以理解了。
实事上,人脑在理解一句话的时候也暗暗地在做着由非结构化到结构化的工作。
比如说:“我下午要和小明在公司讨论一个技术问题”。这是一片非结构化的词语拼成的一句话,但是这里面有很多隐含信息:
1)小明是一个实体
2)参与者有两个:我和小明
3)地点设定是:公司
4)要做的事情是:讨论
5)讨论的内容是:问题
6)这个问题是一个技术问题
7)公司是一个地点
8)讨论是一种行为
9)我和小明有某种关系
10)下午是一个时间
上面这些信息有一些是专门针对这个句子的,有一些是常理性的,对于针对句子的信息有利于理解这句话,对于常理性的信息可以积累下来用来以后理解其他句子。
那么怎么才能把非结构化的句子转成结构化的信息呢?要做的工作除了断句、分词、词性标注之外,还要做的一个关键事情就是分块。
分块 分块就是根据句子中的词和词性,按照某种规则组合在一起形成一个个分块,每个分块代表一个实体。常见的实体包括:组织、人员、地点、日期、时间等
以上面的例子为例,首先我们做名词短语分块(NP-chunking),比如:技术问题。名词短语分块通过词性标记和一些规则就可以识别出来,也可以通过机器学习的方法识别
除了名词短语分块还有很多其他分块:介词短语(PP,比如:以我……)、动词短语(VP,比如:打人)、句子(S,我是人)
分块如何标记和存储呢? 可以采用IOB标记,I(inside,内部)、O(outside,外部)、B(begin, 开始),一个块的开始标记为B,块内的标识符序列标注为I,所有其他标识符标注为O
也可以用树结构来存储分块,用树结构可以解决IOB无法标注的另一类分块,那就是多级分块。多级分块就是一句话可以有多重分块方法,比如:我以我的最高权利惩罚你。这里面“最高权利”、“我的最高权利”、“以我的最高权利”是不同类型分块形成一种多级分块,这是无法通过IOB标记的,但是用树结构可以。这也叫做级联分块。具体树结构举个例子:
1
2
3
4
5
6
7
(S
(NP 小明)
(VP
(V 追赶)
(NP
(Det 一只)
(N 兔子))))
这是不是让你想到了语法树?
关系抽取 通过上面的分块可以很容易识别出实体,那么关系抽取实际就是找出实体和实体之间的关系,这是自然语言处理一个质的跨越,实体识别让机器认知了一种事物,关系识别让机器掌握了一个真相。
关系抽取的第一个方法就是找到(X, a, Y)这种三元组,其中X和Y都是实体,a是表达关系的字符串,这完全可以通过正则来识别,因为不同语言有这不同的语法规则,所以方法都是不同的,比如中文里的“爱”可以作为这里的a,但是“和”、“因为”等就不能作为这里的a
编程实现 下面介绍部分有关分块的代码,因为中文标注好分块的语料没有找到,所以只能沿用英文语料来说明,但是原理是一样的
conll2000语料中已经有标注好的分块信息,如下:
1
2
from nltk.corpusimport conll2000
print conll2000.chunked_sents('train.txt' )[99 ]
1
2
3
4
5
6
7
8
9
10
(S
(PP Over/IN)
(NP a/DT cup/NN)
(PP of/IN)
(NP coffee/NN)
,/,
(NP Mr./NNP Stone/NNP)
(VP told/VBD)
(NP his/PRP$ story/NN)
./.)
我们可以基于这些标注数据做训练,由于这种存储结构比较特殊,所以就不单独基于这种结构实现parser了,只说下跟前面讲的机器学习一样,只要基于这部分数据做训练,然后再用来标注新的语料就行了
文法分析还是基于特征好啊 语法分析固然重要,但要想覆盖语言的全部,需要进一步扩展到文法分析,文法分析可以基于规则,但是工作量难以想象,基于特征的文法分析不但可穷举,而且可以方便用计算机存储和计算,本节简单做一个介绍,更深层次的内容还需要继续关注后面的系列文章
语法和文法 还记得上一节中的这个吗?
1
2
3
4
5
6
7
(S
(NP 小明)
(VP
(V 追赶)
(NP
(Det 一只)
(N 兔子))))
这里面的N表示名词,Det表示限定词,NP表示名词短语,V表示动词,VP表示动词短语,S表示句子
这种句子分析方法叫做语法分析
因为句子可以无限组合无限扩展,所以单纯用语法分析来完成自然语言处理这件事情是不可能的,所以出现了文法分析
文法是一个潜在的无限的句子集合的一个紧凑的特性,它是通过一组形式化模型来表示的,文法可以覆盖所有结构的句子,对一个句子做文法分析,就是把句子往文法模型上靠,如果同时符合多种文法,那就是有歧义的句子
最重要的结论:文法结构范围相当广泛,无法用规则类的方法来处理,只有利用基于特征的方法才能处理
文法特征结构 文法特征举例:单词最后一个字母、词性标签、文法类别、正字拼写、指示物、关系、施事角色、受事角色
因为文法特征是一种kv,所以特征结构的存储形式是字典
不是什么样的句子都能提取出每一个文法特征的,需要满足一定的条件,这需要通过一系列的检查手段来达到,包括:句法协议(比如this dog就是对的,而these dog就是错的)、属性和约束、术语
特征结构的处理 nltk帮我实现了特征结构:
1
2
3
4
5
import nltk
fs1 = nltk.FeatStruct(TENSE='past' , NUM='sg' )
print fs1
fs2 = nltk.FeatStruct(POS='N' , AGR=fs1)
print fs2
1
2
3
4
5
6
7
[ NUM = 'sg' ]
[ TENSE = 'past' ]
[ AGR = [ NUM = 'sg' ] ]
[ [ TENSE = 'past' ] ]
[ ]
[ POS = 'N' ]
在nltk的库里已经有了一些产生式文法描述可以直接使用,位置在:
1
ls /usr/share/nltk_data/grammars/book_grammars
1
background.fol discourse.fcfg drt.fcfg feat0.fcfg feat1.fcfg german.fcfg simple-sem.fcfg sql0.fcfg sql1.fcfg storage.fcfg
我们看其中最简单的一个sql0.fcfg,这是一个查找国家城市的sql语句的文法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
% start S
S[SEM=(?np + WHERE + ?vp)] -> NP[SEM=?np] VP[SEM=?vp]
VP[SEM=(?v + ?pp)] -> IV[SEM=?v] PP[SEM=?pp]
VP[SEM=(?v + ?ap)] -> IV[SEM=?v] AP[SEM=?ap]
NP[SEM=(?det + ?n)] -> Det[SEM=?det] N[SEM=?n]
PP[SEM=(?p + ?np)] -> P[SEM=?p] NP[SEM=?np]
AP[SEM=?pp] -> A[SEM=?a] PP[SEM=?pp]
NP[SEM='Country="greece"'] -> 'Greece'
NP[SEM='Country="china"'] -> 'China'
Det[SEM='SELECT'] -> 'Which' | 'What'
N[SEM='City FROM city_table'] -> 'cities'
IV[SEM=''] -> 'are'
A[SEM=''] -> 'located'
P[SEM=''] -> 'in'
解释一下 这里面从上到下是从最大范围到最小范围一个个的解释,S是句子
我们来加载这个文法描述,并试验如下:
1
2
3
4
5
6
7
import nltk
from nltkimport load_parser
cp = load_parser('grammars/book_grammars/sql0.fcfg' )
query ='What cities are located in China'
tokens = query.split()
for treein cp.parse(tokens):
print tree
1
2
3
4
5
6
7
8
9
10
11
(S[SEM=(SELECT, City FROM city_table, WHERE, , , Country="china")]
(NP[SEM=(SELECT, City FROM city_table)]
(Det[SEM='SELECT'] What)
(N[SEM='City FROM city_table'] cities))
(VP[SEM=(, , Country="china")]
(IV[SEM=''] are)
(AP[SEM=(, Country="china")]
(A[SEM=''] located)
(PP[SEM=(, Country="china")]
(P[SEM=''] in)
(NP[SEM='Country="china"'] China)))))
我们可以看到用特征结构可以建立对大量广泛的语言学现象的简介分析
重温自然语言处理 自然语言处理怎么学? 先学会倒着学,倒回去看上面那句话:不管三七二十一先用起来,然后再系统地学习
nltk是最经典的自然语言处理的python库,不知道怎么用的看前几篇文章吧,先把它用起来,最起码做出来一个词性标注的小工具
自然语言处理学什么? 这门学科的知识可是相当的广泛,广泛到你不需要掌握任何知识就可以直接学,因为你不可能掌握它依赖的全部知识,所以就直接冲过去吧。。。
话说回来,它到底包括哪些知识呢?如果把这些知识比作难关的话,我数一数,整整九九八十一难
第一难:语言学。直接懵逼了吧?语言学啥玩意,怎么说话?还是怎么学说话?其实大家也都说不清语言学是什么东东,但是我知道大家在这方面都在研究啥,有的在研究语言描述的学问,有的在研究语言理论的学问,有的在研究不同语言对比的学问,有的在研究语言共同点上的学问,有的在研究语言发展的历史,有的在研究语言的结构,总之用一个字来形容那是一个涉猎广泛啊
第二难:语音学。再一次懵逼!有人说:我知道!语音学就是怎么发声。赞一个,回答的那是相当不完全对啊!你以为你是学唱歌吗?语音学研究领域分三块:一块是研究声音是怎么发出来的(同学你说对了一点);一块是研究声音是怎么传递的;一块是研究声音是怎么接收的。这尼玛不是物理吗?怎么还整出语言学来了?其实这是一个交叉学科,交叉了语言学,交叉了生物学
第三难:概率论。啥?怎么到处都是概率论啊?听人说今年又某某某得了诺贝尔经济学奖了,我定睛一看,尼玛,这不是研究的概率论嘛,这也能得经济学奖,真是得数学者得天下啊。废话少说,概率论跟自然语言处理有什么关系?我知道了,说话是一个概率问题,我经常说“尼玛”,那我再次说“尼玛”的概率就高,嗯~沾边了。提到概率论那就少不了这些:贝叶斯老爷爷、马尔可夫大叔……
第四难:信息论。提到信息论肯定第一个想到的是“香浓”啊,有点流口水了,香农老爷爷提出的熵理论影响那是相当巨大啊,没有它估计就没有我们计算机人事什么事了,因为没有他就没有互联网了。还有人说没有图灵就没有计算机了,他咋不说没有他们俩就没有地球了呢?
第五难:机器学习。机器学习是我的最爱,得聊的正式一点,咳咳!机器学习啊——得好好学
第六难:形式语言与自动机。我滴妈啊!我跪了!刚说图灵图灵就来了。说白了,形式语言就是把语言搞的很形式,换句话说就是本来你能懂的东西,搞成你不能懂的东西,那就是形式语言啦!不信?你听:短语结构语言、上下文有关语言、上下文无关语言、正则语言,懂了吗?而自动机呢包括:图灵机、有穷自动机、下推自动机、线性有界自动机。你可能会问了,这么多自动机那得要多少汽油啊?该死的翻译怎么就把这么高大上的英文给翻译成这么晦涩呢,自动机英文叫automata,表达的是自动形成一些信息,也就是说根据前面能自动判断出后面。形式语言用在自然语言处理上我理解,都有语言俩字,可是这自动机有什么用呢?这您还真问着了,您见过拼写检查吗?这就是用的自动机,用处杠杠的!
第七难:语言知识库。你见过科幻电影里的机器人手捧着电话线就能知道一切的镜头吧,互联网上有无数文本内容,用我们抽象的话说那都是知识,但是简单放在电脑里那就是一串字符串,怎么才能让它以知识的形式存储呢?首先得让计算机能分析语言,那么语料就是它学习的基础、是种子,然后有了基础再让它把语言里的知识存储起来,这就形成了语言知识库
第八难:语言模型。模型顾名思义就是“模子”,就是“往上靠”的意思,怎么靠上去更吻合就怎么靠,这就是语言模型。怎么?没懂?好那我用形式化的语言再来说一下:把很多已经整理好的模子放在那里,遇到一个新内容的时候看看属于哪种格式,那就按照这种模子来解释。嗯~你肯定懂了
第九难:分词、实体识别、词性标注。这部分开始纯语言处理了,前几节也简单讲过这部分内容,分词就是让计算机自动区分出汉字组成的词语,因为一个词语一个意思嘛。实体识别就是再分词之后能够根据各种短语形式判断出哪个词表示的是一个物体或组织或人名或……。词性标注就是给你一句话,你能识别出“名动形、数量代、副介连助叹拟声”。
第十难:句法分析。句法分析类似于小学时学的主谓宾补定状的区分,只是要在这基础上组合成短语,也就是把一个非结构化的句子分析称结构化的数据结构
第十一难:语义分析。看起来一步一步越来越深入了。语义是基于句法分析,进一步理解句子的意思,最重要的就是消除歧义,人姑且还会理解出歧义来呢,何况一个机器
第十二难:篇章分析。一堆堆的句子,每个都分析明白了,但是一堆句子组合成的篇章又怎么才能联系起来呢?你得总结出本文的中心思想不是?这他娘的是小学语文里最难的一道题
以上这些内容就是自然语言处理的几大难了,什么?说好的九九八十一难呢?你还不嫌多啊?你还真想变成孙猴子吗?能把这几关过了就不错了!
自然语言处理和聊天机器人什么关系? 说到这里,索性就说说下自然语言处理的应用领域吧。
第一个应用:机器翻译。机器翻译方法有很多,我不做,也不说,想学自己看去
第二个应用:语音翻译。跟上一个不是一个吗?不是的,这是语音,那个是机器
第三个应用:文本分类与情感分析。别看两个词,其实是一种事——分类。前面有很多篇文章将文本分类的,可以看看,还有代码噢。
第四个应用:信息检索与问答系统。终于说到重点了,累死我了。这里的问答系统就是我们的聊天机器人。后面会着重讲这个应用,我不断读论文,不断给大家分享哈,别着急,乖!
第五个应用:自动文摘和信息抽取。看过百度搜索里显示的摘要吗?他们多么的精简,而且描述了网页里的中心内容,多漂亮啊!可惜多数都没做到自动文摘。所以这是一个高技术难度的问题。
第六个应用:人机对话。融合了语音识别、口语情感分析、再加上问答系统的全部内容,是自然语言处理的最高境界,离机器人统霸世界不远了。
以及这么多数不完的应用:文本挖掘、舆情分析、隐喻计算、文字编辑和自动校对、作文自动评分、OCR、说话人识别验证……
好!自然语言处理就温习到这里,让我们上阵出发!
聊天机器人应该怎么做 聊天机器人到底该怎么做呢?我日思夜想,于是乎我做了一个梦,梦里面我完成了我的聊天机器人,它叫chatbot,经过我的一番盘问,它向我叙述了它的诞生记
聊天机器人是可行的 我:chatbot,你好!
chatbot:你也好!
我:聊天机器人可行吗?
chatbot:你不要怀疑这是天方夜谭,我不就在这里吗?世界上还有很多跟我一样聪明的机器人呢,你听过IBM公司在2010年就研发出来了的Watson问答系统吗?它可比我要聪明100倍呢
我:噢,想起来了,据说Watson在智力竞赛中竟然战胜了人类选手。但是我了解到它有一些缺陷:因为它还只是对信息检索技术的综合运用,并没有进行各种语义关系的深刻计算,所以它能回答的问题也仅限于实事类的问题,所以它能赢得也就是知识类的智力竞赛,如果你给它出个脑筋急转弯,它就不行了
chatbot:是的呢,所以你任重道远啊
聊天机器人工作原理是什么 我:chatbot,我问的每一句话,你都是怎么处理并回答我的呢?
chatbot:我身体里有三个重要模块:提问处理模块、检索模块、答案抽取模块。三个模块一起工作,就能回答你的问题啦
我:是嘛,那么这个提问处理模块是怎么工作的呢?
chatbot:提问处理模块要做三项重要工作:查询关键词生成、答案类型确定、句法和语义分析。
我:那么这个查询关。。。
chatbot:别急别急,听我一个一个讲给你听。查询关键词生成,就是从你的提问中提取出关键的几个关键词,因为我本身是一个空壳子,需要去网上查找资料才能回答你,而但网上资料那么多,我该查哪些呢?所以你的提问就有用啦,我找几个中心词,再关联出几个扩展词,上网一搜,一大批资料就来啦,当然这些都是原始资料,我后面要继续处理。再说答案类型确定,这项工作是为了确定你的提问属于哪一类的,如果你问的是时间、地点,和你问的是技术方案,那我后面要做的处理是不一样的。最后再说这个句法和语义分析,这是对你问题的深层含义做一个剖析,比如你的问题是:聊天机器人怎么做?那么我要知道你要问的是聊天机器人的研发方法
我:原来是这样,提问处理模块这三项工作我了解了,那么检索模块是怎么工作的呢?
chatbot:检索模块跟搜索引擎比较像,就是根据查询关键词所信息检索,返回句子或段落,这部分就是下一步要处理的原料
我:那么答案抽取模块呢?
chatbot:答案抽取模块可以说是计算量最大的部分了,它要通过分析和推理从检索出的句子或段落里抽取出和提问一致的实体,再根据概率最大对候选答案排序,注意这里是“候选答案”噢,也就是很难给出一个完全正确的结果,很有可能给出多个结果,最后还在再选出一个来
我:那么我只要实现这三个模块,就能做成一个你喽?
chatbot:是的
聊天机器人的关键技术 我:chatbot,小弟我知识匮乏,能不能告诉我都需要学哪些关键技术才能完成我的梦想
chatbot:小弟。。。我还没满月。说到关键技术,那我可要列一列了,你的任务艰巨了:
1)海量文本知识表示:网络文本资源获取、机器学习方法、大规模语义计算和推理、知识表示体系、知识库构建;
2)问句解析:中文分词、词性标注、实体标注、概念类别标注、句法分析、语义分析、逻辑结构标注、指代消解、关联关系标注、问句分类(简单问句还是复杂问句、实体型还是段落型还是篇章级问题)、答案类别确定;
3)答案生成与过滤:候选答案抽取、关系推演(并列关系还是递进关系还是因果关系)、吻合程度判断、噪声过滤
聊天机器人的技术方法 我:chatbot,我对聊天机器人的相关技术总算有所了解了,但是我具体要用什么方法呢?
chatbot:看你这么好学,那我就多给你讲一讲。聊天机器人的技术可以分成四种类型:1)基于检索的技术;2)基于模式匹配的技术;3)基于自然语言理解的技术;4)基于统计翻译模型的技术。这几种技术并不是都要实现,而是选其一,听我给你说说他们的优缺点,你就知道该选哪一种了。基于检索的技术就是信息检索技术,它简单易实现,但无法从句法关系和语义关系给出答案,也就是搞不定推理问题,所以直接pass掉。基于模式匹配的技术就是把问题往已经梳理好的几种模式上去靠,这种做推理简单,但是模式我们涵盖不全,所以也pass掉。基于自然语言理解就是把浅层分析加上句法分析、语义分析都融入进来做的补充和改进。基于统计翻译就是把问句里的疑问词留出来,然后和候选答案资料做配对,能对齐了就是答案,对不齐就对不起了,所以pass掉。选哪个知道了吗?
我:知道了!基于自然语言理解的技术!so easy!妈妈再也不用担心我的学习!o(╯□╰)o
半个小时搞定词性标注与关键词提取 想要做到和人聊天,首先得先读懂对方在说什么,所以问句解析是整个聊天过程的第一步,问句解析是一个涉及知识非常全面的过程,几乎涵盖了自然语言处理的全部,本节让我们尝试一下如何分析一个问句
问句解析的过程 一般问句解析需要进行分词、词性标注、命名实体识别、关键词提取、句法分析以及查询问句分类等。这些事情我们从头开始做无非是重复造轮子,傻子才会这么做,人之所以为人是因为会使用工具。网络上有关中文的NLP工具有很多,介绍几个不错的:
第一个要数哈工大的LTP(语言技术平台)了,它可以做中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注等丰富、 高效、精准的自然语言处理技术
第二个就是博森科技了,它除了做中文分词、词性标注、命名实体识别、依存文法之外还可以做情感分析、关键词提取、新闻分类、语义联想、时间转换、新闻摘要等,但因为是商业化的公司,除了分词和词性标注免费之外全都收费
第三个就是jieba分词,这个开源小工具分词和词性标注做的挺不错的,但是其他方面还欠缺一下,如果只是中文分词的需求完全可以满足
第四个就是中科院张华平博士的NLPIR汉语分词系统,也能支持关键词提取
我们优先选择NLPIR
NLPIR使用 文档在http://pynlpir.readthedocs.io/en/latest/
首先安装pynlpir库
1
2
pip install pynlpir
pynlpir update
若出现授权错误,则去https://github.com/NLPIR-team/NLPIR/tree/master/License/license%20for%20a%20month/NLPIR-ICTCLAS%E5%88%86%E8%AF%8D%E7%B3%BB%E7%BB%9F%E6%8E%88%E6%9D%83 下载授权文件NLPIR.user, 覆盖到/usr/local/lib/python2.7/dist-packages/pynlpir/Data/
写个小程序测试一下分词效果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import sys
reload(sys)
sys.setdefaultencoding("utf-8" )
import pynlpir
pynlpir.open()
s ='聊天机器人到底该怎么做呢?'
segments = pynlpir.segment(s)
for segmentin segments:
print segment[0 ],'\t' , segment[1 ]
pynlpir.close()
1
2
3
4
5
6
7
8
聊天 verb
机器人 noun
到底 adverb
该 verb
怎么 pronoun
做 verb
呢 modal particle
? punctuation mark
下面我们再继续试下关键词提取效果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import sys
reload(sys)
sys.setdefaultencoding("utf-8" )
import pynlpir
pynlpir.open()
s ='聊天机器人到底该怎么做呢?'
key_words = pynlpir.get_key_words(s, weighted=True )
for key_wordin key_words:
print key_word[0 ],'\t' , key_word[1 ]
pynlpir.close()
从这个小程序来看,分词和关键词提取效果很好
下面我们再来试验一个,这一次我们把分析功能全打开,部分代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import sys
reload(sys)
sys.setdefaultencoding("utf-8" )
import pynlpir
pynlpir.open()
s ='海洋是如何形成的'
segments = pynlpir.segment(s, pos_names='all' , pos_english=False )
for segmentin segments:
print segment[0 ],'\t' , segment[1 ]
key_words = pynlpir.get_key_words(s, weighted=True )
for key_wordin key_words:
print key_word[0 ],'\t' , key_word[1 ]
pynlpir.close()
1
2
3
4
5
6
7
8
海洋 noun
是 verb:verb 是
如何 pronoun:interrogative pronoun:predicate interrogative pronoun
形成 verb
的 particle:particle 的/底
海洋 2.0
形成 2.0
如果我们把segments在加上一个参数pos_english=False,也就是不使用英语,那么输出就是
1
2
3
4
5
6
7
8
海洋 名词
是 动词:动词"是"
如何 代词:疑问代词:谓词性疑问代词
形成 动词
的 助词:的/底
海洋 2.0
形成 2.0
解释一下 这里的segment是切词的意思,返回的是tuple(token, pos),其中token就是切出来的词,pos就是语言属性
调用segment方法指定的pos_names参数可以是’all’, ‘child’, ‘parent’,默认是parent, 表示获取该词性的最顶级词性,child表示获取该词性的最具体的信息,all表示获取该词性相关的所有词性信息,相当于从其顶级词性到该词性的一条路径
词性分类表 查看nlpir的源代码中的pynlpir/docs/pos_map.rst,可以看出全部词性分类及其子类别如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
POS_MAP = {
'n': ('名词', 'noun', {
'nr': ('人名', 'personal name', {
'nr1': ('汉语姓氏', 'Chinese surname'),
'nr2': ('汉语名字', 'Chinese given name'),
'nrj': ('日语人名', 'Japanese personal name'),
'nrf': ('音译人名', 'transcribed personal name')
}),
'ns': ('地名', 'toponym', {
'nsf': ('音译地名', 'transcribed toponym'),
}),
'nt': ('机构团体名', 'organization/group name'),
'nz': ('其它专名', 'other proper noun'),
'nl': ('名词性惯用语', 'noun phrase'),
'ng': ('名词性语素', 'noun morpheme'),
}),
't': ('时间词', 'time word', {
'tg': ('时间词性语素', 'time morpheme'),
}),
's': ('处所词', 'locative word'),
'f': ('方位词', 'noun of locality'),
'v': ('动词', 'verb', {
'vd': ('副动词', 'auxiliary verb'),
'vn': ('名动词', 'noun-verb'),
'vshi': ('动词"是"', 'verb 是'),
'vyou': ('动词"有"', 'verb 有'),
'vf': ('趋向动词', 'directional verb'),
'vx': ('行事动词', 'performative verb'),
'vi': ('不及物动词', 'intransitive verb'),
'vl': ('动词性惯用语', 'verb phrase'),
'vg': ('动词性语素', 'verb morpheme'),
}),
'a': ('形容词', 'adjective', {
'ad': ('副形词', 'auxiliary adjective'),
'an': ('名形词', 'noun-adjective'),
'ag': ('形容词性语素', 'adjective morpheme'),
'al': ('形容词性惯用语', 'adjective phrase'),
}),
'b': ('区别词', 'distinguishing word', {
'bl': ('区别词性惯用语', 'distinguishing phrase'),
}),
'z': ('状态词', 'status word'),
'r': ('代词', 'pronoun', {
'rr': ('人称代词', 'personal pronoun'),
'rz': ('指示代词', 'demonstrative pronoun', {
'rzt': ('时间指示代词', 'temporal demonstrative pronoun'),
'rzs': ('处所指示代词', 'locative demonstrative pronoun'),
'rzv': ('谓词性指示代词', 'predicate demonstrative pronoun'),
}),
'ry': ('疑问代词', 'interrogative pronoun', {
'ryt': ('时间疑问代词', 'temporal interrogative pronoun'),
'rys': ('处所疑问代词', 'locative interrogative pronoun'),
'ryv': ('谓词性疑问代词', 'predicate interrogative pronoun'),
}),
'rg': ('代词性语素', 'pronoun morpheme'),
}),
'm': ('数词', 'numeral', {
'mq': ('数量词', 'numeral-plus-classifier compound'),
}),
'q': ('量词', 'classifier', {
'qv': ('动量词', 'verbal classifier'),
'qt': ('时量词', 'temporal classifier'),
}),
'd': ('副词', 'adverb'),
'p': ('介词', 'preposition', {
'pba': ('介词“把”', 'preposition 把'),
'pbei': ('介词“被”', 'preposition 被'),
}),
'c': ('连词', 'conjunction', {
'cc': ('并列连词', 'coordinating conjunction'),
}),
'u': ('助词', 'particle', {
'uzhe': ('着', 'particle 着'),
'ule': ('了/喽', 'particle 了/喽'),
'uguo': ('过', 'particle 过'),
'ude1': ('的/底', 'particle 的/底'),
'ude2': ('地', 'particle 地'),
'ude3': ('得', 'particle 得'),
'usuo': ('所', 'particle 所'),
'udeng': ('等/等等/云云', 'particle 等/等等/云云'),
'uyy': ('一样/一般/似的/般', 'particle 一样/一般/似的/般'),
'udh': ('的话', 'particle 的话'),
'uls': ('来讲/来说/而言/说来', 'particle 来讲/来说/而言/说来'),
'uzhi': ('之', 'particle 之'),
'ulian': ('连', 'particle 连'),
}),
'e': ('叹词', 'interjection'),
'y': ('语气词', 'modal particle'),
'o': ('拟声词', 'onomatopoeia'),
'h': ('前缀', 'prefix'),
'k': ('后缀' 'suffix'),
'x': ('字符串', 'string', {
'xe': ('Email字符串', 'email address'),
'xs': ('微博会话分隔符', 'hashtag'),
'xm': ('表情符合', 'emoticon'),
'xu': ('网址URL', 'URL'),
'xx': ('非语素字', 'non-morpheme character'),
}),
'w': ('标点符号', 'punctuation mark', {
'wkz': ('左括号', 'left parenthesis/bracket'),
'wky': ('右括号', 'right parenthesis/bracket'),
'wyz': ('左引号', 'left quotation mark'),
'wyy': ('右引号', 'right quotation mark'),
'wj': ('句号', 'period'),
'ww': ('问号', 'question mark'),
'wt': ('叹号', 'exclamation mark'),
'wd': ('逗号', 'comma'),
'wf': ('分号', 'semicolon'),
'wn': ('顿号', 'enumeration comma'),
'wm': ('冒号', 'colon'),
'ws': ('省略号', 'ellipsis'),
'wp': ('破折号', 'dash'),
'wb': ('百分号千分号', 'percent/per mille sign'),
'wh': ('单位符号', 'unit of measure sign'),
}),
}
好,这回我们一下子完成了分词、词性标注、关键词提取。命名实体识别、句法分析以及查询问句分类我们之后再研究
输出文本,输出提切结果,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import pynlpir
pynlpir.open()
s = raw_input('请输入语句:')
segments = pynlpir.segment(s, pos_names='all', pos_english=False)
for segment in segments:
print segment[0], '\t', segment[1]
key_words = pynlpir.get_key_words(s, weighted=True)
for key_word in key_words:
print key_word[0], '\t', key_word[1]
pynlpir.close()
0字节存储海量语料资源 基于语料做机器学习需要海量数据支撑,如何能不存一点数据获取海量数据呢?我们可以以互联网为强大的数据后盾,搜索引擎为我们提供了高效的数据获取来源,结构化的搜索结果展示为我们实现了天然的特征基础,唯一需要我们做的就是在海量结果中选出我们需要的数据,本节我们来探索如何利用互联网拿到我们所需的语料资源
关键词提取 互联网资源无穷无尽,如何获取到我们所需的那部分语料库呢?这需要我们给出特定的关键词,而基于问句的关键词提取上一节已经做了介绍,利用pynlpir库可以非常方便地实现关键词提取,比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import sys
reload(sys)
sys.setdefaultencoding("utf-8" )
import pynlpir
pynlpir.open()
s ='怎么才能把电脑里的垃圾文件删除'
key_words = pynlpir.get_key_words(s, weighted=True )
for key_wordin key_words:
print key_word[0 ],'\t' , key_word[1 ]
pynlpir.close()
提取出的关键词如下:
1
2
3
4
电脑 2.0
垃圾 2.0
文件 2.0
删除 1.0
我们基于这四个关键词来获取互联网的资源就可以得到我们所需要的语料信息
充分利用搜索引擎 有了关键词,想获取预料信息,还需要知道几大搜索引擎的调用接口,首先我们来探索一下百度,百度的接口是这样的:
https://www.baidu.com/s?wd=机器学习 数据挖掘 信息检索
把wd参数换成我们的关键词就可以拿到相应的结果,我们用程序来尝试一下:
首先创建scrapy工程,执行:
1
scrapy startproject baidu_search
自动生成了baidu_search目录和下面的文件(不知道怎么使用scrapy,请见我的文章教你成为全栈工程师(Full Stack Developer) 三十-十分钟掌握最强大的python爬虫)
创建baidu_search/baidu_search/spiders/baidu_search.py文件,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import sys
reload(sys)
sys.setdefaultencoding("utf-8" )
import scrapy
class BaiduSearchSpider (scrapy.Spider) :
name ="baidu_search"
allowed_domains = ["baidu.com" ]
start_urls = [
"https://www.baidu.com/s?wd=机器学习"
]
def parse (self, response) :
print response.body
这样我们的抓取器就做好了,进入baidu_search/baidu_search/目录,执行:
1
scrapy crawl baidu_search
我们发现返回的数据是空,下面我们修改配置来解决这个问题,修改settings.py文件,把ROBOTSTXT_OBEY改为
并把USER_AGENT设置为:
1
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
为了避免抓取hang住,我们添加如下超时设置:
再次执行
1
scrapy crawl baidu_search
这次终于可以看到大片大片的html了,我们临时把他写到文件中,修改parse()函数如下:
1
2
3
4
def parse(self, response):
filename = "result.html"
with open(filename, 'wb') as f:
f.write(response.body)
重新执行后生成了result.html,我们用浏览器打开本地文件。
语料提取 上面得到的仅是搜索结果,它只是一种索引,真正的内容需要进入到每一个链接才能拿到,下面我们尝试提取出每一个链接并继续抓取里面的内容,那么如何提取链接呢,我们来分析一下result.html这个抓取百度搜索结果文件
我们可以看到,每一条链接都是嵌在class=c-container这个div里面的一个h3下的a标签的href属性
所以我们的提取规则就是:
1
hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract()
修改parse()函数并添加如下代码:
1
2
3
hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href' ).extract()
for hrefin hrefs:
print href
执行打印出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
......
2017-08-21 22:26:17 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.baidu.com/s?wd=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0> (referer: None)
http://www.baidu.com/link?url=evTTw58FTb9_-gGNUuOgv3_coiSBhpi-4ZQKoLQZvPXbsj3kfzROuH4cm1CxPqSqWl_E1vamGMyOHAO1G3jXEMyXoF0fHSbGmWzX99tDkCnTLIrR8-oysqnEb7VzI2EC
http://www.baidu.com/link?url=T0QwDAL_1ypuWLshTeFSh9Tkl3wQVwQFaY_sjIRY1G7TaBq2YC1SO2T2mLsLTiC2tFJ878OihtiIkEgepJNG-q
http://www.baidu.com/link?url=xh1H8nE-T4CeAq_A3hGbNwHfDKs6K7HCprH6DrT29yv6vc3t_DSk6zq7_yekiL_iyd9rGxMSONN_wJDwpjqNAK
http://www.baidu.com/link?url=LErVCtq1lVKbh9QAAjdg37GW1_B3y8g_hjoafChZ90ycuG3razgc9X_lE4EgiibkjzCPImQOxTl-b5LOwZshtxSf7sCTOlBpLRjcMyG2Fc7
http://www.baidu.com/link?url=vv_KA9CNJidcGTV1SE096O9gXqVC7yooCDMVvCXg9Vg22nZW2eBIq9twWSFh17VVYqNJ26wkRJ7XKuTsD3-qFDdi5_v-AZZrDeNI07aZaYG
http://www.baidu.com/link?url=dvMowOWWPV3kEZxzy1q7W2OOBuph0kI7FuZTwp5-ejsU-f-Aiif-Xh7U4zx-qoKW_O1fWVwutJuOtEWr2A7cwq
http://www.baidu.com/link?url=evTTw58FTb9_-gGNUuOgvHC_aU-RmA0z8vc7dTH6-tgzMKuehldik7N_vi0s4njGvLo13id-kuGnVhhmfLV3051DpQ7CLO22rKxCuCicyTe
http://www.baidu.com/link?url=QDkm6sUGxi-qYC6XUYR2SWB_joBm_-25-EXUSyLm9852gQRu41y-u_ZPG7SKhjs6U_l99ZcChBNXz4Ub5a0RJa
http://www.baidu.com/link?url=Y9Qfk4m6Hm8gQ-7XgUzAl5b-bgxNOBn_e_7v9g6XHmsZ_4TK8Mm1E7ddQaDUAdSCxjgJ_Ao-vYA6VZjfVuIaX58PlWo_rV8AqhVrDA1Bd0W
http://www.baidu.com/link?url=X7eU-SPPEylAHBTIGhaET0DEaLEaTYEjknjI2_juK7XZ2D2eb90b1735tVu4vORourw_E68sZF8P2O4ghTVcQa
2017-08-21 22:26:17 [scrapy.core.engine] INFO: Closing spider (finished)
...
下面我们把这些url添加到抓取队列中继续抓取,修改baidu_search.py文件,如下:
1
2
3
4
5
6
7
def parse(self, response):
hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract()
for href in hrefs:
yield scrapy.Request(href, callback=self.parse_url)
def parse_url(self, response):
print len(response.body)
抓取效果如下:
1
2
3
4
5
6
7
8
2017-08-21 22:29:50 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.baidu.com/s?wd=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0> (referer: None)
2017-08-21 22:29:50 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET http://www.leiphone.com/news/201609/SJGulTsdGcisR8Wz.html> from <GET http://www.baidu.com/link?url=iQ6rC78zm48BmQQ2GcK8ffphKCITxraUEcyS1waz7_yn5JLl5ZJgKerMXO1yQozfC9vxN0C89iU0Rd2nwEFXoEj1doqsbCupuDARBEtlHW3>
2017-08-21 22:29:50 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET http://blog.jobbole.com/tag/machinelearning/> from <GET http://www.baidu.com/link?url=XIi6gyYcL8XtxD7ktWfZssm0Z2nO-TY5xzrHI8TLOMnUWj8a9u4swB3KI66yhT4wrqXhjxyRq95s5PkHlsplwq>
2017-08-21 22:29:50 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.zhihu.com/question/33892253> from <GET http://www.baidu.com/link?url=tP0PBScNvaht7GL1qoJCQQzfNpdmDK_Cw5FNF3xVwluaYwlLjWxEzgtFalHtai1KNd7XD4h54LlrmI2ZGgottK>
2017-08-21 22:29:50 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET http://open.163.com/special/opencourse/machinelearning.html> from <GET http://www.baidu.com/link?url=vZdsoRD6urZDhxJGRHNJJ7vSeTfI8mdkH0F01gkG24x9hj5HjiWPU7bsdDtJJMvEi-x4QIjX-hG5pQ4AWpeIq2u7NddTwiDDrXwRZF9_Sxe>
2017-08-21 22:29:50 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET http://tieba.baidu.com/f?kw=%BB%FA%C6%F7%D1%A7%CF%B0&fr=ala0&tpl=5> from <GET http://www.baidu.com/link?url=nSVlWumopaJ_gz-bWMvVTQBtLY8E0LkwP3gPc86n26XQ9WDdlsI_1pNAVGa_4YSYoKpHiUy2qcBdJOvQuxcvEmBFPGufpbHsCA3ia2t_-HS>
2017-08-21 22:29:50 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET http://tech.163.com/16/0907/07/C0BHQND400097U80.html> from <GET http://www.baidu.com/link?url=g7VePX8O7uHmJphvogYc6U8uMKbIbVSuFQAUw05fmD-tPTr4T9yvS4sbDZCZ8FYBelGq95nCpAJhghsiQf_hoq>
2017-08-21 22:29:50 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.zhihu.com/question/20691338> from <GET http://www.baidu.com/link?url=pjwLpE4UAddN9It0yK3-Ypr6MDcAciWoNMBb5GOnX0-Xi-vV3A1ZbWv32oCRwMoIKwa__pPdOxVTzrCu7d9zz_>
看起来能够正常抓取啦,下面我们把抓取下来的网页提取出正文并尽量去掉标签,如下:
1
2
def parse_url (self, response) :
print remove_tags(response.selector.xpath('//body' ).extract()[0 ])
下面,我们希望把百度搜索结果中的摘要也能够保存下来作为我们语料的一部分,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def parse (self, response) :
hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href' ).extract()
containers = response.selector.xpath('//div[contains(@class, "c-container")]' )
for containerin containers:
href = container.xpath('h3/a/@href' ).extract()[0 ]
title = remove_tags(container.xpath('h3/a' ).extract()[0 ])
c_abstract = container.xpath('div/div/div[contains(@class, "c-abstract")]' ).extract()
abstract =""
if len(c_abstract) >0 :
abstract = remove_tags(c_abstract[0 ])
request = scrapy.Request(href, callback=self.parse_url)
request.meta['title' ] = title
request.meta['abstract' ] = abstract
yield request
def parse_url (self, response) :
print "url:" , response.url
print "title:" , response.meta['title' ]
print "abstract:" , response.meta['abstract' ]
content = remove_tags(response.selector.xpath('//body' ).extract()[0 ])
print "content_len:" , len(content)
解释一下,首先我们在提取url的时候顺便把标题和摘要都提取出来,然后通过scrapy.Request的meta传递到处理函数parse_url中,这样在抓取完成之后也能接到这两个值,然后提取出content,这样我们想要的数据就完整了:url、title、abstract、content
百度搜索数据几乎是整个互联网的镜像,所以你想要得到的答案,我们的语料库就是整个互联网,而我们完全借助于百度搜索引擎,不必提前存储任何资料,互联网真是伟大!
之后这些数据想保存在什么地方就看后面我们要怎么处理了,欲知后事如何,且听下回分解
教你如何利用强大的中文语言技术平台做依存句法和语义依存分析 句法分析是自然语言处理中非常重要的环节,没有句法分析是无法让计算机理解语言的含义的,依存句法分析由法国语言学家在1959年提出,影响深远,并且深受计算机行业青睐,依存句法分析也是做聊天机器人需要解决的最关键问题之一,语义依存更是对句子更深层次的分析,当然,有可用的工具我们就不重复造轮子,本节介绍如何利用国内领先的中文语言技术平台实现句法分析
什么是依存句法分析呢? 叫的晦涩的术语,往往其实灰常简单,句法就是句子的法律规则,也就是句子里成分都是按照什么法律规则组织在一起的。而依存句法就是这些成分之间有一种依赖关系。什么是依赖:没有你的话,我存在就是个错误。“北京是中国的首都”,如果没有“首都”,那么“中国的”存在就是个错误,因为“北京是中国的”表达的完全是另外一个意思了。
什么是语义依存分析呢? “语义”就是说句子的含义,“张三昨天告诉李四一个秘密”,那么语义包括:谁告诉李四秘密的?张三。张三告诉谁一个秘密?李四。张三什么时候告诉的?昨天。张三告诉李四什么?秘密。
语义依存和依存句法的区别 依存句法强调介词、助词等的划分作用,语义依存注重实词之间的逻辑关系
另外,依存句法随着字面词语变化而不同,语义依存不同字面词语可以表达同一个意思,句法结构不同的句子语义关系可能相同。
依存句法分析和语义依存分析对我们的聊天机器人有什么意义呢? 依存句法分析和语义分析相结合使用,对对方说的话进行依存和语义分析后,一方面可以让计算机理解句子的含义,从而匹配到最合适的回答,另外如果有已经存在的依存、语义分析结果,还可以通过置信度匹配来实现聊天回答。
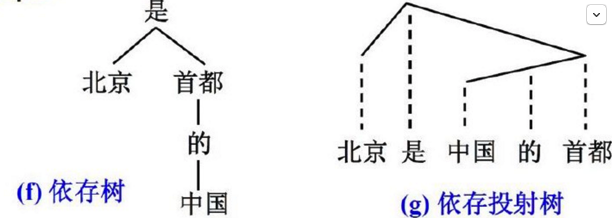
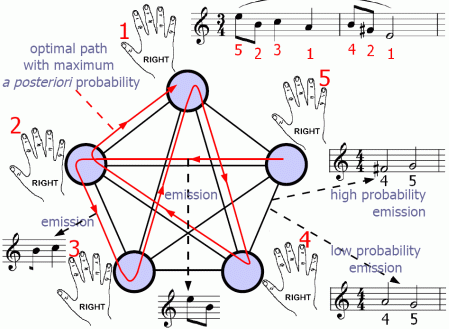
依存句法分析到底是怎么分析的呢? 依存句法分析的基本任务是确定句式的句法结构(短语结构)或句子中词汇之间的依存关系。依存句法分析最重要的两棵树:
依存树:子节点依存于父节点
依存投射树:实线表示依存联结关系,位置低的成分依存于位置高的成分,虚线为投射线
依存关系的五条公理 一个句子中只有一个成分是独立的
其他成分直接依存于某一成分
任何一个成分都不能依存于两个或两个以上的成分
如果A成分直接依存于B成分,而C成分在句子中位于A和B之间,那么C或者直接依存于B,或者直接依存于A和B之间的某一成分
中心成分左右两面的其他成分相互不发生关系
什么地方存在依存关系呢?比如合成词(如:国内)、短语(如:英雄联盟)很多地方都是
LTP依存关系标记 关系 简称 全程 示例 主谓关系 SBV subject-verb 我送她一束花 (我 <– 送) 动宾关系 VOB 直接宾语 verb-object 我送她一束花 (送 –> 花) 间宾关系 IOB 间接宾语 indirect-object 我送她一束花 (送 –> 她) 前置宾语 FOB 前置宾语 fronting-object 他什么书都读 (书 <– 读) 兼语 DBL double 他请我吃饭 (请 –> 我) 定中关系 ATT attribute 红苹果 (红 <– 苹果) 状中结构 ADV adverbial 非常美丽 (非常 <– 美丽) 动补结构 CMP complement 做完了作业 (做 –> 完) 并列关系 COO coordinate 大山和大海 (大山 –> 大海) 介宾关系 POB preposition-object 在贸易区内 (在 –> 内) 左附加关系 LAD left adjunct 大山和大海 (和 <– 大海) 右附加关系 RAD right adjunct 孩子们 (孩子 –> 们) 独立结构 IS independent structure 两个单句在结构上彼此独立 核心关系 HED head 指整个句子的核心
那么依存关系是怎么计算出来的呢? 是通过机器学习和人工标注来完成的,机器学习依赖人工标注,那么都哪些需要我们做人工标注呢?分词词性、依存树库、语义角色都需要做人工标注,有了这写人工标注之后,就可以做机器学习来分析新的句子的依存句法了
LTP云平台怎么用? http://www.ltp-cloud.com/
把语言模型探究到底 无论什么做自然语言处理的工具,都是基于计算机程序实现的,而计算机承担了数学计算的职责,那么自然语言和数学之间的联系就是语言模型,只有理解语言模型才能理解各种工具的实现原理,本节让我们深究语言模型的世界
什么是数学模型 数学模型是运用数理逻辑方法和数学语言建构的科学或工程模型。说白了,就是用数学的方式来解释事实。举个简单的例子:你有一只铅笔,又捡了一只,一共是两只,数学模型就是1+1=2。举个复杂的例子:你在路上每周能捡到3只铅笔,数学模型就是P(X)=3/7,这个数学模型可以帮你预测明天捡到铅笔的可能性。当然解释实事的数学模型不是唯一的,比如每周捡三只铅笔的数学模型还可能是P(qt=sj|qt-1=si,qt-2=sk,…),s=0,1,也就是有两个状态的马尔可夫模型,意思就是明天是否捡到铅笔取决于前几天有没有捡到铅笔
什么是数学建模 数学建模就是通过计算得到的结果来解释实际问题,并接受实际的检验,来建立数学模型的全过程。
什么是语言模型 语言模型是根据语言客观事实而进行的语言抽象数学建模。说白了,就是找到一个数学模型,让它来解释自然语言的事实。
业界认可的语言模型 业界目前比较认可而且有效的语言模型是n元语法模型(n-gram model),它本质上是马尔可夫模型,简单来描述就是:一句话中下一个词的出现和最近n个词有关(包括它自身)。详细解释一下:
如果这里的n=1时,那么最新一个词只和它自己有关,也就是它是独立的,和前面的词没关系,这叫做一元文法
如果这里的n=2时,那么最新一个词和它前面一个词有关,比如前面的词是“我”,那么最新的这个词是“是”的概率比较高,这叫做二元文法,也叫作一阶马尔科夫链
依次类推,工程上n=3用的是最多的,因为n越大约束信息越多,n越小可靠性更高
n元语法模型实际上是一个概率模型,也就是出现一个词的概率是多少,或者一个句子长这个样子的概率是多少。
这就又回到了之前文章里提到的自然语言处理研究的两大方向:基于规则、基于统计。n元语法模型显然是基于统计的方向。
概率是如何统计的 说到基于统计,那么就要说概率是如何估计的了,通常都是使用最大似然估计,怎么样理解“最大似然估计”,最大似然就是最最最最最相似的,那么和谁相似,和历史相似,历史是什么样的?10个词里出现过2次,所以是2/10=1/5,所以经常听说过的“最大似然估计”就是用历史出现的频率来估计概率的方法。这么说就懂了吧?
语言模型都有哪些困难 1. 千变万化的自然语言导致的0概率问题 基于统计的自然语言处理需要基于大量语料库进行,而自然语言千变万化,可以理解所有词汇的笛卡尔积,数量大到无法想象,有限的语料库是难以穷举语言现象的,因此n元语法模型会出现某一句话出现的概率为0的情况,比如我这篇博客在我写出来之前概率就是0,因为我是原创。那么这个0概率的问题如何解决呢?这就是业界不断在研究的数据平滑技术,也就是通过各种数学方式来让每一句话的概率都大于0。具体方法不列举,都是玩数学的,比较简单,无非就是加个数或者减个数或者做个插值平滑一下,效果上应用在不同特点的数据上各有千秋。平滑的方法确实有效,各种自然语言工具中都实现了,直接用就好了。
2. 特定领域的特定词概率偏大问题 每一种领域都会有一些词汇比正常概率偏大,比如计算机领域会经常出现“性能”、“程序”等词汇,这个解决办法可以通过缓存一些刚刚出现过的词汇来提高后面出现的概率来解决。当然这里面是有很多技巧的,我们并不是认为所有出现过的词后面概率都较大,而是会考虑这些词出现的频率和规律(如:词距)来预测。
3. 单一语言模型总会有弊端 还是因为语料库的不足,我们会融合多种语料库,但因为不同语料库之间的差异,导致我们用单一语言模型往往不够准确,因此,有一种方法可以缓和这种不准确性,那就是把多种语言模型混到一起来计算,这其实是一种折中,这种方法low且有效。
还有一种方法就是用多种语言模型来分别计算,最后选择熵最大的一种,这其实也是一种折中,用在哪种地方就让哪种模型生效。
神经网络语言模型 21世纪以来,统计学习领域无论什么都要和深度学习搭个边,毕竟计算机计算能力提升了很多,无论多深都不怕。神经网络语言模型可以看做是一种特殊的模型平滑方式,本质上还是在计算概率,只不过通过深层的学习来得到更正确的概率。
语言模型的应用 这几乎就是自然语言处理的应用了,有:中文分词、机器翻译、拼写纠错、语音识别、音子转换、自动文摘、问答系统、OCR等
探究中文分词的艺术 中文是世界语言界的一朵奇葩,它天生把词连在一起,让计算机望而却步,一句#他说的确实在理#让计算机在#的确#、#实在#、#确实#里面挣扎,但是统计自然语言处理却让计算机有了智能
中文分词是怎么走到今天的 话说上个世纪,中文自动分词还处于初级阶段,每句话都要到汉语词表中查找,有没有这个词?有没有这个词?所以研究集中在:怎么查找最快、最全、最准、最狠……,所以就出现了正向最大匹配法、逆向最大匹配法、双向扫描法、助词遍历法……,用新世纪比较流行的一个词来形容就是:你太low了!
中文自动分词最难的两个问题:1)歧义消除;2)未登陆词识别。说句公道话,没有上个世纪那么low的奠定基础,也就没有这个世纪研究重点提升到这两个高级的问题
ps:未登录词就是新词,词表里没有的词
本世纪计算机软硬件发展迅猛,计算量存储量都不再是问题,因此基于统计学习的自动分词技术成为主流,所以就出现了各种新分词方法,也更适用于新世纪文本特点
从n元语法模型开始说起 上节讲到了n元语法模型,在前n-1个词出现的条件下,下一个词出现的概率是有统计规律的,这个规律为中文自动分词提供了统计学基础,所以出现了这么几种统计分词方法:N-最短路径分词法、基于n元语法模型的分词法
N-最短路径分词法其实就是一元语法模型,每个词成为一元,独立存在,出现的概率可以基于大量语料统计得出,比如“确实”这个词出现概率的0.001(当然这是假设,别当真),我们把一句话基于词表的各种切词结果都列出来,因为字字组合可能有很多种,所以有多个候选结果,这时我们利用每个词出现的概率相乘起来,得到的最终结果,谁最大谁就最有可能是正确的,这就是N-最短路径分词法。
这里的N的意思是说我们计算概率的时候最多只考虑前N个词,因为一个句子可能很长很长,词离得远,相关性就没有那么强了
这里的最短路径其实是传统最短路径的一种延伸,由加权延伸到了概率乘积
而基于n元语法模型的分词法就是在N-最短路径分词法基础上把一元模型扩展成n元模型,也就是统计出的概率不再是一个词的概率,而是基于前面n个词的条件概率
人家基于词,我来基于字 由字构词的分词方法出现可以说是一项突破,发明者也因此得到了各项第一和很多奖项,那么这个著名的分词法是怎么做的呢?
每个字在词语中都有一个构词位置:词首、词中、词尾、单独构词。根据一个字属于不同的构词位置,我们设计出来一系列特征,比如:前一个词、前两个词、前面词长度、前面词词首、前面词词尾、前面词词尾加上当前的字组成的词……
我们基于大量语料库,利用平均感知机分类器对上面特征做打分,并训练权重系数,这样得出的模型就可以用来分词了,句子右边多出来一个字,用模型计算这些特征的加权得分,得分最高的就是正确的分词方法
分词方法纵有千万种,一定有适合你的那一个 分词方法很多,效果上一定是有区别的,基于n元语法模型的方法的优势在于词表里已有的词的分词效果,基于字构词的方法的优势在于未登陆词的识别,因此各有千秋,你适合哪个就用哪个。
异性相吸,优势互补 既然两种分词各有优缺点,那么就把他们结合起来吧,来个插值法折中一下,用过的人都说好
流行分词工具都是用的什么分词方法 jieba中文分词 官方描述:
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分 组合 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法 前两句话是说它是基于词表的分词,最后一句是说它也用了由字构词,所以它结合了两种分词方法
ik分词器 基于词表的最短路径切词
ltp云平台分词 主要基于机器学习框架并部分结合词表的方法
一篇文章读懂拿了图灵奖和诺贝尔奖的概率图模型 概率图模型是概率论和图论的结合,经常见到的贝叶斯网络、马尔可夫模型、最大熵模型、条件随机场都属于概率图模型,这些模型有效的解决了很多实际问题,比如自然语言处理中的词性标注、实体识别等,书里的描述都公式纵横、晦涩难懂,我们不妨试试轻轻松松的来说一说概率图模型
首先我们说说什么是图论 能点进这篇文章说明你一定是有一定数学基础的,所以我做个比喻,你来看看是不是这么回事。糖葫芦吃过吧?几个山楂串在一根杆上,这其实就是一个图。
稍稍正式一点说:图就是把一些孤立的点用线连起来,任何点之间都有可能连着。它区别于树,树是有父子关系,图没有。
再深入一点点:从质上来说,图可以表达的某些事物之间的关联关系,也可以表达的是一种转化关系;从量上来说,它能表达出关联程度,也能表达出转化的可能性大小
图论一般有什么用途呢?著名的七桥问题、四色问题、欧拉定理都是在图论基础上说事儿的
再说说概率论 概率论从中学到大学再到工作中都在学,它原理很简单:投个硬币出现人头的概率是1/2,最常用的就是条件概率P(B|A),联合概率P(A,B),贝叶斯公式:P(B|A)=P(A|B)P(B)/P(A),各种估计方法。
提前解释一下概率图模型里的几个常见词汇 贝叶斯(Bayes):无论什么理论什么模型,只要一提到他,那么里面一定是基于条件概率P(B|A)来做文章的。ps:贝叶斯老爷爷可是18世纪的人物,他的理论到现在还这么火,可见他的影响力绝不下于牛顿、爱因斯坦
马尔可夫(Markov):无论什么理论什么模型,只要一提到他,那么里面一定有一条链式结构或过程,前n个值决定当前这个值,或者说当前这个值跟前n个值有关
熵(entropy):熵有火字旁,本来是一个热力学术语,表示物质系统的混乱状态。延伸数学上表达的是一种不确定性。延伸到信息论上是如今计算机网络信息传输的基础理论,不确定性函数是f(p)=-logp,信息熵H(p)=-∑plogp。提到熵必须要提到信息论鼻祖香农(Shannon)
场(field):只要在数学里见到场,它都是英文里的“域”的概念,也就是取值空间,如果说“随机场”,那么就表示一个随机变量能够赋值的全体空间
再说概率图模型 概率图模型一般是用图来说明,用概率来计算的。所以为了清晰的说明,我们每一种方法我尽量配个图,并配个公式。
首先,为了脑子里有个体系,我们做一个分类,分成有向图模型和无向图模型,顾名思义,就是图里面的边是否有方向。那么什么样的模型的边有方向,而什么样的没方向呢?这个很好想到,有方向的表达的是一种推演关系,也就是在A的前提下出现了B,这种模型又叫做生成式模型。而没有方向表达的是一种“这样就对了”的关系,也就是A和B同时存在就对了,这种模型又叫做判别式模型。生成式模型一般用联合概率计算(因为我们知道A的前提了,可以算联合概率),判别式模型一般用条件概率计算(因为我们不知道前提,所以只能”假设”A条件下B的概率)。生成式模型的代表是:n元语法模型、隐马尔可夫模型、朴素贝叶斯模型等。判别式模型的代表是:最大熵模型、支持向量机、条件随机场、感知机模型等
贝叶斯网络 按照前面说的,提到贝叶斯就是条件概率,所以也就是生成式模型,也就是有向图模型。
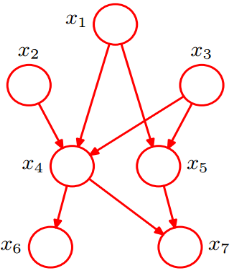
为了说明什么是贝叶斯网络,我从网上盗取一个图
图中每一个点都可能未True或False,他们的概率是已知的,比如x7的概率需要有x4和x5来决定,可能是这样的
x4 x5 T F T T 0.5 0.5 T F 0.4 0.6 F T 0.7 0.3 F F 0.2 0.8
那么可以通过上面的贝叶斯网络来估计如果x1为False情况下x6为True的概率:
P(x6=T|x1=F)=P(x6=T,x1=F)/P(x1=F)
这个值继续推导,最终可以由每个节点的概率数据计算求得,这么说来,贝叶斯网络模型可以通过样本学习来估计每个节点的概率,从而达到可以预测各种问题的结果
贝叶斯网络能够在已知有限的、不完整的、不确定信息条件下进行学习推理,所以广泛应用在故障诊断、维修决策、汉语自动分词、词义消歧等问题上
马尔可夫模型和隐马尔可夫模型 按照前面说的,提到马尔可夫就是一个值跟前面n个值有关,所以也就是条件概率,也就是生成式模型,也就是有向图模型。
继续盗图
音乐的每一个音不是随意作出来的,是根据曲子的风格、和弦、大小调式等来决定的,但是因为可选的音高有多种,也就出现了无数美妙的旋律。因为有约束,所以其实可以说新的音和前面的n个音有关,这其实是一个马尔可夫模型可以解释的事情。
马尔可夫模型还可以看成是一个关于时间t的状态转换过程,也就是随机的有限状态机,那么状态序列的概率可以通过计算形成该序列所有状态之间转移弧上的概率乘积得出。
如果说这个马尔可夫是两阶的,那么转移概率可能是这个样子:
当然后面的概率只是举了个例子,这种情况由前两列决定的第三列任意值都会有一个概率
我们通过训练样本来得出每一个概率值,这样就可以通过训练出的模型来根据前两个音是什么而预测下一个音是1、2、3、4、5任意一个的概率是多少了,也就是可以自动作曲了,当然这样做出的曲子肯定是一个无线循环的旋律,你猜猜为什么。
那么我们再说隐马尔可夫模型,这里的“隐”指的是其中某一阶的信息我们不知道,就像是我们知道人的祖先是三叶虫,但是由三叶虫经历了怎样的演变过程才演变到人的样子我们是不知道的,我们只能通过化石资料了解分布信息,如果这类资料很多,那么就可以利用隐马尔可夫模型来建模,因为缺少的信息较多,所以这一模型的算法比较复杂,比如前向算法、后向算法之类晦涩的东西就不说了。相对于原理,我们更关注它的应用,隐马尔可夫模型广泛应用在词性标注、中文分词等,为什么能用在这两个应用上呢?仔细想一下能看得出来,比如中文分词,最初你是不知道怎么分词的,前面的词分出来了,你才之后后面的边界在哪里,但是当你后面做了分词之后还要验证前面的分词是否正确,这样前后有依赖关系,而不确定中间状态的情况最适合用隐马尔可夫模型来解释
最大熵模型 按照前面所说的,看到熵那么一定会用到H(p)=-∑plogp,怎么理解最大熵模型呢?我们的最终目的是想知道在某一个信息条件B下,得出某种可能的结果A的最大的概率,也就是条件概率P(A|B)最大的候选结果。因为最大熵就是不确定性最大,其实也就是条件概率最大,所以求最大的条件概率等同于求最大熵,而我们这里的熵其实是H(p)=H(A|B)=-∑p(b)p(a|b)log(p(a|b)),为了使用训练数据做估计,这里的p(a|b)可以通过训练数据的某些特征来估计,比如这些特征是fi(a,b),那么做模型训练的过程就编程了训练∑λf(a,b)中的λ参数的过程,至此就有些像机器学习的线性回归了,该怎么做就清晰了。所以其实最大熵模型就是利用熵的原理和熵的公式来用另外一种形式来描述具有概率规律的现实的
条件随机场 场表示取值范围,随机场表示随机变量有取值范围,也就是每个随机变量有固定的取值,条件指的是随机变量的取值由一定的条件概率决定,而这里的条件来自于我们有一些观察值,这是它区别于其他随机场的地方。条件随机场也可以看做是一个无向图模型,它特殊就特殊在给定观察序列X时某个特定的标记序列Y的概率是一个指数函数exp(∑λt+∑μs),其中t是转移函数,s是状态函数,我们需要训练的是λ和μ。条件随机场主要应用在标注和切分有序数据上,尤其在自然语言处理、生物信息学、机器视觉、网络智能等方面
总结一下,概率图模型包括多种结合概率论和图论的模型,根据特定场景特定需求选择不同的模型,每种模型的参数都需要大量样本训练得出,每种模型都是用来根据训练出来的概率做最优结论选择的,比如根据训练出来的模型对句子做最正确的词性标注、实体标注、分词序列等,本文只是从理念上的解释和总结,真的用到某一种模型还是需要深入研究原理和公式推导以及编程实现,那就不是本文这种小篇幅能够解释的完的了,等我们后面要遇到必须用某一种模型来实现时再狠狠地深入一下。
大话自然语言处理中的囊中取物 大数据风靡的今天,不从里面挖出点有用的信息都不好意思见人,人工智能号称跨过奇点,统霸世界,从一句话里都识别不出一个命名实体?不会的,让我们大话自然语言处理的囊中取物,看看怎么样能让计算机像人一样看出一句话里哪个像人、哪个像物
话说天下大事,分久必合,合久必分。 之前谈到中文分词把文本切分成一个一个词语,现在我们要反过来,把该拼一起的词再拼到一起,找到一个命名实体,比如:“亚太经合组织”
条件随机场的用武之地 上回书说到,概率图模型中的条件随机场适用于在一定观测值条件下决定的随机变量有有限个取值的情况,它特殊就特殊在给定观察序列X时某个特定的标记序列Y的概率是一个指数函数exp(∑λt+∑μs),这也正符合最大熵原理。基于条件随机场的命名实体识别方法属于有监督的学习方法,需要利用已经标注好的大规模语料库进行训练,那么已经标注好的语料里面有什么样的特征能够让模型得以学习呢?
谈命名实体的放射性 为什么说命名实体是有放射性的呢?举个栗子:“中国积极参与亚太经合组织的活动”,这里面的“亚太经合组织”是一个命名实体,定睛一瞧,这个实体着实不凡啊,有“组织”两个字,这么说来这个实体是一种组织或机构,记住,下一次当你看到“组织”的时候和前面几个字组成的一定是一个命名实体。继续观察,在它之前辐射出了“参与”一次,经过大规模语料训练后能发现,才“参与”后面有较大概率跟着一个命名实体。继续观察,在它之后有“的活动”,那么说明前面很可能是一个组织者,组织者多半是一个命名实体。这就是基于条件随机场做命名实体识别的奥秘,这就是命名实体的放射性
特征模板 前面讲了放射性,那么设计特征模板就比较容易了,我们采用当前位置的前后n个位置上的字/词/字母/数字/标点等作为特征,因为是基于已经标注好的语料,所以这些特征是什么样的词性、词形都是已知的。
特征模板的选择是和具体我们要识别的实体类别有关系的,识别人名和识别机构名用的特征模板是不一样的,因为他们的特点就不一样,事实上识别中文人名和识别英文人名用的特征模板也是不一样的,因为他们的特点就不一样
且说命名实体 前面讲了一揽子原理,回过头来讲讲命名实体是什么,命名实体包括:人名(政治家、艺人等)、地名(城市、州、国家、建筑等)、组织机构名、时间、数字、专有名词(电影名、书名、项目名、电话号码等)、……。其实领域很多,不同人需求不一样,关注的范围也不一样。总之不外乎命名性指称、名词性指称和代词性指称
自古英雄周围总有谋士 基于条件随机场的命名实体方法虽好,但如何利用好还是需要各路谋士献计献策。有的人提出通过词形上下文训练模型,也就是给定词形上下文语境中产生实体的概率;有的人提出通过词性上下文训练模型,也就是给定词性上下文语境中产生实体的概率;有的人提出通过给定实体的词形串作为实体的概率;有的人提出通过给定实体的词性串作为实体的概率;当大家发现这四点总有不足时,有谋士提出:把四个结合起来!这真是:英雄代有人才出,能摆几出摆几出啊
语料训练那些事儿 语料训练那些事儿,且看我机器学习教程相关文章《机器学习精简入门教程》,预知后事如何,下回我也不分解了
让机器做词性自动标注的具体方法 分词、命名实体识别和词性标注这三项技术如果达不到很高的水平,是难以建立起高性能的自然语言处理系统,也就难以实现高质量的聊天机器人,而词性是帮助计算机理解语言含义的关键,本节来介绍一些词性标注的具体方法
何为词性 常说的词性包括:名、动、形、数、量、代、副、介、连、助、叹、拟声。但自然语言处理中要分辨的词性要更多更精细,比如:区别词、方位词、成语、习用语、机构团体、时间词等,多达100多种。
汉语词性标注最大的困难是“兼类”,也就是一个词在不同语境中有不同的词性,而且很难从形式上识别。
词性标注过程 为了解决词性标注无法达到100%准确的问题,词性标注一般要经过“标注”和“校验”两个过程,第一步“标注”根据规则或统计的方法做词性标注,第二步“校验”通过一致性检查和自动校对等方法来修正。
词性标注的具体方法 词性标注具体方法包括:基于统计模型的方法、基于规则的方法和两者结合的方法。下面我们分别来介绍。
基于统计模型的词性标注方法 提到基于统计模型,势必意味着我们要利用大量已经标注好的语料库来做训练,同时要先选择一个合适的训练用的数学模型,《自己动手做聊天机器人 十五-一篇文章读懂拿了图灵奖和诺贝尔奖的概率图模型》中我们介绍了概率图模型中的隐马尔科夫模型(HMM)比较适合词性标注这种基于观察序列来做标注的情形。语言模型选择好了,下面要做的就是基于语料库来训练模型参数,那么我们模型参数初值如何设置呢?这里面就有技巧了
隐马尔可夫模型参数初始化的技巧 模型参数初始化是在我们尚未利用语料库之前用最小的成本和最接近最优解的目标来设定初值。HMM是一种基于条件概率的生成式模型,所以模型参数是生成概率,那么我们不妨就假设每个词的生成概率就是它所有可能的词性个数的倒数,这个是计算最简单又最有可能接近最优解的生成概率了。每个词的所有可能的词性是我们已经有的词表里标记好的,这个词表的生成方法就比较简单了,我们不是有已经标注好的语料库嘛,很好统计。那么如果某个词在词表里没有呢?这时我们可以把它的生成概率初值设置为0。这就是隐马尔可夫模型参数初始化的技巧,总之原则就是用最小的成本和最接近最优解的目标来设定初值。一旦完成初始值设定后就可以利用前向后向算法进行训练了。
基于规则的词性标注方法 规则就是我们既定好一批搭配关系和上下文语境的规则,判断实际语境符合哪一种则按照规则来标注词性。这种方法比较古老,适合于既有规则,对于兼词的词性识别效果较好,但不适合于如今网络新词层出不穷、网络用语新规则的情况。于是乎,有人开始研究通过机器学习来自动提取规则,怎么提取呢?不是随便给一堆语料,它直接来生成规则,而是根据初始标注器标注出来的结果和人工标注的结果的差距,来生成一种修正标注的转换规则,这是一种错误驱动的学习方法。基于规则的方法还有一个好处在于:经过人工校总结出的大量有用信息可以补充和调整规则库,这是统计方法做不到的。
统计方法和规则方法相结合的词性标注方法 统计方法覆盖面比较广,新词老词通吃,常规非常规通吃,但对兼词、歧义等总是用经验判断,效果不好。规则方法对兼词、歧义识别比较擅长,但是规则总是覆盖不全。因此两者结合再好不过,先通过规则排歧,再通过统计标注,最后经过校对,可以得到正确的标注结果。在两者结合的词性标注方法中,有一种思路可以充分发挥两者优势,避免劣势,就是首选统计方法标注,同时计算计算它的置信度或错误率,这样来判断是否结果是否可疑,在可疑情况下采用规则方法来进行歧义消解,这样达到最佳效果。
词性标注的校验 做完词性标注并没有结束,需要经过校验来确定正确性以及修正结果。
第一种校验方法就是检查词性标注的一致性。一致性指的是在所有标注的结果中,具有相同语境下同一个词的标注是否都相同,那么是什么原因导致的这种不一致呢?一种情况就是这类词就是兼类词,可能被标记为不同词性。另一种情况是非兼类词,但是由于人工校验或者其他原因导致标记为不同词性。达到100%的一致性是不可能的,所以我们需要保证一致性处于某个范围内,由于词数目较多,词性较多,一致性指标无法通过某一种计算公式来求得,因此可以基于聚类和分类的方法,根据欧式距离来定义一致性指标,并设定一个阈值,保证一致性在阈值范围内。
第二种校验方法就是词性标注的自动校对。自动校对顾名思义就是不需要人参与,直接找出错误的标注并修正,这种方法更适用于一个词的词性标注通篇全错的情况,因为这种情况基于数据挖掘和规则学习方法来做判断会相对比较准确。通过大规模训练语料来生成词性校对决策表,然后根据这个决策表来找通篇全错的词性标注并做自动修正。
总结 词性标注的方法主要有基于统计和基于规则的方法,另外还包括后期校验的过程。词性标注是帮助计算机理解语言含义的关键,有了词性标注,我们才可以进一步确定句法和语义,才有可能让机器理解语言的含义,才有可能实现聊天机器人的梦想
神奇算法之句法分析树的生成 把一句话按照句法逻辑组织成一棵树,由人来做这件事是可行的,但是由机器来实现是不可思议的,然而算法世界就是这么神奇,把一个十分复杂的过程抽象成仅仅几步操作,甚至不足10行代码,就能让机器完成需要耗费人脑几十亿脑细胞的工作,本文我们来见识一下神奇的句法分析树生成算法
句法分析 先来解释一下句法分析。句法分析分为句法结构分析和依存关系分析。
句法结构分析也就是短语结构分析,比如提取出句子中的名次短语、动词短语等,最关键的是人可以通过经验来判断的短语结构,那么怎么由机器来判断呢?
(有关依存关系分析的内容,具体可以看《自己动手做聊天机器人 十二-教你如何利用强大的中文语言技术平台做依存句法和语义依存分析》)
句法分析树 样子如下:
句法结构分析基本方法 分为基于规则的分析方法和基于统计的分析方法。基于规则的方法存在很多局限性,所以我们采取基于统计的方法,目前最成功的是基于概率上下文无关文法(PCFG)。基于PCFG分析需要有如下几个要素:终结符集合、非终结符集合、规则集。
相对于先叙述理论再举实例的传统讲解方法,我更倾向于先给你展示一个简单的例子,先感受一下计算过程,然后再叙述理论,这样会更有趣。
例子是这样的:我们的终结符集合是:∑={我, 吃, 肉,……},这个集合表示这三个字可以作为句法分析树的叶子节点,当然这个集合里还有很多很多的词
我们的非终结符集合是:N={S, VP, ……},这个集合表示树的非页子节点,也就是连接多个节点表达某种关系的节点,这个集合里也是有很多元素
我们的规则集:R={
NN->我 0.5
Vt->吃 1.0
NN->肉 0.5
VP->Vt NN 1.0
S->NN VP 1.0
……
}
这里的句法规则符号可以参考词性标注,后面一列是模型训练出来的概率值,也就是在一个固定句法规则中NN的位置是“我”的概率是0.5,NN推出“肉”的概率是0.5,0.5+0.5=1,也就是左部相同的概率和一定是1。不知道你是否理解了这个规则的内涵
再换一种方法解释一下,有一种句法规则是:
1
2
3
4
5
S——|
| |
NN VP
|——|
Vt NN
其中NN的位置可能是“我”,也可能是“肉”,是“我”的概率是0.5,是“肉”的概率是0.5,两个概率和必为1。其中Vt的位置一定是“吃”,也就是概率是1.0……。这样一说是不是就理解了?
规则集里实际上还有很多规则,只是列举出会用到的几个
以上的∑、N、R都是经过机器学习训练出来的数据集及概率,具体训练方法下面我们会讲到
那么如何根据以上的几个要素来生成句法分析树呢?
(1)“我”
词性是NN,推导概率是0.5,树的路径是“我”
(2)“吃”
词性是Vt,推导概率是1.0,树的路径是“吃”
(3)“肉”
词性是NN,概率是0.5,和Vt组合符合VP规则,推导概率是0.51.0 1.0=0.5,树的路径是“吃肉”
NN和VP组合符合S规则,推导概率是0.50.5 1.0=0.25,树的路径是“我吃肉”
所以最终的树结构是:
1
2
3
4
5
6
S——|
| |
NN VP
我 |——|
Vt NN
吃 肉
上面的例子是比较简单的,实际的句子会更复杂,但是都是通过这样的动态规划算法完成的
提到动态规划算法,就少不了“选择”的过程,一句话的句法结构树可能有多种,我们只选择概率最大的那一种作为句子的最佳结构,这也是“基于概率”上下文无关文法的名字起源。
上面的计算过程总结起来就是:设W={ω1ω2ω3……}表示一个句子,其中的ω表示一个词(word),利用动态规划算法计算非终结符A推导出W中子串ωiωi+1ωi+2……ωj的概率,假设概率为αij(A),那么有如下递归公式:
αij(A)=P(A->ωi)
αij(A)=∑∑P(A->BC)αik(B)α(k+1)j(C)
以上两个式子好好理解一下其实就是上面“我吃肉”的计算过程
以上过程理解了之后你一定会问,这里面最关键的的非终结符、终结符以及规则集是怎么得来的,概率又是怎么确定的?下面我们就来说明
句法规则提取方法与PCFG的概率参数估计 这部分就是机器学习的知识了,有关机器学习可以参考《机器学习教程》
首先我们需要大量的树库,也就是训练数据。然后我们把树库中的句法规则提取出来生成我们想要的结构形式,并进行合并、归纳等处理,最终得到上面∑、N、R的样子。其中的概率参数计算方法是这样的:
先给定参数为一个随机初始值,然后采用EM迭代算法,不断训练数据,并计算每条规则使用次数作为最大似然计算得到概率的估值,这样不断迭代更新概率,最终得出的概率可以认为是符合最大似然估计的精确值。
总结一下 句法分析树生成算法是基于统计学习的原理,根据大量标注的语料库(树库),通过机器学习算法得出非终结符、终结符、规则集及其概率参数,然后利用动态规划算法生成每一句话的句法分析树,在句法分析树生成过程中如果遇到多种树结构,选择概率最大的那一种作为最佳句子结构
机器人是怎么理解“日后再说”的 日后再说这个成语到了当代可以说含义十分深刻,你懂的,但是如何让计算机懂得可能有两种含义的一个词到底是想表达哪个含义呢?这在自然语言处理中叫做词义消歧,从本节开始我们从基本的结构分析跨入语义分析,开始让计算机对语言做深层次的理解
词义消歧 词义消歧是句子和篇章语义理解的基础,是必须解决的问题。任何一种语言都有大量具有多种含义的词汇,中文的“日”,英文的“bank”,法语的“prendre”……。
词义消歧可以通过机器学习的方法来解决。谈到机器学习就会分成有监督和无监督的机器学习。词义消歧有监督的机器学习方法也就是分类算法,即判断词义所属的分类。词义消歧无监督的机器学习方法也就是聚类算法,把词义聚成多类,每一类是一种含义。
有监督的词义消歧方法 基于互信息的词义消歧方法 这个方法的名字不好理解,但是原理却非常简单:用两种语言对照着看,比如:中文“打人”对应英文“beat a man”,而中文“打酱油”对应英文“buy some sauce”。这样就知道当上下文语境里有“人”的时候“打”的含义是beat,当上下文语境里有“酱油”的时候“打”的含义是buy。按照这种思路,基于大量中英文对照的语料库训练出来的模型就可以用来做词义消歧了,这种方法就叫做基于“互信息”的词义消歧方法。讲到“互信息”还要说一下它的起源,它来源于信息论,表达的是一个随机变量中包含另一个随机变量的信息量(也就是英文信息中包含中文信息的信息量),假设两个随机变量X、Y的概率分别是p(x), p(y),它们的联合分布概率是p(x,y),那么互信息计算公式是:
1
I(X; Y) = ∑∑p(x,y)log(p(x,y)/(p(x)p(y)))
以上公式是怎么推导出来的呢?比较简单,“互信息”可以理解为一个随机变量由于已知另一个随机变量而减少的不确定性(也就是理解中文时由于已知了英文的含义而让中文理解更确定了),因为“不确定性”就是熵所表达的含义,所以:
等式后面经过不断推导就可以得出上面的公式,对具体推导过程感兴趣可以百度一下。
那么我们在对语料不断迭代训练过程中I(X; Y)是不断减小的,算法终止的条件就是I(X; Y)不再减小。
基于互信息的词义消歧方法自然对机器翻译系统的效果是最好的,但它的缺点是:双语语料有限,多种语言能识别出歧义的情况也是有限的(比如中英文同一个词都有歧义就不行了)。
基于贝叶斯分类器的消歧方法 提到贝叶斯那么一定少不了条件概率,这里的条件指的就是上下文语境这个条件,任何多义词的含义都是跟上下文语境相关的。假设语境(context)记作c,语义(semantic)记作s,多义词(word)记作w,那么我要计算的就是多义词w在语境c下具有语义s的概率,即:
p(s|c)
那么根据贝叶斯公式:
p(s|c) = p(c|s)p(s)/p(c)
我要计算的就是p(s|c)中s取某一个语义的最大概率,因为p(c)是既定的,所以只考虑分子的最大值:
s的估计=max(p(c|s)p(s))
因为语境c在自然语言处理中必须通过词来表达,也就是由多个v(词)组成,那么也就是计算:
max(p(s)∏p(v|s))
下面就是训练的过程了:
p(s)表达的是多义词w的某个语义s的概率,可以统计大量语料通过最大似然估计求得:
p(s) = N(s)/N(w)
p(v|s)表达的是多义词w的某个语义s的条件下出现词v的概率,可以统计大量语料通过最大似然估计求得:
p(v|s) = N(v, s)/N(s)
训练出p(s)和p(v|s)之后我们对一个多义词w消歧的过程就是计算(p(c|s)p(s))的最大概率的过程
无监督的词义消歧方法 完全无监督的词义消歧是不可能的,因为没有标注是无法定义是什么词义的,但是可以通过无监督的方法来做词义辨识。无监督的词义辨识其实也是一种贝叶斯分类器,和上面讲到的贝叶斯分类器消歧方法不同在于:这里的参数估计不是基于有标注的训练预料,而是先随机初始化参数p(v|s),然后根据EM算法重新估计这个概率值,也就是对w的每一个上下文c计算p(c|s),这样可以得到真实数据的似然值,回过来再重新估计p(v|s),重新计算似然值,这样不断迭代不断更新模型参数,最终得到分类模型,可以对词进行分类,那么有歧义的词在不同语境中会被分到不同的类别里。
仔细思考一下这种方法,其实是基于单语言的上下文向量的,那么我们进一步思考下一话题,如果一个新的语境没有训练模型中一样的向量怎么来识别语义?
这里就涉及到向量相似性的概念了,我们可以通过计算两个向量之间夹角余弦值来比较相似性,即:
cos(a,b) = ∑ab/sqrt(∑a^2∑b^2)
机器人是怎么理解“日后再说”的 回到最初的话题,怎么让机器人理解“日后再说”,这本质上是一个词义消歧的问题,假设我们利用无监督的方法来辨识这个词义,那么就让机器人“阅读”大量语料进行“学习”,生成语义辨识模型,这样当它听到这样一则对话时:
有一位老嫖客去找小姐,小姐问他什么时候结账啊。嫖客说:“钱的事情日后再说。”就开始了,完事后,小姐对嫖客说:“给钱吧。”嫖客懵了,说:“不是说日后再说吗?”小姐说:“是啊,你现在不是已经日后了吗?”
辨识了这里的“日后再说”的词义后,它会心的笑了
语义角色标注的基本方法 浅层语义标注是行之有效的语言分析方法,基于语义角色的浅层分析方法可以描述句子中语义角色之间的关系,是语义分析的重要方法,也是篇章分析的基础,本节介绍基于机器学习的语义角色标注方法
语义角色 举个栗子:“我昨天吃了一块肉”,按照常规理解“我吃肉”应该是句子的核心,但是对于机器来说“我吃肉”实际上已经丢失了非常多的重要信息,没有了时间,没有了数量。为了让机器记录并提取出这些重要信息,句子的核心并不是“我吃肉”,而是以谓词“吃”为核心的全部信息。
“吃”是谓词,“我”是施事者,“肉”是受事者,“昨天”是事情发生的时间,“一块”是数量。语义角色标注就是要分析出这一些角色信息,从而可以让计算机提取出重要的结构化信息,来“理解”语言的含义。
语义角色标注的基本方法 语义角色标注需要依赖句法分析的结果进行,因为句法分析包括短语结构分析、浅层句法分析、依存关系分析,所以语义角色标注也分为:基于短语结构树的语义角色标注方法、基于浅层句法分析结果的语义角色标注方法、基于依存句法分析结果的语义角色标注方法。但无论哪种方法,过程都是:
句法分析->候选论元剪除->论元识别->论元标注->语义角色标注结果
其中论元剪除就是在较多候选项中去掉肯定不是论元的部分
其中论元识别是一个二值分类问题,即:是论元和不是论元
其中论元标注是一个多值分类问题
下面分别针对三种方法分别说明这几个过程的具体方法
基于短语结构树的语义角色标注方法 短语结构树是这样的结构:
1
2
3
4
5
6
S——|
| |
NN VP
我 |——|
Vt NN
吃 肉
短语结构树里面已经表达了一种结构关系,因此语义角色标注的过程就是依赖于这个结构关系来设计的一种复杂策略,策略的内容随着语言结构的复杂而复杂化,因此我们举几个简单的策略来说明。
首先我们分析论元剪除的策略:
因为语义角色是以谓词为中心的,因此在短语结构树中我们也以谓词所在的节点为中心,先平行分析,比如这里的“吃”是谓词,和他并列的是“肉”,明显“肉”是受事者,那么设计什么样的策略能使得它成为候选论元呢?我们知道如果“肉”存在一个短语结构的话,那么一定会多处一个树分支,那么“肉”和“吃”一定不会在树的同一层,因此我们设计这样的策略来保证“肉”被选为候选论元:如果当前节点的兄弟节点和当前节点不是句法结构的并列关系,那么将它作为候选论元。当然还有其他策略不需要记得很清楚,现用现查就行了,但它的精髓就是基于短语结构树的结构特点来设计策略的。
然后就是论元识别过程了。论元识别是一个二值分类问题,因此一定是基于标注的语料库做机器学习的,机器学习的二值分类方法都是固定的,唯一的区别就是特征的设计,这里面一般设计如下特征效果比较好:谓词本身、短语结构树路径、短语类型、论元在谓词的位置、谓词语态、论元中心词、从属类别、论元第一个词和最后一个词、组合特征。
论元识别之后就是论元标注过程了。这又是一个利用机器学习的多值分类器进行的,具体方法不再赘述。
基于依存句法分析结果和基于语块的语义角色标注方法 这两种语义角色标注方法和基于短语结构树的语义角色标注方法的主要区别在于论元剪除的过程,原因就是他们基于的句法结构不同。
基于依存句法分析结果的语义角色标注方法会基于依存句法直接提取出谓词-论元关系,这和依存关系的表述是很接近的,因此剪除策略的设计也就比较简单:以谓词作为当前节点,当前节点所有子节点都是候选论元,将当前节点的父节点作为当前节点重复以上过程直至到根节点为止。
基于依存句法分析结果的语义角色标注方法中的论元识别算法的特征设计也稍有不同,多了有关父子节点的一些特征。
有了以上几种语义角色标注方法一定会各有优缺点,因此就有人想到了多种方法相融合的方法,融合的方式可以是:加权求和、插值……,最终效果肯定是更好,就不多说了。
多说几句 语义角色标注当前还是不是非常有效,原因有诸多方面,比如:依赖于句法分析的准确性、领域适应能力差。因此不断有新方法来解决这些问题,比如说可以利用双语平行语料来弥补准确性的问题,中文不行英文来,英文不行法语来,反正多多益善,这确实有助于改进效果,但是成本提高了许多。语义角色标注还有一段相当长的路要走,希望学术界研究能不断开花结果吧
比TF-IDF更好的隐含语义索引模型是个什么鬼 我曾经的一篇文章曾说到0字节存储海量语料资源,那么从海量语料资源中找寻信息需要依赖于信息检索的方法,信息检索无论是谷歌还是百度都离不开TF-IDF算法,但TF-IDF是万能的吗?并不是,它简单有效但缺乏语义特征,本节介绍比TF-IDF还牛逼的含有语义特征的信息检索方法
TF-IDF TF(term frequency),表示一个词在一个文档中出现的频率;IDF(inverse document frequency),表示一个词出现在多少个文档中。
它的思路是这样的:同一个词在短文档中出现的次数和在长文档中出现的次数一样多时,对于短文档价值更大;一个出现概率很低的词一旦出现在文档中,其价值应该大于其他普遍出现的词。
这在信息检索领域的向量模型中做相似度计算非常有效,屡试不爽,曾经是google老大哥发家的必杀技。但是在开发聊天机器人这个事情上看到了它的软肋,那就是它只是考虑独立的词上的事情,并没有任何语义信息在里面,因此我们需要选择加入了语义特征的更有效的信息检索模型。
隐含语义索引模型 在TF-IDF模型中,所有词构成一个高维的语义空间,每个文档在这个空间中被映射为一个点,这种方法维数一般比较高而且每个词作为一维割裂了词与词之间的关系。所以为了解决这个问题,我们要把词和文档同等对待,构造一个维数不高的语义空间,每个词和每个文档都是被映射到这个空间中的一个点。用数学来表示这个思想就是说,我们考察的概率即包括文档的概率,也包括词的概率,以及他们的联合概率。
为了加入语义方面的信息,我们设计一个假想的隐含类包括在文档和词之间,具体思路是这样的:
(1)选择一个文档的概率是p(d);
(2)找到一个隐含类的概率是p(z|d);
(3)生成一个词w的概率为p(w|z);
以上是假设的条件概率,我们根据观测数据能估计出来的是p(d, w)联合概率,这里面的z是一个隐含变量,表达的是一种语义特征。那么我们要做的就是利用p(d, w)来估计p(d)、p(z|d)和p(w|z),最终根据p(d)、p(z|d)和p(w|z)来求得更精确的p(w, d),即词与文档之间的相关度。
为了做更精确的估计,设计优化的目标函数是对数似然函数:
L=∑∑n(d, w) log P(d, w)
那么如何来通过机器学习训练这些概率呢?首先我们知道:
p(d, w) = p(d) × p(w|d)
而
p(w|d) = ∑p(w|z)p(z|d)
同时又有:
p(z|d) = p(z)p(d|z)/∑p(z)p(d|z)
那么
p(d, w) =p(d)×∑p(w|z) p(z)p(d|z)/∑p(z)p(d|z)=∑p(z)×p(w|z)×p(d|z)
下面我们采取EM算法,EM算法的精髓就是按照最大似然的原理,先随便拍一个分布参数,让每个人都根据分布归类到某一部分,然后根据这些归类来重新统计数目,按照最大似然估计分布参数,然后再重新归类、调参、估计、归类、调参、估计,最终得出最优解
那么我们要把每一个训练数据做归类,即p(z|d,w),那么这个概率值怎么计算呢?
我们先拍一个p(z)、p(d|z)、p(w|z)
然后根据
p(z|d,w)=p(z)p(d|z)p(w|z)/∑p(z)p(d|z)p(w|z),其中分子是一个z,分母是所有的z的和
这样计算出来的值是p(z|d,w)的最大似然估计的概率估计(这是E过程)
然后根据这个估计来对每一个训练样本做归类
根据归类好的数据统计出n(d,w)
然后我再根据以下公式来更新参数
p(z) = 1/R ∑n(d,w)p(z|d,w)
p(d|z)=∑n(d,w)p(z|d,w) / ∑n(d,w)p(z|d,w),其中分子是一个d的和,分母是所有的d的和,这样计算出来的值是p(d|z)的最大似然估计
p(w|z)=∑n(d,w)p(z|d,w) / ∑n(d,w)p(z|d,w),其中分子是一个w的和,分母是所有的w的和,这样计算出来的值是p(w|z)的最大似然估计
最后重新计算p(z|d,w):
p(z|d,w)=p(z)p(d|z)p(w|z)/∑p(z)p(d|z)p(w|z)
这是M的过程
不断重复上面EM的过程使得对数似然函数最大:
L=∑∑n(d, w) log P(d, w)
通过以上迭代就能得出最终的p(w, d),即词与文档之间的相关度,后面就是利用相关度做检索的过程了
为了得到词词之间的相关度,我们用p(w, d)乘以它的转置,即
p(w,w) = p(w,d)×trans(p(w,d))
当用户查询query的关键词构成词向量Wq, 而文档d表示成词向量Wd,那么query和文档d的相关度就是:
R(query, d) = Wq×p(w,w)×Wd
这样把所有文档算出来的相关度从大到小排序就是搜索的排序结果
总结 综上就是隐含语义索引模型的内容,相比TF-IDF来说它加进了语义方面的信息、考虑了词与词之间的关系,是根据语义做信息检索的方法,更适合于研发聊天机器人做语料训练和分析,而TF-IDF更适合于完全基于独立的词的信息检索,更适合于纯文本搜索引擎
神奇算法之人工神经网络 深度学习是机器学习中较为流行的一种,而深度学习的基础是人工神经网络,那么人工神经网络的功能是不是像它的名字一样神奇呢?答案是肯定的,让我们一起见证一下这一神奇算法
人工神经网络 人工神经网络是借鉴了生物神经网络的工作原理形成的一种数学模型,有关人工神经网络的原理、公式推导以及训练过程请见我的文章《机器学习教程 十二-神经网络模型的原理》
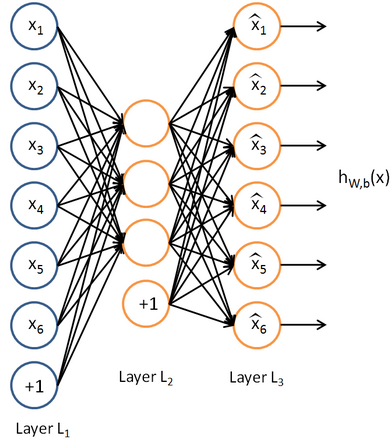
神奇用法之一 我们这样来设计我们的神经网络:由n个输入特征得出与输入特征几乎相同的n个结果,这样训练出的隐藏层可以得到意想不到的信息。
比如,在信息检索领域,我们需要通过模型训练来得出合理的排序模型,那么输入的特征可能有:文档质量、文档点击历史、文档前链数目、文档锚文本信息……,为了能找出这些特征中隐藏的信息,我们把隐藏层的神经元数目设置的少于输入特征的数目,经过大量样本的训练出能还原原始特征的模型,这样相当于我们用少于输入特征数目的信息还原出了全部特征,表面上是一种压缩,实际上通过这种方式就可以发现某些特征之间存在隐含的相关性,或者有某种特殊的关系。
同样的,我们还可以让隐藏层中的神经元数目多余输入特征的数目,这样经过训练得出的模型还可以展示出特征之间某种细节上的关联,比如我们对图像识别做这样的模型训练,在得出的隐藏层中能展示出多种特征之间的细节信息,如鼻子一定在嘴和眼睛中间。
这种让输出和输入一致的用法就是传说中的自编码算法。
神奇用法之二 人工神经网络模型通过多层神经元结构建立而成,每一层可以抽象为一种思维过程,经过多层思考,最终得出结论。举一个实际的例子:识别美女图片
按照人的思维过程,识别美女图片要经过这样的判断:1)图片类别(人物、风景……);2)图片人物性别(男、女、其他……);3)相貌如何(美女、恐龙、5分……)
那么在人工神经网络中,这个思考过程可以抽象成多个层次的计算:第一层计算提取图片中有关类别的特征,比如是否有形如耳鼻口手的元素,是否有形如蓝天白云绿草地的元素;第二层提取是否有胡须、胸部、长发以及面部特征等来判断性别;第三层提取五官、肤质、衣着等信息来确定颜值。为了让神经网络每一层有每一层专门要做的事情,需要在每一层的神经元中添加特殊的约束条件才能做到。人类的大脑是经过上亿年进化而成的,它的功能深不可及,某些效率也极高,而计算机在某些方面效率比人脑要高很多,两种结合起来一切皆有可能。
这种通过很多层提取特定特征来做机器学习的方法就是传说中的深度学习。
神奇用法之三 讲述第三种用法之前我们先讲一下什么是卷积运算。卷积英文是convolution(英文含义是:盘绕、弯曲、错综复杂),数学表达是:
数学上不好理解,我们可以通俗点来讲:卷积就相当于在一定范围内做平移并求平均值。比如说回声可以理解为原始声音的卷积结果,因为回声是原始声音经过很多物体反射回来声音揉在一起。再比如说回声可以理解为把信号分解成无穷多的冲击信号,然后再进行冲击响应的叠加。再比如说把一张图像做卷积运算,并把计算结果替换原来的像素点,可以实现一种特殊的模糊,这种模糊其实是一种新的特征提取,提取的特征就是图像的纹路。总之卷积就是先打乱,再叠加。
下面我们在看上面的积分公式,需要注意的是这里是对τ积分,不是对x积分。也就是说对于固定的x,找到x附近的所有变量,求两个函数的乘积,并求和。
下面回归正题,在神经网络里面,我们设计每个神经元计算输出的公式是卷积公式,这样相当于神经网络的每一层都会输出一种更高级的特征,比如说形状、脸部轮廓等。这种神经网络叫做卷积神经网络。
继续深入主题,在自然语言中,我们知道较近的上下文词语之间存在一定的相关性,由于标点、特殊词等的分隔使得在传统自然语言处理中会脱离词与词之间的关联,结果丢失了一部分重要信息,利用卷积神经网络完全可以做多元(n-gram)的计算,不会损失自然语言中的临近词的相关性信息。这种方法对于语义分析、语义聚类等都有非常好的效果。
这种神奇用法就是传说中的CNN
总结 神经网络因为其层次和扩展性的强大,有着非常多的神奇用法和非常广泛的应用,因为希望聊天机器人能够具有智能,就不得不寻找能够承载智能的方法,神经网络是其中一个,沿着这个网络,让我们继续探索。
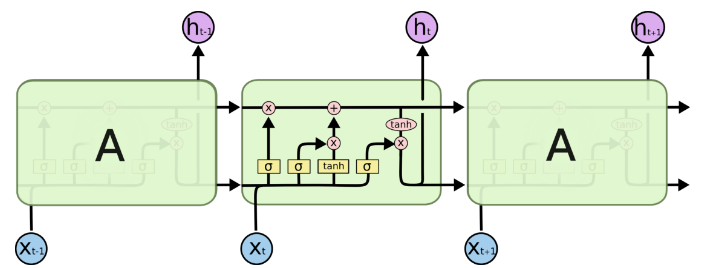
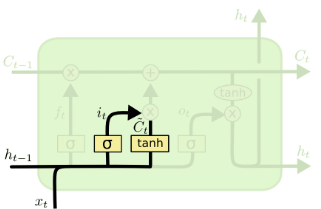
用CNN做深度学习 自动问答系统中深度学习的应用较多是RNN,这归因于它天然利用时序建模。俗话说知己知彼百战不殆,为了理解RNN,我们先来了解一下CNN,通过手写数字识别案例来感受一下CNN最擅长的局部感知能力
卷积神经网络(CNN) 卷积神经网络(Convolutional Neural Network,CNN)是将二维离散卷积运算和人工神经网络相结合的一种深度神经网络。它的特点是可以自动提取特征。有关卷积神经网络的数学原理和训练过程请见我的另一篇文章《机器学习教程 十五-细解卷积神经网络》。
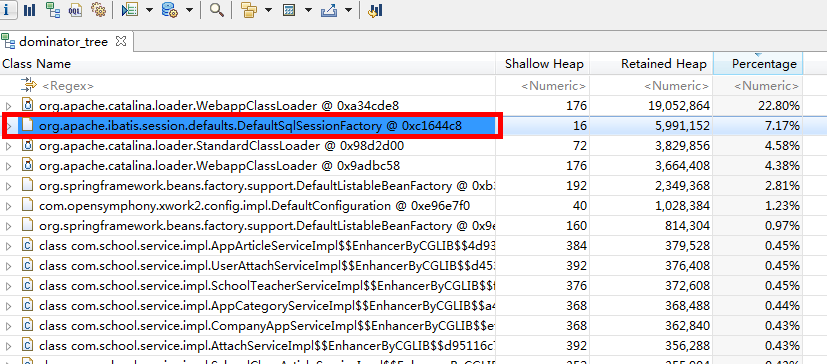
手写数字识别 为了试验,我们直接采用http://yann.lecun.com/exdb/mnist/中的手写数据集,下载到的手写数据集数据文件是用二进制以像素为单位保存的几万张图片文件,通过我的github项目https://github.com/warmheartli/ChatBotCourse中的read_images.c把图片打印出来是像下面这样的输出:
具体文件格式和打印方式请见我的另一篇基于简单的softmax模型的机器学习算法文章《机器学习教程 十四-利用tensorflow做手写数字识别》中的讲解
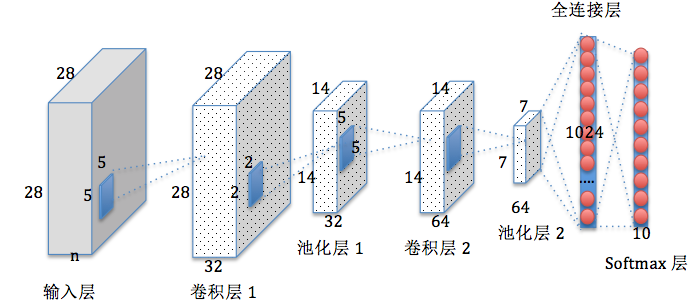
多层卷积网络设计 为了对mnist手写数据集做训练,我们设计这样的多层卷积网络:
第一层由一个卷积和一个max pooling完成,其中卷积运算的“视野”是5×5的像素范围,卷积使用1步长、0边距的模板(保证输入输出是同一个大小),1个输入通道(因为图片是灰度的,单色),32个输出通道(也就是设计32个特征)。由于我们通过上面read_images.c的打印可以看到每张图片都是28×28像素,那么第一次卷积输出也是28×28大小。max pooling采用2×2大小的模板,那么池化后输出的尺寸就是14×14,因为一共有32个通道,所以一张图片的输出一共是14×14×32=6272像素
第二层同样由一个卷积和一个max pooling完成,和第一层不同的是输入通道有32个(对应第一层的32个特征),输出通道我们设计64个(即输出64个特征),因为这一层的输入是每张大小14×14,所以这一个卷积层输出也是14×14,再经过这一层max pooling,输出大小就是7×7,那么一共输出像素就是7×7×64=3136
第三层是一个密集连接层,我们设计一个有1024个神经元的全连接层,这样就相当于第二层输出的7×7×64个值都作为这1024个神经元的输入
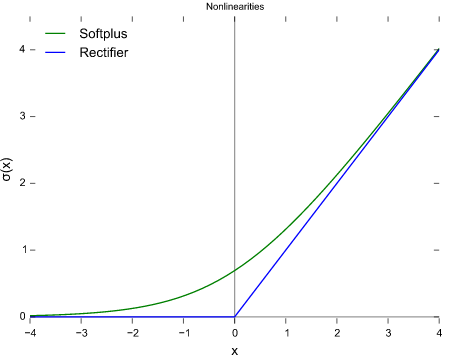
为了让算法更“智能”,我们把这些神经元的激活函数设计为ReLu函数,即如下图像中的蓝色(其中绿色是它的平滑版g(x)=log(1+e^x)):
最终的输出层,我们以第三层的1024个输出为输入,设计一个softmax层,输出10个概率值
tensorflow代码实现 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
import sys
reload(sys)
sys.setdefaultencoding("utf-8" )
from tensorflow.examples.tutorials.mnistimport input_data
import tensorflowas tf
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_string('data_dir' ,'./' ,'Directory for storing data' )
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True )
def weight_variable (shape) :
initial = tf.truncated_normal(shape, stddev=0.1 )
return tf.Variable(initial)
def bias_variable (shape) :
initial = tf.constant(0.1 , shape=shape)
return tf.Variable(initial)
def conv2d (x, W) :
return tf.nn.conv2d(x, W, strides=[1 ,1 ,1 ,1 ], padding='SAME' )
def max_pool_2x2 (x) :
return tf.nn.max_pool(x, ksize=[1 ,2 ,2 ,1 ],
strides=[1 ,2 ,2 ,1 ], padding='SAME' )
x = tf.placeholder(tf.float32, [None ,784 ])
y_ = tf.placeholder("float" , [None ,10 ])
W_conv1 = weight_variable([5 ,5 ,1 ,32 ])
b_conv1 = bias_variable([32 ])
x_image = tf.reshape(x, [-1 ,28 ,28 ,1 ])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5 ,5 ,32 ,64 ])
b_conv2 = bias_variable([64 ])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7 *7 *64 ,1024 ])
b_fc1 = bias_variable([1024 ])
h_pool2_flat = tf.reshape(h_pool2, [-1 ,7 *7 *64 ])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder("float" )
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024 ,10 ])
b_fc2 = bias_variable([10 ])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4 ).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1 ), tf.argmax(y_,1 ))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float" ))
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
for iin range(20000 ):
batch = mnist.train.next_batch(50 )
if i%100 ==0 :
train_accuracy = accuracy.eval(feed_dict={
x:batch[0 ], y_: batch[1 ], keep_prob:1.0 })
print "step %d, training accuracy %g" %(i, train_accuracy)
train_step.run(feed_dict={x: batch[0 ], y_: batch[1 ], keep_prob:0.5 })
print "test accuracy %g" %accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob:1.0 })
输出结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
[root@centos $] python digital_recognition_cnn.py
Extracting ./train-images-idx3-ubyte.gz
Extracting ./train-labels-idx1-ubyte.gz
Extracting ./t10k-images-idx3-ubyte.gz
Extracting ./t10k-labels-idx1-ubyte.gz
step 0, training accuracy 0.14
step 100, training accuracy 0.86
step 200, training accuracy 0.9
step 300, training accuracy 0.86
step 400, training accuracy 1
step 500, training accuracy 0.92
step 600, training accuracy 1
step 700, training accuracy 0.96
step 800, training accuracy 0.88
step 900, training accuracy 1
step 1000, training accuracy 0.96
step 1100, training accuracy 0.98
step 1200, training accuracy 0.94
step 1300, training accuracy 0.92
step 1400, training accuracy 0.98
……
最终准确率大概能达到99.2%
将深度学习应用到NLP 由于语言相比于语音、图像来说,是一种更高层的抽象,因此不是那么适合于深度学习,但是经过人类不断探索,也发现无论多么高层的抽象总是能通过更多底层基础的累积而碰触的到,本文介绍如何将深度学习应用到NLP所必须的底层基础
词向量 自然语言需要数学化才能够被计算机认识和计算。数学化的方法有很多,最简单的方法是为每个词分配一个编号,这种方法已经有多种应用,但是依然存在一个缺点:不能表示词与词的关系。
词向量是这样的一种向量[0.1, -3.31, 83.37, 93.0, -18.37, ……],每一个词对应一个向量,词义相近的词,他们的词向量距离也会越近(欧氏距离、夹角余弦)
词向量有一个优点,就是维度一般较低,一般是50维或100维,这样可以避免维度灾难,也更容易使用深度学习
词向量如何训练得出呢? 首先要了解一下语言模型,语言模型相关的内容请见我另外一篇文章《自己动手做聊天机器人 十三-把语言模型探究到底》。语言模型表达的实际就是已知前n-1个词的前提下,预测第n个词的概率。
词向量的训练是一种无监督学习,也就是没有标注数据,给我n篇文章,我就可以训练出词向量。
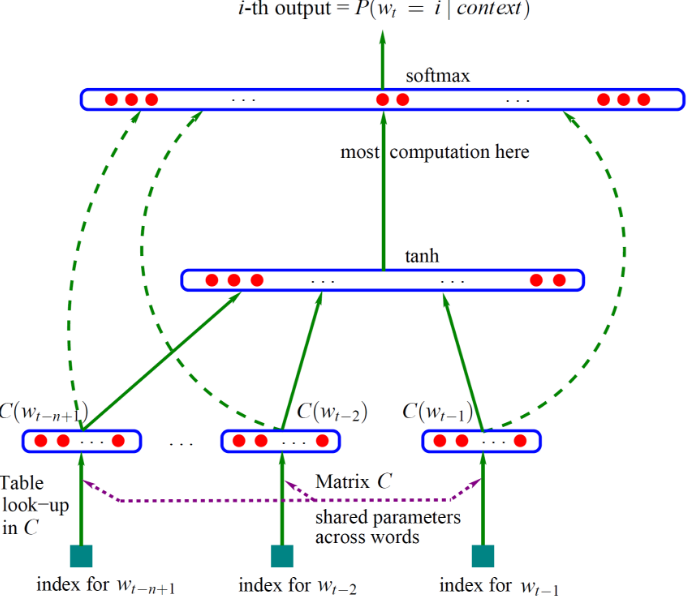
基于三层神经网络构建n-gram语言模型(词向量顺带着就算出来了)的基本思路:
最下面的w是词,其上面的C(w)是词向量,词向量一层也就是神经网络的输入层(第一层),这个输入层是一个(n-1)×m的矩阵,其中n-1是词向量数目,m是词向量维度
第二层(隐藏层)是就是普通的神经网络,以H为权重,以tanh为激活函数
第三层(输出层)有|V|个节点,|V|就是词表的大小,输出以U为权重,以softmax作为激活函数以实现归一化,最终就是输出可能是某个词的概率。
另外,神经网络中有一个技巧就是增加一个从输入层到输出层的直连边(线性变换),这样可以提升模型效果,这个变换矩阵设为W
假设C(w)就是输入的x,那么y的计算公式就是y = b + Wx + Utanh(d+Hx)
这个模型里面需要训练的有这么几个变量:C、H、U、W。利用梯度下降法训练之后得出的C就是生成词向量所用的矩阵,C(w)表示的就是我们需要的词向量
上面是讲解词向量如何“顺带”训练出来的,然而真正有用的地方在于这个词向量如何进一步应用。
词向量的应用 第一种应用是找同义词。具体应用案例就是google的word2vec工具,通过训练好的词向量,指定一个词,可以返回和它cos距离最相近的词并排序。
第二种应用是词性标注和语义角色标注任务。具体使用方法是:把词向量作为神经网络的输入层,通过前馈网络和卷积网络完成。
第三种应用是句法分析和情感分析任务。具体使用方法是:把词向量作为递归神经网络的输入。
第四种应用是命名实体识别和短语识别。具体使用方法是:把词向量作为扩展特征使用。
另外词向量有一个非常特别的现象:C(king)-C(queue)≈C(man)-C(woman),这里的减法就是向量逐维相减,换个表达方式就是:C(king)-C(man)+C(woman)和它最相近的向量就是C(queue),这里面的原理其实就是:语义空间中的线性关系。基于这个结论相信会有更多奇妙的功能出现。
google的文本挖掘深度学习工具word2vec的实现原理 词向量是将深度学习应用到NLP的根基,word2vec是如今使用最广泛最简单有效的词向量训练工具,那么它的实现原理是怎样的呢?本文将从原理出发来介绍word2vec
你是如何记住一款车的 问你这样一个问题:如果你大脑有很多记忆单元,让你记住一款白色奥迪Q7运动型轿车,你会用几个记忆单元?你也许会用一个记忆单元,因为这样最节省你的大脑。那么我们再让你记住一款小型灰色雷克萨斯,你会怎么办?显然你会用另外一个记忆单元来记住它。那么如果让你记住所有的车,你要耗费的记忆单元就不再是那么少了,这种表示方法叫做localist representation。这时你可能会换另外一种思路:我们用几个记忆单元来分别识别大小、颜色、品牌等基础信息,这样通过这几个记忆单元的输出,我们就可以表示出所有的车型了。这种表示方法叫做distributed representation,词向量就是一种用distributed representation表示的向量
localist representation与distributed representation localist representation中文释义是稀疏表达,典型的案例就是one hot vector,也就是这样的一种向量表示:
[1, 0, 0, 0, 0, 0……]表示成年男子
[0, 1, 0, 0, 0, 0……]表示成年女子
[0, 0, 1, 0, 0, 0……]表示老爷爷
[0, 0, 0, 1, 0, 0……]表示老奶奶
[0, 0, 0, 0, 1, 0……]表示男婴
[0, 0, 0, 0, 0, 1……]表示女婴
……
每一类型用向量中的一维来表示
而distributed representation中文释义是分布式表达,上面的表达方式可以改成:
性别 老年 成年 婴儿
[1, 0, 1, 0]表示成年男子
[0, 0, 1, 0]表示成年女子
[1, 1, 0, 0]表示老爷爷
[0, 1, 0, 0]表示老奶奶
[1, 0, 0, 1]表示男婴
[0, 0, 0, 1]表示女婴
如果我们想表达男童和女童,只需要增加一个特征维度即可
word embedding 翻译成中文叫做词嵌入,这里的embedding来源于范畴论,在范畴论中称为morphism(态射),态射表示两个数学结构中保持结构的一种过程抽象,比如“函数”、“映射”,他们都是表示一个域和另一个域之间的某种关系。
范畴论中的嵌入(态射)是要保持结构的,而word embedding表示的是一种“降维”的嵌入,通过降维避免维度灾难,降低计算复杂度,从而更易于在深度学习中应用。
理解了distributed representation和word embedding的概念,我们就初步了解了word2vec的本质,它其实是通过distributed representation的表达方式来表示词,而且通过降维的word embedding来减少计算量的一种方法
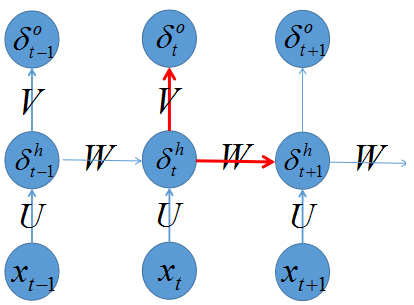
word2vec中的神经网络 word2vec中做训练主要使用的是神经概率语言模型,这需要掌握一些基础知识,否则下面的内容比较难理解,关于神经网络训练词向量的基础知识我在《自己动手做聊天机器人 二十四-将深度学习应用到NLP》中有讲解,可以参考,这里不再赘述。
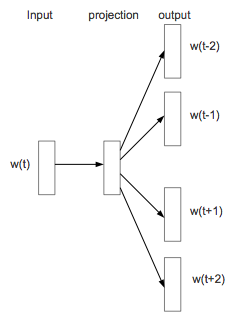
在word2vec中使用的最重要的两个模型是CBOW和Skip-gram模型,下面我们分别来介绍这两种模型
CBOW模型 CBOW全称是Continuous Bag-of-Words Model,是在已知当前词的上下文的前提下预测当前词
CBOW模型的神经网络结构设计如下:
输入层:词w的上下文一共2c个词的词向量
投影层:将输入层的2c个向量做求和累加
输出层:一个霍夫曼树,其中叶子节点是语料中出现过的词,权重是出现的次数
我们发现这一设计相比《自己动手做聊天机器人 二十四-将深度学习应用到NLP》中讲到的神经网络模型把首尾相接改成了求和累加,这样减少了维度;去掉了隐藏层,这样减少了计算量;输出层由softmax归一化运算改成了霍夫曼树;这一系列修改对训练的性能有很大提升,而效果不减,这是独到之处。
基于霍夫曼树的Hierarchical Softmax技术 上面的CBOW输出层为什么要建成一个霍夫曼树呢?因为我们是要基于训练语料得到每一个可能的w的概率。那么具体怎么得到呢?我们先来看一下这个霍夫曼树的例子:
在这个霍夫曼树中,我们以词足球为例,走过的路径图上容易看到,其中非根节点上的θ表示待训练的参数向量,也就是要达到这种效果:当在投射层产出了一个新的向量x,那么我通过逻辑回归公式:
σ(xTθ) = 1/(1+e^(-xTθ))
就可以得出在每一层被分到左节点(1)还是右节点(0)的概率分别是
p(d|x,θ) = 1-σ(xTθ)
和
p(d|x,θ) = σ(xTθ)
那么就有:
p(足球|Context(足球)) = ∏ p(d|x,θ)
现在模型已经有了,下面就是通过语料来训练v(Context(w))、x和θ的过程了
我们以对数似然函数为优化目标,盗取一个网上的推导公式:
假设两个求和符号里面的部分记作L(w, j),那么有
于是θ的更新公式:
同理得出x的梯度公式:
因为x是多个v的累加,word2vec中v的更新方法是:
想想机器学习真是伟大,整个模型从上到下全是未知数,竟然能算出来我真是服了
Skip-gram模型 Skip-gram全称是Continuous Skip-gram Model,是在已知当前词的情况下预测上下文
Skip-gram模型的神经网络结构设计如下:
输入层:w的词向量v(w)
投影层:依然是v(w),就是一个形式
输出层:和CBOW一样的霍夫曼树
后面的推导公式和CBOW大同小异,其中θ和v(w)的更新公式除了把符号名从x改成了v(w)之外完全一样,如下:
体验真实的word2vec 首先我们从网上下载一个源码,因为google官方的svn库已经不在了,所以只能从csdn下了,但是因为还要花积分才能下载,所以我干脆分享到了我的git上(https://github.com/warmheartli/ChatBotCourse/tree/master/word2vec ),大家可以直接下载
下载下来后直接执行make编译(如果是mac系统要把代码里所有的#include替换成#include)
编译后生成word2vec、word2phrase、word-analogy、distance、compute-accuracy几个二进制文件
我们先用word2vec来训练
首先我们要有训练语料,其实就是已经切好词(空格分隔)的文本,比如我们已经有了这个文本文件叫做train.txt,内容是”人工 智能 一直 以来 是 人类 的 梦想 造 一台 可以 为 你 做 一切 事情 并且 有 情感 的 机器 人”并且重复100遍
执行
1
./word2vec -train train.txt -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -thread 12 -binary 1
会生成一个vectors.bin文件,这个就是训练好的词向量的二进制文件,利用这个文件我们可以求近义词了,执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
./distance vectors.bin
Enter word or sentence (EXIT to break): 人类
Word: 人类 Position in vocabulary: 6
Word Cosine distance
------------------------------------------------------------------------
可以 0.094685
为 0.091899
人工 0.088387
机器 0.076216
智能 0.073093
情感 0.071088
做 0.059367
一直 0.056979
以来 0.049426
一切 0.042201
</s> 0.025968
事情 0.014169
的 0.003633
是 -0.012021
有 -0.014790
一台 -0.021398
造 -0.031242
人 -0.043759
你 -0.072834
梦想 -0.086062
并且 -0.122795
……
如果你有很丰富的语料,那么结果会很漂亮
图解递归神经网络(RNN) 聊天机器人是需要智能的,而如果他记不住任何信息,就谈不上智能,递归神经网络是一种可以存储记忆的神经网络,LSTM是递归神经网络的一种,在NLP领域应用效果不错,本节我们来介绍RNN和LSTM
递归神经网络 递归神经网络(RNN)是两种人工神经网络的总称。一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neural network)。时间递归神经网络的神经元间连接构成有向图,而结构递归神经网络利用相似的神经网络结构递归构造更为复杂的深度网络。两者训练的算法不同,但属于同一算法变体(百度百科)。本节我们重点介绍时间递归神经网络,下面提到RNN特指时间递归神经网络。
时间递归神经网络 传统的神经网络叫做FNN(Feed-Forward Neural Networks),也就是前向反馈神经网络,有关传统神经网络的介绍请见《机器学习教程 十二-神经网络模型的原理》,RNN是在此基础上引入了定向循环,也就是已神经元为节点组成的图中存在有向的环,这种神经网络可以表达某些前后关联关系,事实上,真正的生物神经元之间也是存在这种环形信息传播的,RNN也是神经网络向真实生物神经网络靠近的一个进步。一个典型的RNN是这样的:
图中隐藏层中的节点之间构成了全连接,也就是一个隐藏层节点的输出可以作为另一个隐藏层节点甚至它自己的输入
这种结构可以抽象成:
其中U、V、W都是变换概率矩阵,x是输入,o是输出
比较容易看出RNN的关键是隐藏层,因为隐藏层能够捕捉到序列的信息,也就是一种记忆的能力
在RNN中U、V、W的参数都是共享的,也就是只需要关注每一步都在做相同的事情,只是输入不同,这样来降低参数个数和计算量
RNN在NLP中的应用比较多,因为语言模型就是在已知已经出现的词的情况下预测下一个词的概率的,这正是一个有时序的模型,下一个词的出现取决于前几个词,刚好对应着RNN中隐藏层之间的内部连接
RNN的训练方法 RNN的训练方法和传统神经网络一样,都是使用BP误差反向传播算法来更新和训练参数。
因为从输入到最终的输出中间经过了几步是不确定的,因此为了计算方便,我们利用时序的方式来做前向计算,我们假设x表示输入值,s表示输入x经过U矩阵变换后的值,h表示隐藏层的激活值,o表示输出层的值, f表示隐藏层的激活函数,g表示输出层的激活函数:
当t=0时,输入为x0, 隐藏层为h0
当t=1时,输入为x1, s1 = Ux1+Wh0, h1 = f(s1), o1 = g(Vh1)
当t=2时,s2 = Ux2+Wh1, h2 = f(s2), o2 = g(Vh2)
以此类推,st = Uxt + Wh(t-1), ht = f(st), ot = g(Vht)
这里面h=f(现有的输入+过去记忆总结)是对RNN的记忆能力的全然体现
通过这样的前向推导,我们是不是可以对RNN的结构做一个展开,成如下的样子:
这样从时序上来看更直观明了
下面就是反向修正参数的过程了,每一步输出o和实际的o值总会有误差,和传统神经网络反向更新的方法一样,用误差来反向推导,利用链式求导求出每层的梯度,从而更新参数,反向推导过程中我们还是把神经网络结构看成展开后的样子:
根据链式求导法则,得出隐藏层的残差计算公式为:
因此W和U的梯度就是:
LSTM(Long Short Tem Momery networks)
特别讲解一下LSTM是因为LSTM是一种特别的RNN,它是RNN能得到成功应用的关键,当下非常流行。RNN存在一个长序列依赖(Long-Term Dependencies)的问题:下一个词的出现概率和非常久远的之前的词有关,但考虑到计算量的问题,我们会对依赖的长度做限制,LSTM很好的解决了这个问题,因为它专门为此而设计。
借用http://colah.github.io/posts/2015-08-Understanding-LSTMs/ 中经典的几张图来说明下,第一张图是传统RNN的另一种形式的示意图,它只包含一个隐藏层,以tanh为激发函数,这里面的“记忆”体现在t的滑动窗口上,也就是有多少个t就有多少记忆,如下图
那么我们看LSTM的设计,如下,这里面有一些符号,其中黄色方框是神经网络层(意味着有权重系数和激活函数,σ表示sigmoid激活函数,tanh表示tanh激活函数),粉红圆圈表示矩阵运算(矩阵乘或矩阵加)
这里需要分部分来说,下面这部分是一个历史信息的传递和记忆,其中粉红×是就像一个能调大小的阀门(乘以一个0到1之间的系数),下面的第一个sigmoid层计算输出0到1之间的系数,作用到粉红×门上,这个操作表达上一阶段传递过来的记忆保留多少,忘掉多少
其中的sigmoid公式如下:
可以看出忘掉记忆多少取决于上一隐藏层的输出h{t-1}和本层的输入x{t}
下面这部分是由上一层的输出h{t-1}和本层的输入x{t}得出的新信息,存到记忆中:
其中包括计算输出值Ct部分的tanh神经元和计算比例系数的sigmoid神经元(这里面既存在sigmoid又存在tanh原因在于sigmoid取值范围是[0,1]天然作为比例系数,而tanh取值范围是[-1,1]可以作为一个输出值)。其中i{t}和Ct计算公式如下:
那么Ct输出就是:
下面部分是隐藏层输出h的计算部分,它考虑了当前拥有的全部信息(上一时序隐藏层的输出、本层的输入x和当前整体的记忆信息),其中本单元状态部分C通过tanh激活并做一个过滤(上一时序输出值和当前输入值通过sigmoid激活后的系数)
计算公式如下:
LSTM非常适合在NLP领域应用,比如一句话出现的词可以认为是不同时序的输入x,而在某一时间t出现词A的概率可以通过LSTM计算,因为词A出现的概率是取决于前面出现过的词的,但取决于前面多少个词是不确定的,这正是LSTM所做的存储着记忆信息C,使得能够得出较接近的概率。
总结 RNN就是这样一种神经网络,它让隐藏层自身之间存在有向环,从而更接近生物神经网络,也具有了存储记忆的能力,而LSTM作为RNN中更有实用价值的一种,通过它特殊的结构设计实现了永久记忆留存,更适合于NLP,这也为将深度学习应用到自然语言处理开了先河,有记忆是给聊天机器人赋予智能的前提,这也为我们的聊天机器人奠定了实践基础。
用深度学习来做自动问答的一般方法 聊天机器人本质上是一个范问答系统,既然是问答系统就离不开候选答案的选择,利用深度学习的方法可以帮助我们找到最佳的答案,本节我们来讲述一下用深度学习来做自动问答的一般方法
语料库的获取方法 对于一个范问答系统,一般我们从互联网上收集语料信息,比如百度、谷歌等,用这些结果构建问答对组成的语料库。然后把这些语料库分成多个部分:训练集、开发集、测试集
问答系统训练其实是训练一个怎么在一堆答案里找到一个正确答案的模型,那么为了让样本更有效,在训练过程中我们不把所有答案都放到一个向量空间中,而是对他们做个分组,首先,我们在语料库里采集样本,收集每一个问题对应的500个答案集合,其中这500个里面有正向的样本,也会随机选一些负向样本放里面,这样就能突出这个正向样本的作用了
基于CNN的系统设计 CNN的三个优点:sparse interaction(稀疏的交互),parameter sharing(参数共享),equivalent respresentation(等价表示)。正是由于这三方面的优点,才更适合于自动问答系统中的答案选择模型的训练。
我们设计卷积公式表示如下(不了解卷积的含义请见《机器学习教程 十五-细解卷积神经网络》):
假设每个词用三维向量表示,左边是4个词,右边是卷积矩阵,那么得到输出为:
如果基于这个结果做1-MaxPool池化,那么就取o中的最大值
通用的训练方法 训练时获取问题的词向量Vq(这里面词向量可以使用google的word2vec来训练,有关word2vec的内容可以看《自己动手做聊天机器人 二十五-google的文本挖掘深度学习工具word2vec的实现原理》),和一个正向答案的词向量Va+,和一个负向答案的词向量Va-, 然后比较问题和这两个答案的相似度,两个相似度的差值如果大于一个阈值m就用来更新模型参数,然后继续在候选池里选答案,小于m就不更新模型,即优化函数为:
参数更新方式和其他卷积神经网络方式相同,都是梯度下降、链式求导
对于测试数据,计算问题和候选答案的cos距离,相似度最大的那个就是正确答案的预测
神经网络结构设计 以下是六种结构设计,解释一下,其中HL表示hide layer隐藏层,它的激活函数设计成z = tanh(Wx+B),CNN是卷积层,P是池化层,池化步长为1,T是tanh层,P+T的输出是向量表示,最终的输出是两个向量的cos相似度
图中HL或CNN连起来的表示他们共享相同的权重。CNN的输出是几维的取决于做多少个卷积特征,如果有4个卷积,那么结果就是4*3的矩阵(这里面的3在下一步被池化后就变成1维了)
以上结构的效果在论文《Applying Deep Learning To Answer Selection- A Study And An Open Task》中有详细说明,这里不赘述
总结 要把深度学习运用到聊天机器人中,关键在于以下几点:
对几种神经网络结构的选择、组合、优化
因为是有关自然语言处理,所以少不了能让机器识别的词向量
当涉及到相似或匹配关系时要考虑相似度计算,典型的方法是cos距离
如果需求涉及到文本序列的全局信息就用CNN或LSTM
当精度不高时可以加层
当计算量过大时别忘了参数共享和池化
脑洞大开:基于美剧字幕的聊天语料库建设方案 要让聊天机器人进行学习,需要海量的聊天语料库,但是网上的语料库基本上都是有各种标注的文章,并没有可用的对话语料,虽然有一些社区的帖子数据,但是既要花大把银子还不知道质量如何。笔者突然灵机一动,找到一个妙招能获取海量高质聊天语料,这下聊天机器人再也不愁语料数据了。
美剧字幕 是的,你没有看错,我就是这样获取海量高质聊天语料的。外文电影或电视剧的字幕文件是一个天然的聊天语料,尤其是对话比较多的美剧最佳。为了能下载大量美剧字幕,我打算抓取字幕库网站www.zimuku.net,当然你也可以选择其他网站抓取。
自动抓取字幕 有关爬虫相关内容请见我的另一篇文章《教你成为全栈工程师(Full Stack Developer) 三十-十分钟掌握最强大的python爬虫》。在这里我直接贴上我的抓取器重要代码(代码共享在了https://github.com/warmheartli/ChatBotCourse):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import scrapy
from w3lib.html import remove_tags
from subtitle_crawler.items import SubtitleCrawlerItem
class SubTitleSpider(scrapy.Spider):
name = "subtitle"
allowed_domains = ["zimuku.net"]
start_urls = [
"http://www.zimuku.net/search?q=&t=onlyst&ad=1&p=20",
"http://www.zimuku.net/search?q=&t=onlyst&ad=1&p=21",
"http://www.zimuku.net/search?q=&t=onlyst&ad=1&p=22",
]
def parse(self, response):
hrefs = response.selector.xpath('//div[contains(@class, "persub")]/h1/a/@href').extract()
for href in hrefs:
url = response.urljoin(href)
request = scrapy.Request(url, callback=self.parse_detail)
yield request
def parse_detail(self, response):
url = response.selector.xpath('//li[contains(@class, "dlsub")]/div/a/@href').extract()[0]
print "processing: ", url
request = scrapy.Request(url, callback=self.parse_file)
yield request
def parse_file(self, response):
body = response.body
item = SubtitleCrawlerItem()
item['url'] = response.url
item['body'] = body
return item
下面是pipeline.py代码:
1
2
3
4
5
6
7
8
class SubtitleCrawlerPipeline(object):
def process_item(self, item, spider):
url = item['url']
file_name = url.replace('/','_').replace(':','_')
fp = open('result/'+file_name, 'w')
fp.write(item['body'])
fp.close()
return item
看下我抓取的最终效果
1
2
3
4
5
6
[root@centos:~/Developer/ChatBotCourse/subtitle $] ls result/|head -1
http___shooter.zimuku.net_download_265300_Hick.2011.720p.BluRay.x264.YIFY.rar
[root@centos:~/Developer/ChatBotCourse/subtitle $] ls result/|wc -l
82575
[root@centos:~/Developer/ChatBotCourse/subtitle $] du -hs result/
16G result/
字幕文件的解压方法 linux下怎么解压zip文件
直接执行unzip file.zip即可
linux下怎么解压rar文件
http://www.rarlab.com/download.htm
wgethttp://www.rarlab.com/rar/rarlinux-x64-5.4.0.tar.gz
tar zxvf rarlinux-x64-5.4.0.tar.gz
./rar/unrar试试
解压命令:
unrar x file.rar
linux下怎么解压7z文件
http://downloads.sourceforge.net/project/p7zip下载源文件,解压后执行make编译后bin/7za可用,用法
bin/7za x file.7z
最终字幕的处理方式 有关解压出来的文本字幕文件的处理,我后面的文章会详细讲解如何分词、如何组合,敬请期待。
重磅:近1GB的三千万聊天语料供出 经过半个月的倾力打造,建设好的聊天语料库包含三千多万条简体中文高质量聊天语料,近1G的纯文本数据。此语料库全部基于2万部影视剧字幕,经由爬取、分类、解压、语言识别、编码识别、编码转换、过滤清洗等一系列繁琐过程。把整个建设过程分享出来供大家玩耍。
注意:本文提到的程序和脚本都分享在https://github.com/warmheartli/ChatBotCourse 。如需直接获取最终语料库,请见文章末尾。
第一步:爬取影视剧字幕 请见我的这篇文章《二十八-脑洞大开:基于美剧字幕的聊天语料库建设方案》
第二步:压缩格式分类 下载的字幕有zip格式和rar格式,因为数量比较多,需要做筛选分类,以便后面的处理,这步看似简单实则不易,因为要解决:文件多无法ls的问题、文件名带特殊字符的问题、文件名重名误覆盖问题、扩展名千奇百怪的问题,我写成了python脚本mv_zip.py如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import glob
import os
import fnmatch
import shutil
import sys
def iterfindfiles(path, fnexp):
for root, dirs, files in os.walk(path):
for filename in fnmatch.filter(files, fnexp):
yield os.path.join(root, filename)
i=0
for filename in iterfindfiles(r"./input/", "*.zip"):
i=i+1
newfilename = "zip/" + str(i) + "_" + os.path.basename(filename)
print filename + " <===> " + newfilename
shutil.move(filename, newfilename)
其中的扩展名根据压缩文件可能有的扩展名修改成*.rar、*.RAR、*.zip、*.ZIP等
第三步:解压 解压这一步需要根据所用的操作系统下载不同的解压工具,建议使用unrar和unzip,为了解决解压后文件名可能重名覆盖的问题,我总结出如下两句脚本来实现批量解压:
1
2
i=0; for file in `ls`; do mkdir output/${i}; echo "unzip $file -d output/${i}";unzip -P abc $file -d output/${i} > /dev/null; ((i++)); done
i=0; for file in `ls`; do mkdir output/${i}; echo "${i} unrar x $file output/${i}";unrar x $file output/${i} > /dev/null; ((i++)); done
第四步:srt、ass、ssa字幕文件分类整理 当你下载大量字幕并解压后你会发现字幕文件类型有很多种,包括srt、lrc、ass、ssa、sup、idx、str、vtt,但是整体量级上来看srt、ass、ssa占绝对优势,因此简单起见,我们抛弃掉其他格式,只保留这三种,具体分类整理的脚本可以参考第二部压缩格式分类的方法按扩展名整理
第五步:清理目录 在我边整理边分析的过程中发现,我为了避免重名把文件放到不同目录里后,如果再经过一步文件类型整理,会产生非常多的空目录,每次ls都要拉好几屏,所以写了一个自动清理空目录的脚本clear_empty_dir.py,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
import glob
import os
import fnmatch
import shutil
import sys
def iterfindfiles(path, fnexp):
for root, dirs, files in os.walk(path):
if 0 == len(files) and len(dirs) == 0:
print root
os.rmdir(root)
iterfindfiles(r"./input/", "")
第六步:清理非字幕文件 在整个字幕文件分析过程中,总有很多其他文件干扰你的视线,比如txt、html、doc、docx,因为不是我们想要的,因此干脆直接干掉,批量删除脚本del_file.py如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import glob
import os
import fnmatch
import shutil
import sys
def iterfindfiles(path, fnexp):
for root, dirs, files in os.walk(path):
for filename in fnmatch.filter(files, fnexp):
yield os.path.join(root, filename)
for suffix in ("*.mp4", "*.txt", "*.JPG", "*.htm", "*.doc", "*.docx", "*.nfo", "*.sub", "*.idx"):
for filename in iterfindfiles(r"./input/", suffix):
print filename
os.remove(filename)
第七步:多层解压缩 把抓取到的字幕压缩包解压后有的文件里面依然还有压缩包,继续解压才能看到字幕文件,因此上面这些步骤再来一次,不过要做好心理准备,没准需要再来n次!
第八步:舍弃剩余的少量文件 经过以上几步的处理后剩下一批无扩展名的、特殊扩展名如:“srt.简体”,7z等、少量压缩文件,总体不超过50M,想想伟大思想家马克思教导我们要抓主要矛盾,因此这部分我们直接抛弃掉
第九步:编码识别与转码 字幕文件就是这样的没有规范,乃至于各种编码齐聚,什么utf-8、utf-16、gbk、unicode、iso8859琳琅满目应有尽有,我们要统一到一种编码方便使用,索性我们统一到utf-8,get_charset_and_conv.py如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import chardet
import sys
import os
if __name__ == '__main__':
if len(sys.argv) == 2:
for root, dirs, files in os.walk(sys.argv[1]):
for file in files:
file_path = root + "/" + file
f = open(file_path,'r')
data = f.read()
f.close()
encoding = chardet.detect(data)["encoding"]
if encoding not in ("UTF-8-SIG", "UTF-16LE", "utf-8", "ascii"):
try:
gb_content = data.decode("gb18030")
gb_content.encode('utf-8')
f = open(file_path, 'w')
f.write(gb_content.encode('utf-8'))
f.close()
except:
print "except:", file_path
第十步:筛选中文 考虑到我朝广大人民的爱国热情,我只做中文,所以什么英文、韩文、日文、俄文、火星文、鸟语……全都不要,参考extract_sentence_srt.py如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# coding:utf-8
import chardet
import os
import re
cn=ur"([\u4e00-\u9fa5]+)"
pattern_cn = re.compile(cn)
jp1=ur"([\u3040-\u309F]+)"
pattern_jp1 = re.compile(jp1)
jp2=ur"([\u30A0-\u30FF]+)"
pattern_jp2 = re.compile(jp2)
for root, dirs, files in os.walk("./srt"):
file_count = len(files)
if file_count > 0:
for index, file in enumerate(files):
f = open(root + "/" + file, "r")
content = f.read()
f.close()
encoding = chardet.detect(content)["encoding"]
try:
for sentence in content.decode(encoding).split('\n'):
if len(sentence) > 0:
match_cn = pattern_cn.findall(sentence)
match_jp1 = pattern_jp1.findall(sentence)
match_jp2 = pattern_jp2.findall(sentence)
sentence = sentence.strip()
if len(match_cn)>0 and len(match_jp1)==0 and len(match_jp2) == 0 and len(sentence)>1 and len(sentence.split(' ')) < 10:
print sentence.encode('utf-8')
except:
continue
第十一步:字幕中的句子提取 不同格式的字幕有特定的格式,除了句子之外还有很多字幕的控制语句,我们一律过滤掉,只提取我们想要的重点内容,因为不同的格式都不一样,在这里不一一举例了,感兴趣可以去我的github查看,在这里单独列出ssa格式字幕的部分代码供参考:
1
2
3
4
5
6
if line.find('Dialogue') == 0 and len(line) < 500:
fields = line.split(',')
sentence = fields[len(fields)-1]
tag_fields = sentence.split('}')
if len(tag_fields) > 1:
sentence = tag_fields[len(tag_fields)-1]
第十二步:内容过滤 经过上面几步的处理,其实已经形成了完整的语料库了,只是里面还有一些不像聊天的内容我们需要进一步做优化,包括:过滤特殊的unicode字符、过滤特殊的关键词(如:字幕、时间轴、校对……)、去除字幕样式标签、去除html标签、去除连续特殊字符、去除转义字符、去除剧集信息等,具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
# coding:utf-8
import sys
import re
import chardet
if __name__ == '__main__':
#illegal=ur"([\u2000-\u2010]+)"
illegal=ur"([\u0000-\u2010]+)"
pattern_illegals = [re.compile(ur"([\u2000-\u2010]+)"), re.compile(ur"([\u0090-\u0099]+)")]
filters = ["字幕", "时间轴:", "校对:", "翻译:", "后期:", "监制:"]
filters.append("时间轴:")
filters.append("校对:")
filters.append("翻译:")
filters.append("后期:")
filters.append("监制:")
filters.append("禁止用作任何商业盈利行为")
filters.append("http")
htmltagregex = re.compile(r'<[^>]+>',re.S)
brace_regex = re.compile(r'\{.*\}',re.S)
slash_regex = re.compile(r'\\\w',re.S)
repeat_regex = re.compile(r'[-=]{10}',re.S)
f = open("./corpus/all.out", "r")
count=0
while True:
line = f.readline()
if line:
line = line.strip()
# 编码识别,不是utf-8就过滤
gb_content = ''
try:
gb_content = line.decode("utf-8")
except Exception as e:
sys.stderr.write("decode error: ", line)
continue
# 中文识别,不是中文就过滤
need_continue = False
for pattern_illegal in pattern_illegals:
match_illegal = pattern_illegal.findall(gb_content)
if len(match_illegal) > 0:
sys.stderr.write("match_illegal error: %s\n" % line)
need_continue = True
break
if need_continue:
continue
# 关键词过滤
need_continue = False
for filter in filters:
try:
line.index(filter)
sys.stderr.write("filter keyword of %s %s\n" % (filter, line))
need_continue = True
break
except:
pass
if need_continue:
continue
# 去掉剧集信息
if re.match('.*第.*季.*', line):
sys.stderr.write("filter copora %s\n" % line)
continue
if re.match('.*第.*集.*', line):
sys.stderr.write("filter copora %s\n" % line)
continue
if re.match('.*第.*帧.*', line):
sys.stderr.write("filter copora %s\n" % line)
continue
# 去html标签
line = htmltagregex.sub('',line)
# 去花括号修饰
line = brace_regex.sub('', line)
# 去转义
line = slash_regex.sub('', line)
# 去重复
new_line = repeat_regex.sub('', line)
if len(new_line) != len(line):
continue
# 去特殊字符
line = line.replace('-', '').strip()
if len(line) > 0:
sys.stdout.write("%s\n" % line)
count+=1
else:
break
f.close()
pass
数据样例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这是什么
是寄给医院的
井崎…为什么?
是为了小雪的事情
怎么回事?
您不记得了吗
在她说小雪…
就是在这种非常时期和我们一起舍弃休息时间来工作的护士失踪时…
医生 小雪她失踪了
你不是回了一句「是吗」吗
是吗…
不 对不起
跟我道歉也没用啊
而且我们都知道您是因为夫人的事情而操劳
但是 我想小聪是受不了医生一副漠不关心的样子
事到如今再责备医生也没有用了
是我的错吗…
我就是这个意思 您听不出来吗
我也难以接受
……
第一版聊天机器人诞生——吃了字幕长大的小二兔 在上一节中我分享了建设好的影视剧字幕聊天语料库,本节基于这个语料库开发我们的聊天机器人,因为是第一版,所以机器人的思绪还有点小乱,答非所问、驴唇不对马嘴得比较搞笑,大家凑合玩
第一版思路 首先要考虑到我的影视剧字幕聊天语料库特点,它是把影视剧里面的说话内容一句一句以回车换行罗列的三千多万条中国话,那么相邻的第二句其实就很可能是第一句的最好的回答,另外,如果对于一个问句有很多种回答,那么我们可以根据相关程度以及历史聊天记录来把所有回答排个序,找到最优的那个,这么说来这是一个搜索和排序的过程。对!没错!我们可以借助搜索技术来做第一版。
lucene+ik lucene是一款开源免费的搜索引擎库,java语言开发。ik全称是IKAnalyzer,是一个开源中文切词工具。我们可以利用这两个工具来对语料库做切词建索引,并通过文本搜索的方式做文本相关性检索,然后把下一句取出来作为答案候选集,然后再通过各种方式做答案排序,当然这个排序是很有学问的,聊天机器人有没有智能一半程度上体现在了这里(还有一半体现在对问题的分析上),本节我们的主要目的是打通这一套机制,至于“智能”这件事我们以后逐个拆解开来不断研究
建索引 首先用eclipse创建一个maven工程,如下:
maven帮我们自动生成了pom.xml文件,这配置了包依赖信息,我们在dependencies标签中添加如下依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.10.4</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.10.4</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.4</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>5.0.0.Alpha2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.1.41</version>
</dependency>
并在project标签中增加如下配置,使得依赖的jar包都能自动拷贝到lib目录下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>theMainClass</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
从https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/ik-analyzer/IK%20Analyzer%202012FF_hf1_source.rar下载ik的源代码并把其中的src/org目录拷贝到chatbotv1工程的src/main/java下,然后刷新maven工程,效果如下:
在com.shareditor.chatbotv1包下maven帮我们自动生成了App.java,为了辨识我们改成Indexer.java,关键代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
Analyzer analyzer = new IKAnalyzer(true);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_4_9, analyzer);
iwc.setOpenMode(OpenMode.CREATE);
iwc.setUseCompoundFile(true);
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(new File(indexPath)), iwc);
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(corpusPath), "UTF-8"));
String line = "";
String last = "";
long lineNum = 0;
while ((line = br.readLine()) != null) {
line = line.trim();
if (0 == line.length()) {
continue;
}
if (!last.equals("")) {
Document doc = new Document();
doc.add(new TextField("question", last, Store.YES));
doc.add(new StoredField("answer", line));
indexWriter.addDocument(doc);
}
last = line;
lineNum++;
if (lineNum % 100000 == 0) {
System.out.println("add doc " + lineNum);
}
}
br.close();
indexWriter.forceMerge(1);
indexWriter.close();
编译好后拷贝src/main/resources下的所有文件到target目录下,并在target目录下执行
1
java -cp $CLASSPATH:./lib/:./chatbotv1-0.0.1-SNAPSHOT.jar com.shareditor.chatbotv1.Indexer ../../subtitle/raw_subtitles/subtitle.corpus ./index
最终生成的索引目录index通过lukeall-4.9.0.jar查看如下:
检索服务 基于netty创建一个http服务server,代码共享在https://github.com/warmheartli/ChatBotCourse的chatbotv1目录下,关键代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
Analyzer analyzer = new IKAnalyzer(true);
QueryParser qp = new QueryParser(Version.LUCENE_4_9, "question", analyzer);
if (topDocs.totalHits == 0) {
qp.setDefaultOperator(Operator.AND);
query = qp.parse(q);
System.out.println(query.toString());
indexSearcher.search(query, collector);
topDocs = collector.topDocs();
}
if (topDocs.totalHits == 0) {
qp.setDefaultOperator(Operator.OR);
query = qp.parse(q);
System.out.println(query.toString());
indexSearcher.search(query, collector);
topDocs = collector.topDocs();
}
ret.put("total", topDocs.totalHits);
ret.put("q", q);
JSONArray result = new JSONArray();
for (ScoreDoc d : topDocs.scoreDocs) {
Document doc = indexSearcher.doc(d.doc);
String question = doc.get("question");
String answer = doc.get("answer");
JSONObject item = new JSONObject();
item.put("question", question);
item.put("answer", answer);
item.put("score", d.score);
item.put("doc", d.doc);
result.add(item);
}
ret.put("result", result);
其实就是查询建好的索引,通过query词做切词拼lucene query,然后检索索引的question字段,匹配上的返回answer字段的值作为候选集,使用时挑出候选集里的一条作为答案
这个server可以通过http访问,如http://127.0.0.1:8765/?q=hello(注意:如果是中文需要转成urlcode发送,因为java端读取时按照urlcode解析),server的启动方法是:
1
java -cp $CLASSPATH:./lib/:./chatbotv1-0.0.1-SNAPSHOT.jar com.shareditor.chatbotv1.Searcher
聊天界面 先看下我们的界面是什么样的,然后再说怎么做的
首先需要有一个可以展示聊天内容的框框,我们选择ckeditor,因为它支持html格式内容的展示,然后就是一个输入框和发送按钮,html代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
<div class="col-sm-4 col-xs-10">
<div class="row">
<textarea id="chatarea">
<div style='color: blue; text-align: left; padding: 5px;'>机器人: 喂,大哥您好,您终于肯跟我聊天了,来侃侃呗,我来者不拒!</div>
<div style='color: blue; text-align: left; padding: 5px;'>机器人: 啥?你问我怎么这么聪明会聊天?因为我刚刚吃了一堆影视剧字幕!</div>
</textarea>
</div>
<br />
<div class="row">
<div class="input-group">
<input type="text" id="input" class="form-control" autofocus="autofocus" onkeydown="submitByEnter()" />
<span class="input-group-btn">
<button class="btn btn-default" type="button" onclick="submit()">发送</button>
</span>
</div>
</div>
</div>
<script type="text/javascript">
CKEDITOR.replace('chatarea',
{
readOnly: true,
toolbar: ['Source'],
height: 500,
removePlugins: 'elementspath',
resize_enabled: false,
allowedContent: true
});
</script>
为了调用上面的聊天server,需要实现一个发送请求获取结果的控制器,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public function queryAction(Request $request)
{
$q = $request->get('input');
$opts = array(
'http'=>array(
'method'=>"GET",
'timeout'=>60,
)
);
$context = stream_context_create($opts);
$clientIp = $request->getClientIp();
$response = file_get_contents('http://127.0.0.1:8765/?q=' . urlencode($q) . '&clientIp=' . $clientIp, false, $context);
$res = json_decode($response, true);
$total = $res['total'];
$result = '';
if ($total > 0) {
$result = $res['result'][0]['answer'];
}
return new Response($result);
}
这个控制器的路由配置为:
1
2
3
chatbot_query:
path: /chatbot/query
defaults: { _controller: AppBundle:ChatBot:query }
因为聊天server响应时间比较长,为了不导致web界面卡住,我们在执行submit的时候异步发请求和收结果,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
var xmlHttp;
function submit() {
if (window.ActiveXObject) {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
else if (window.XMLHttpRequest) {
xmlHttp = new XMLHttpRequest();
}
var input = $("#input").val().trim();
if (input == '') {
jQuery('#input').val('');
return;
}
addText(input, false);
jQuery('#input').val('');
var datastr = "input=" + input;
datastr = encodeURI(datastr);
var url = "/chatbot/query";
xmlHttp.open("POST", url, true);
xmlHttp.onreadystatechange = callback;
xmlHttp.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
xmlHttp.send(datastr);
}
function callback() {
if (xmlHttp.readyState == 4 && xmlHttp.status == 200) {
var responseText = xmlHttp.responseText;
addText(responseText, true);
}
}
这里的addText是往ckeditor里添加一段文本,方法如下:
1
2
3
4
5
6
7
8
9
10
function addText(text, is_response) {
var oldText = CKEDITOR.instances.chatarea.getData();
var prefix = '';
if (is_response) {
prefix = "<div style='color: blue; text-align: left; padding: 5px;'>机器人: "
} else {
prefix = "<div style='color: darkgreen; text-align: right; padding: 5px;'>我: "
}
CKEDITOR.instances.chatarea.setData(oldText + "" + prefix + text + "</div>");
}
以上所有代码全都共享在https://github.com/warmheartli/ChatBotCourse 和https://github.com/warmheartli/shareditor.com 中供参考