1、对语料进行分析
基本目录如下:
![]()
其中train存放的是训练集,answer存放的是测试集,具体看下train中的文件:
![]()
下面有20个文件夹,对应着20个类,我们继续看下其中的文件,以C3-Art为例:
![]()
每一篇都对应着一个txt文件,编码格式是gb18030.utf8文件夹下的是utf-8编码格式的txt文件。
其中C3-Art0001.txt的部分内容如下:
![]()
2、数据预处理
(1)将文本路径存储到相应的txt文件中
我们要使用数据,必须得获得文本以及其对应的标签,为了方便我们进行处理,首先将训练集中的txt的路径和测试集中的txt的路径分别存到相应的txt文件中,具体代码如下:
def txt_path_to_txt():
#将训练数据的txt和测试数据的txt保存在txt中
train_path = "/content/drive/My Drive/NLP/dataset/Fudan/train/" #训练数据存放位置
test_path = "/content/drive/My Drive/NLP/dataset/Fudan/answer/" #测试数据存放位置
train_txt_path = "/content/drive/My Drive/NLP/dataset/Fudan/train.txt"
test_txt_path = "/content/drive/My Drive/NLP/dataset/Fudan/test.txt"
train_list = os.listdir(train_path)
fp1 = open(train_txt_path,"a",encoding="utf-8")
fp2 = open(test_txt_path,"a",encoding="utf-8")
for train_dir in train_list:
for txt in glob.glob(train_path+train_dir+"/*.txt"):
fp1.write(txt+"\n")
fp1.close()
test_list = os.listdir(test_path)
for test_dir in test_list:
for txt in glob.glob(test_path+test_dir+"/*.txt"):
fp2.write(txt+"\n")
fp2.close()os.listdir():用于获取目录下的所有文件夹,返回一个列表。
glob.glob():用于获取当前目录下指定的文件,返回的是一个字符串。
之后我们得到一个train.txt和test.txt。train.txt部分内容如下:
![]()
(2) 读取train.txt或test.txt中的文件路径,将里面的内容和标签存储到txt文件中
代码如下:
![复制代码]()
def train_content_to_txt():
train_txt_path = "/content/drive/My Drive/NLP/dataset/Fudan/train.txt" #训练数据txt
test_txt_path = "/content/drive/My Drive/NLP/dataset/Fudan/test.txt" #测试数据txt
train_content_path = "/content/drive/My Drive/NLP/dataset/Fudan/train_jieba.txt" #存储文本和标签txt
train_content_txt = open(train_content_path,"a",encoding="utf-8")
import re
def remove_punctuation(line, strip_all=True):
if strip_all:
rule = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]")
line = rule.sub('',line)
else:
punctuation = """!?。"#$%&'()*+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘'‛“”„‟…‧﹏"""
re_punctuation = "[{}]+".format(punctuation)
line = re.sub(re_punctuation, "", line)
return line.strip()
train_txt = open(train_txt_path,"r",encoding="utf-8")
for txt in train_txt.readlines(): #读取每一行的txt
txt = txt.strip() #去除掉\n
content_list=[]
label_str = txt.split("/")[-1].split("-")[-1] #先用/进行切割,获取列表中的最后一个,再利用-进行切割,获取最后一个
label_list = []
#以下for循环用于获取标签,遍历每个字符,如果遇到了数字,就终止
for s in label_str:
if s.isalpha():
label_list.append(s)
elif s.isalnum():
break
else:
print("出错了")
label = "".join(label_list) #将字符列表转换为字符串,得到标签
#print(label)
#以下用于获取所有文本
fp1 = open(txt,"r",encoding="gb18030",errors='ignore') #以gb18030的格式打开文件,errors='ignore'用于忽略掉超过该字符编码范围的字符
for line in fp1.readlines(): #读取每一行
#line = remove_punctuation(line)
line = jieba.lcut(line.strip(), cut_all=False) #进行分词,cut_all=False表明是精确分词,lcut()返回的分词后的列表
content_list.extend(line)
fp1.close()
content_str = " ".join(content_list) #转成字符串
#print(content_str)
train_content_txt.write(content_str+"\t"+label+"\n") #将文本 标签存到txt中
train_content_txt.close()![复制代码]()
同样的,我们也对test.txt中的进行相应的处理,这些重复的代码可以将其封装成一个函数,我们偷点懒就不改了:
![复制代码]()
def test_content_to_txt():
train_txt_path = "/content/drive/My Drive/NLP/dataset/Fudan/train.txt"
test_txt_path = "/content/drive/My Drive/NLP/dataset/Fudan/test.txt"
test_content_path = "/content/drive/My Drive/NLP/dataset/Fudan/test_jieba.txt"
test_content_txt = open(test_content_path,"a",encoding="utf-8")
import re
def remove_punctuation(line, strip_all=True):
if strip_all:
rule = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]")
line = rule.sub('',line)
else:
punctuation = """!?。"#$%&'()*+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘'‛“”„‟…‧﹏"""
re_punctuation = "[{}]+".format(punctuation)
line = re.sub(re_punctuation, "", line)
return line.strip()
test_txt = open(test_txt_path,"r",encoding="utf-8")
for txt in test_txt.readlines():
txt = txt.strip()
content_list=[]
label_str = txt.split("/")[-1].split("-")[-1]
label_list = []
#以下for循环用于获取标签
for s in label_str:
if s.isalpha():
label_list.append(s)
elif s.isalnum():
break
else:
print("出错了")
label = "".join(label_list)
#print(label)
#以下用于获取所有文本
fp1 = open(txt,"r",encoding="gb18030",errors='ignore')
for line in fp1.readlines():
#line = remove_punctuation(line)
line = jieba.lcut(line.strip(), cut_all=False)
content_list.extend(line)
fp1.close()
content_str = " ".join(content_list)
#print(content_str)
test_content_txt.write(content_str+"\t"+label+"\n")
test_content_txt.close()![复制代码]()
完成之后会生成train_jieba.txt和test_jieba.txt,我们简要看一下train_jieba.txt中的内容:
with open("/content/drive/My Drive/NLP/dataset/Fudan/train_jieba.txt","r",encoding="utf-8") as fp:
lines = fp.readlines()
for line in lines:
print(line)
break【 文献号 】 3 - 525 【 原文 出处 】 《 文艺报 》 【 原刊 地名 】 京 【 原刊 期号 】 20010705 【 原刊 页 号 】 ④ 【 分 类 号 】 J7 【 分 类 名 】 造型艺术 【 复印 期号 】 200105 【 标 题 】 关于 “ 艺术 与 科学 ” — — 《 艺术 与 科学 国际 作品展 》 理论 研讨会 纪要 【 正 文 】 杭 间 ( 清华大学美术学院 艺术 史论 系主任 ) : 由 清华大学 主办 、 我院 承办 的 《 艺术 与 科学 国际 作品展 》 已 在 中国美术馆 开幕 。 艺术 与 科学 的 关系 的 探讨 , 不仅 是 我们 此次 展览 的 命题 , 而且 也 是 全人类 发展 需要 探索 的 重要 主题 之一 , 因此 我们 希望 此 论题 能够 在 学术 层面 得到 更 深入 的 探讨 , 从而 为 未来 社会 发展 积累 充分 的 思想 资源 。 鉴于 此 , 我们 举办 了 这次 由 知名 批评家 参加 的 小型 理论 研讨会 , 希望 各位 踊跃发言 。 ( 以下 以 发言 先后 为序 ) 张凤昌 ( 清华大学美术学院 党委书记 ) : 我院 主办 的 这次 《 艺术 与 科学 国际 作品展 》 得到 了 社会各界 的 大力支持 , 展览 达到 了 预期 的 效果 。 对此 , 我 代表 学院 向 各位 理论家 的 支持 表示 最 衷心 的 感谢 。 艺术 与 科学 这个 命题 的 讨论 早已有之 , 但 在 我国 举办 如此 大规模 的 作品展 与 研讨会 , 这是 第一次 。 这是 一项 长期 的 任务 , 今后 还应 继续 发展 。 因为 我们 的 出发点 是 立足于 教育 , 因此 研究 艺术 与 科学 这个 命题 是 要 重点 考虑 怎样 培养 人 , 培养 德 、 智 、 体 全面 发展 的 人才 。 我 觉得 理论 在 其 中起 着 重要 的 作用 , 它 是 旗帜 , 是 实践 的 指导 。 我们 希望 能 得到 理论家 更 多 的 支持 和 帮助 。 王明 旨 ( 清华大学 副校长 、 美术学院 院长 ) : 非常高兴 众 位 美术 理论家 来 参加 这次 研讨 , 实际上 这次 “ 艺术 与 科学 ” 的 讨论 还 刚刚 起步 , 希 望 将来 能 与 众 兄弟 院校 共同 进行 进一步 的 研究 。 我院 提出 这个 大 的 理想化 的 主题 与 多年 的 学科 设置 和 专业 基础 有关 , 并入 清华大学 后 , 我们 处处 感到 了 清华大学 对 交叉性 的 综合 学科 的 重视 。 科学 本身 同 艺术 一样 是 广泛 而 生动 的 , 这是 二者 结合 的 基础 。 这次 的 展品 偏重于 美术 、 造型艺术 和 科技 之间 , 从小 的 切入点 来 探讨 大 的 课题 。 展品 从 内容 上 可以 分为 三个 方面 : 一部分 表达 了 艺术家 内心 对 科学 的 理解 , 另 一部分 是 科学家 通过 艺 术 表达 的 科学 成果 , 第三 部分 是 与 科学技术 结合 的 艺术设计 作品 。 可以 说 , 介入 科学 是 艺术 永恒 的 命题 , 也 是 新 时代 的 艺术家 了解 生活 的 不可 回 避 的 问题 , 艺术 教育 也 必须 作出 相应 的 调整 。 这次 展览 虽然 只是 初步 探讨 , 并非 十分 完善 和 理想 , 但 毕竟 是 正式 的 起步 , 我们 希望 诸位 能 从 理论 上 提出批评 和 指导 , 以利于 这项 工作 的 深入 发展 。 范迪安 ( 中央美术学院 副 院长 ) : 刚才 王 院长 介绍 了 主办 的 宗旨 、 构想 , 使 我们 对 这次 活动 有 了 更 深入 的 了解 。 我 认为 这次 展览 是 21 世纪 初 大型 的 社会 文化 活动 , 展览 热烈 , 观众 情绪高涨 , 接受度 和 欣喜 度均 超过 以往 。 其 意义 在于 : 第一 , 它 是 清华大学美术学院 多年 教育 积累 的 必然 结果 。 第二 , 它 完成 了 20 世纪 中国 本应 完成 的 命题 , 非常 具有 价值 。 既 完成 了 公众 多年 的 夙愿 , 又 是 引导 新世纪 对 该 命题 关注 的 起点 , 体现 了 学 院 领导班子 的 前瞻性 和 战略性 。 观众 通过 展览 , 不仅 学到 科学知识 , 而且 看到 了 艺术 创造 , 这种 艺术 的 、 文化 的 营养 是 社会 大众 所 需要 的 。 第三 , 展品 多以 视觉 传达 形式 出现 , 是 最 广泛 的 视觉 传达 发射 体 , 形式 前所未有 , 体现 了 当代 文化 传播 手段 。 总之 , 作为 一个 展览 , 能够 基于 一个 最 广泛 的 文化 层面 , 并 具有 相当 的 文化 前瞻性 、 当代 性是 其它 展览 少有 的 。 但是 , 对 具体 命题 的 艺术化 创作 , 在 艺术 与 科学 原理 上 的 思考 还有 待 提 高 。 程 大利 ( 中国 美术 出版 集团 副总 编辑 ) : 上个世纪 提出 的 “ 科学 与 民主 ” 与 “ 艺术 与 科学 ” 一样 , 是 一种 文化 理想 , 具有 指向性 。 看 了 这个 展览 , 我 首先 感到 这是 一个 非常 了不起 的 展览 , 是 一个 经过 精心 准备 的 有 理性 思考 的 展览 , 清华大学 提出 这个 题目 , 是 一个 非常 宏大 的 命题 , 具 有 长远 意义 。 另外 我 想 提出 一个 问题 , 即 艺术 不 应该 仅 是 科学 的 注脚 , 科学 也 不 应仅 是 艺术 的 拐杖 。 去年 《 中国 文化 报 》 有 一个 讨论 , 讨论 科学 与 人文 的 关系 , 可惜 它 浅尝辄止 ; 科学 使人 认识 物质 世界 , 但 科学 的 高度 发展 带来 了 许多 负面 问题 , 艺术 使人 认识 美 , 它 的 最大 功能 应是 净化 人 、 抒发 人类 的 情感 , 二者 的 结合 是 人类 的 理想 , 如果 结合 得 好 了 , 人类 就 进步 了 。 今天 艺术 教育 最 失败 的 地方 是 忽略 了 情感 教育 , 艺术 教育 的 问 题 是 培养 真正 的 人 。 长期以来 , 理工科 学生 的 艺术 素质 薄弱 是 我国 教育界 的 突出 问题 之一 , 大大 限制 了 科学 的 发展 。 应该 看到 , 科学 本身 也 是 美 的 , 量子 物理 、 纳米 世界 都 是 美的 , 科学 与 艺术 是 两翼 , 缺一不可 , 没有 人文 指向 的 科学 的 发展 是 多么 可怕 。 因此 , 这次 展览 是 个 创举 , 在 对 年 轻 科学家 的 培养 方面 有 巨大 的 促进作用 。 如果 我们 真正 弄清 了 艺术 与 科学 的 关系 , 其 意义 是 不可估量 的 。 林 木 ( 四川大学 艺术系 教授 ) : 我 注意 到 这次 “ 艺术 与 科学 ” 研讨会 发言 的 构成 人 主要 是 科学家 、 画家 , 思维 导向 主要 是 自然科学 。 可以 说 , 20 世纪 人们 对 科学 的 强调 非常 突出 。 值得注意 的 是 , “ 五四 ” 的 两面 旗帜 “ 民主 ” 和 “ 科学 ” 在 当时 的 美术界 是 对立 的 。 他们 张扬 人性 、 民 主 、 生命 意识 , 反对 科学 的 写实主义 , 这种 对立 很 奇怪 。 科学主义 对 科学研究 的 方法论 、 价值观 较为 关注 , 它 利用 科学 的 权威 做 与 科学 无关 的 事 , 在 20 世纪 较为 普遍 , 这是 应该 注意 的 问题 。 我 认为 , 人文科学 应 在 科学 与 艺术 的 结合 中 产生 重要 的 作用 。 人们 对 科学 的 宏观 与 微观 的 思考 演化 为 哲学 、 宗教 、 历史 的 思考 , 反过来 形成 对 艺术 的 引导 。 这次 展览 的 作品 , 不少 很 新颖 , 但 也 有 很多 只是 对 科学 进行 了 图解 , 比较 牵强 , 因此 值 得 进一步 研究 。 岛 子 ( 四川 美术学院 美术学 系主任 、 教授 ) : 我 认为 这次 “ 艺术 与 科学 ” 大展 开启 了 21 世纪 艺术 教育 的 思路 和 框架 。 1998 年 我 到 川美 任教 以来 , 深刻 地 感到 了 美术 学科 缺少 科学性 , 即 国家教委 的 学科 目录 与 社会 需求 有 很大 的 矛盾 , 美术学 的 分类 既 高度 分化 又 高度 融合 。 在 我国 , 人 文 科学 的 范围 界定 还有 待 研究 。 我们 应 关注 学科 内部 的 科学 问题 。 21 世纪 的 素质教育 应 包括 哪些 内容 呢 ? 我 注意 到 清华大学美术学院 艺术 史论 系 开设 了 社会学 课程 , 这 一点 值得 学习 。 人文科学 跟 自然科学 、 社会科学 需要 融合 。 21 世纪 我们 学院 的 建设者 任务 将会 十分艰巨 , 因为 高科技 的 信 息 时代 对 教学 的 冲击 是 不可避免 的 。 它 所 带来 的 知识 传承 问题 , 使 人文 学者 回归 到 前 现代 的 角色 , 即 成为 世界 意义 的 守护者 和 阐释 者 。 水天 中 ( 中国艺术研究院 美术 研究所 研究员 ) : 《 艺术 与 科学 国际 作品展 》 和 “ 艺术 与 科学 理论 研讨会 ” 是 近年 国内 美术界 规模 最大 、 规格 最高 的 学术活动 。 展览 与 研讨会 都 有 许多 使人 耳目一新 的 内容 , 打破 了 艺术 活动 只 着眼于 艺术 圈 之内 的 局限 , 开辟 了 美术 教学 、 美术 实践 、 美术 理论 与 姐妹 学科 交流 借鉴 的 局面 , 为 中国 美术 引来 一股 清风 。 对于 艺术 的 发展 来说 , 它 的 意义 是 在 艺术 与 社会 、 艺术 与 政治 、 艺术 与 个人 感情 … … 之外 , 引导 人们 注视 一条 新 的 思路 , 尝试 一种 新 的 艺术 活动 方式 , 走出 新 的 艺术 通道 。 这是 一条 有 生气 、 有 活力 的 通道 , 它 的 价值 不会 在 其它 通道 之下 。 对于 清华大学美术学院 来说 , “ 艺术 与 科学 ” 还 可以 成为 一个 长期 发展 目标 , 成为 学术 和 办学 风格 上 的 一种 理想 。 当 我们 说 “ 高雅 艺术 ” 的 时候 , 往往 联想起 传统 的 、 古老 的 文化 情趣 。 实际上 艺术 与 科学 也 可以 达到 一种 高雅 的 文化 情趣 ; 当 我们 说 “ 先锋 艺术 ” 的 时候 , 往往 联想起 对 社会 生活 的 反讽 和 对 个人 处境 的 焦虑 , 实际上 艺术 与 科学 、 科学 与 人 的 复杂 关系 , 也 应该 成为 艺术创作 上 的 “ 先锋 问题 ” 。 展览会 的 作品 多 , 中国美术馆 的 场地 小 , 这使 展出 效果 不够 理想 。 除了 展出 场馆 条件 的 限制 外 , 从 艺术 水平 或者 展览会 的 主题 看 , 如果 将 一 些 可有可无 的 作品 删减 ( 如果 减去 四分之一 ) , 展览 的 整体 水准 就 会 明显 提升 。 作品 的 评奖 结果 也 值得 进一步 讨论 , 有些 获奖作品 并 不 具有 艺术 或者 科学 思想 方面 的 创造性 , 有些 作品 甚至 不能 代表 作者 原有 的 艺术 水平 。 在 题材 和 作品 的 人文精神 方面 , 宜作 周密 的 考量 , 例如 科学研究 和 科 技 运用 的 伦理 问题 , 这 已 是 全球性 的 不容 回避 的 话题 。 从 展览 作品 和 研讨会 发言 看 , 这是 一次 称颂 科学 与 艺术 的 集会 , 大家 主要 着眼于 两者 的 光明面 , 而 忽视 了 它们 目前 发展 的 问题 。 在 观察 角度 上 , 国内 艺术家 和 学者 偏向 于 称颂 历史 , 回顾 往昔 的 辉煌 , 在 思路 上 习惯于 绪论 、 概说 式 的 “ 宏大 叙事 ” , 缺少 国外 艺术家 和 学者 那种 对 具体 问 题 的 深入研究 。 这 已经 成为 中国 美术 理论界 的 流弊 。 丁 宁 ( 北京大学 艺术 学系 教授 ) : 我 想 谈 以下几点 : 第一 , 艺术 的 发展 要 进入 公众 领域 。 可以 说 , 这次 展览 引起 了 久违 的 关注 , 它 打破 了 近年 美术 领域 的 圈子 化 , 使得 艺术 进入 了 公众 的 精神 领域 , 随着 时间 的 推移 , 其 价值 会 逐渐 彰显 出来 。 第二 , 这次 展览 把 “ 艺术 与 科学 ” 作为 主 题 阐述 是 90 年代 以来 美术界 的 高峰 事件 , 可以 改变 当代 美术 的 专家 化 思路 , 具有 鲜明 的 时代感 和 重要 的 启示 作用 。 第三 , 展览 提出 了 艺术 教育 的 新 方向 , 有助于 改变 对纯 艺术 的 过分 倚重 。 艺术 要 走向 现实 的 发展 , 离不开 科学 的 成分 。 第四 , 这是 一次 美术 活动 国际性 的 探索 。 希望 今后 能继 续 进行 下去 。 第五 , 展览 的 不足 在于 对 研究 的 前沿 情况 把握 不够 , 新思路 不足 。 刘 龙庭 ( 人民美术出版社 编审 ) : 这次 展览 的 命题 是 社会 大 发展 的 产物 。 展览 既 具有 前瞻性 、 开创性 , 又 具有 总结性 、 启示 性 , 对 公众 产生 了 不可 忽视 的 影响 。 中央 工艺 美院 虽然 并入 清华大学 的 时间 并 不长 , 但 贡献 很大 。 我们 也 应该 看到 , 科学 与 艺术 毕竟 不同 , 在 强调 联系 时 , 也 有 区别 。 这是 一个 很大 的 命题 , 需要 继续 深入 讨论 下去 。 在 当前 中国 科学 比较落后 的 情况 下 , 人文科学 也 并 不 先进 , 希望 清华 美院 继续 张扬 自己 的 艺术 个性 , 取得 更大 的 发展 。 吕品 田 ( 中国艺术研究院 美术 研究所 研究员 ) : 清华大学 花 了 如此 大 的 力气 和 声势 , 用 展览 和 研讨会 的 形式 提出 “ 艺术 与 科学 ” 这样 一个 命 题 , 是 具有 历史性 的 、 前瞻性 的 。 但 对 中国 来讲 , 历史性 这 一块 确实 是 中国 的 问题 , 因为 西方 对 “ 艺术 与 科学 ” 的 关注 在 20 世纪 就 大量 地 展开 了 。 而 中国 在 20 世纪 还 并未 真正 地 意识 到 这样 一种 关系 , 并 把 它 作为 一个 命题 提出 来 。 因此 , 这个 命题 的 前瞻性 我 认为 是 国际性 的 , 全球性 的 。 不 仅 是 中国 人 , 整个 生活 在 地球 上 的 人 都 在 关注 这样 一对 关系 。 在我看来 , 不管 是 科学 还是 艺术 , 这 两个 概念 都 是 西方式 的 。 甚至 把 它 作为 一种 关 系 问题 摆出来 , 也 是 一种 西方式 的 思想 。 在 这种 思想 贯穿 着 一种 形而上学 的 传统 , 从 古希腊 到 今天 信息时代 的 二进位制 语言 , 这 中间 是 有着 深刻 联系 的 。 但 实际上 西方 这种 思想 从 一 开始 就 包含 一种 矛盾 。 一方面 , 它 把 人 解释 成 一种 自由 的 存在 , 具有 无限 发展性 、 丰富性 、 非 专门化 的 存在 , 而 另一方面 它 在 解释 自然 、 探索 自然 时 , 又 把 这个 世界 理解 为 有 一个 最终 的 终极 时代 。 在 自然科学 上要 探讨 物质 的 终极 时代 , 在 人文科学 上要 探讨 体现 、 反映 这种 终极 时代 的 真理 。 因此 , 无论 自然科学 , 还是 人文科学 , 在 西方 人 看来 是 一 回事 , 本质 上 它 有 一种 大 科学 思想 。 由此 , 矛盾 从 一 开始 便 产生 了 。 在 古典 时代 , 这样 一种 矛盾 是 不 明显 的 , 文艺复兴 后 , 随着 西方 对 人 的 强调 , 所谓 人文主义 崛起 后 , 必然 就 会 把 这种 矛盾 带 出来 。 对 世界 认识 的 问题 和 人 对 自己 本身 认识 的 问题 矛盾重重 。 这种 矛盾 导致 科学 与 艺术 从 原有 的 混沌 状态 分裂 出来 , 并 产生 科学 与 艺术 。 而 在 今天 大谈 科学 与 艺术 , 它 实际上 反映 了 我们 现在 的 一种 生存 状态 , 一种 力图 改变 我们 现在 对 世界 认识 和 把握 的 矛盾 状态 。 20 世纪 上半叶 , 人类 对 科学 、 现代文明 是持 一种 乐观 的 态度 的 , 中叶 以后 , 这样 一种 状态 发生 了 变化 , 科学 所 带来 的 一些 现实 问题 迫使 我们 去 回头 反思 , 这 是 由 生存环境 引发 的 一种 物质性 问题 。 只有 这些 物质性 的 问题 才能 在 科学时代 打动 这些 被 科学 思 想 所 占领 、 控制 的 人群 。 由此 , 科学 与 艺术 作为 一种 关系 命题 暴露 出来 。 从 这样 一种 意义 上 说 , 提出 这样 一个 前瞻性 的 命题 , 是 非常 有 价值 的 。 从 展览 来说 , 我 感觉 有 三种 类型 的 作品 : 1 . 把 科学 思想 、 科学知识 加以 阐释 、 介绍 , 实际上 带有 一定 程度 的 科学 色彩 。 而 在 当下 , 它 又 具有 意识 形态 的 色彩 。 2 . 表现 现代科技 或用 现代科技 来 辅助 制作 的 作品 , 它 在 某种程度 上 显示 着 现代科技 的 力量 。 3 . 在 科学 的 条件 下 , 强调 对 人 的 生存 状 态 的 关注 , 强调 人 的 现实 体验 的 作品 。 实际上 , 从 艺术 与 科学 的 关系 的 角度看 , 这 一部分 作品 更 有 价值 。 如果 在 以后 还 将 继续 进行 展开讨论 , 我 认为 更应 关注 人 的 生存 状态 , 因为 在 让 人 生存 得 更 幸福 、 更好 的 目标 上 , 无论 科学 还是 艺术 , 它们 都 是 统一 的 。 邵大箴 ( 中央美术学院 教授 ) : 这次 展览 社会 反响 很大 , 收到 了 很 好 的 效果 。 虽然 也 有 不少 缺点 , 当 总的来说 还是 很 不错 的 。 科学 与 艺术 的 关系 问题 谈 不 清楚 , 已经 有 很多 的 讨论 , 李政道 先生 已经 是 第三次 提出 这个 问题 , 这次 是 最 重要 的 一次 , 并且 是 最大 的 一次 国际 研讨会 。 他 主要 强调 智慧 和 情感 , 艺术 也 是 , 科学 也 是 , 它们 本质 上 是 一样 的 , 讲得 很 对 。 而且 李政道 先生 讲 的 是 科学 、 自然科学 而 不是 讲 技术 。 科学 与 艺术 的 关系 发展 到 现在 , 包括 科学技术 与 艺术 的 关系 , 这个 问题 带有 一定 片面性 , 但 又 有 合理性 , 前面 有人 说 到 的 命题 的 公众 性 , 它 带有 普遍性 , 这是 一个 国际性 的 潮流 。 听说 浙江美术学院 曾经 请 哲学家 去 讲课 , 讲得 很 好 , 但是 有 的 艺术家 发问 : 你 懂 笔墨 吗 ? 这 很 可笑 , 哲学家 讲 的 是 普遍性 的 东西 , 艺术家 问 的 问题 有 一定 的 合理性 , 但 哲学家 谈 的 是 普遍性 的 东西 , 艺术家 谈 的 是 个别性 的 东西 。 这个 普遍性 的 东西 如果 我们 不去 研究 , 就 要 落后 。 个别性 的 东西 也 要 关注 , 例如 民族化 , 但是 要 在 普遍性 的 原则 下 。 科学 与 艺术 不管 以 何种 形式 发展 , 这个 命题 的 提出 都 带有 一定 前沿性 , 它 也 一定 会 推动 科学 与 艺术 的 发展 , 它们 的 结合 一定 会 产生 新 的 东西 。 西 川 ( 中央美术学院 副教授 ) : 刚才 各位 的 发言 已经 把 我 想到 的 一些 问题 差不多 都 谈到 了 , 活动 成功 的 地方 我 就 不 重复 了 。 我 没 参加 清华 的 讨论会 , 因此 , 只 根据 展览 谈 我 当时 产生 的 几个 印象 。 一 , 这是 一个 美术学院 所 做 的 跟 科学 有 关系 的 展览 , 而 不是 科学院 做 的 跟 艺术 有 关系 的 展览 。 因此 , 艺术 很 显然 地 呈现 一种 向 科学 靠拢 的 姿态 。 通过 现代科技 手段 , 把 一些 存在 于 现代 艺术 之中 的 现代 观念 介绍 给 大家 。 另外 , 艺术 本 身 显得 不 自然 , 由于 艺术 与 科学 在 社会 发展 中 的 不 对称 比例 , 似乎 艺术 观念 落后 于 科学 的 观念 。 同时 , 通过 这样 一个 展览 , 使 艺术 本身 表现 出来 的 科学 似乎 已经 落后 当代 科学 所 达到 的 水准 。 因为 当代 科学 的 技术 层面 , 它 所 达到 的 形而上 的 层面 都 已 远远 超出 我们 的 想象 。 二 , 作品 不看 标示 牌 , 基本上 能 猜测出 是 哪 国人 所 做 , 尤其 是 中国 人 的 作品 更为 明显 。 为什么 会 如此 ? 这 里面 实际上 存在 一个 观念 置换 的 过程 , 中国 人 的 作品 不是 以 科学 精神 来 指导 , 而是 把 科学 与 艺术 的 空间概念 置换 成 古代 与 现代 的 时间 概念 。 三 , 科学 本身 在 其 现代 研究 中 已经 实现 了 科学 本身 的 转身 。 比 如 物理学 走到 核 物理学 , 最后 变成 对 社会 生活 的 破坏 , 这种 科学 转身 所 引起 的 当代 科学 对 伦理学 所 产生 的 挑战 , 事实上 在 这个 展览 中 很少 涉及 , 这个 展览 基本上 是 艺术 向 科学 靠拢 , 艺术 为 科学 唱赞歌 。 科学 本身 所 包含 的 那些 复杂 命题 、 转身 、 悖论 基本上 艺术家 没有 触及 到 。 四 , 在 科学 与 艺术 这样 一个 大题目 下 , 还 可以 分列 一些 小题目 进行 。 张晓凌 ( 中国艺术研究院 美术 研究所 研究员 ) : 我 最早 介入 “ 艺术 与 科学 ” 这个 主题 是 作为 撰稿人 为 这个 展览 搞 一个 专题片 , 一共 五集 , 我 写 第一集 , 介绍 艺术 与 科学 的 历史 关系 及 发展 脉落 , 并 由此 引发 一些 问题 。 艺术 与 科学 本身 一样 , 最早 的 艺术家 就是 科学家 , 直到 近代 科学 产生 以后 , 才 出现 一些 问题 , 艺术 与 科学 正式 分离 。 展览 有 不足 也 有 价值 的 地方 。 1 . 展品 可 减掉 三分之一 , 一些 作品 与 主题 没有 太大 的 关系 , 而且 质 量 平庸 。 另外 , 700 件 作品 使得 展厅 太 拥挤 , 展览 效果 不是太好 。 2 . 这次 展览 是 一个 开端 , 是 一个 仪式 。 但 进入 仪式 后 , 它 对 科学 、 科学 本身 的 一些 问题 , 对 当代人 的 生存 状态 反思 不够 , 艺术 与 科学 共同 作用 产生 力量 , 并 带来 震撼 的 作品 太 少 。 意义 : 尽管 有些 不足 , 但 其 成绩 、 价值 、 意 义 仍 远远 超过 不足 。 1 . 通过 这个 展览 , 它 表明 艺术 不是 点缀 、 美化 , 也 不是 装饰 , 它 是 一种 生存 方式 、 思维 方式 , 而 这种 方式 可以 通过 科学 的 方 式 展示 给 人们 。 2 . 这个 展览 完成 后 , 全国 美展 与 它 的 距离 至少 有 10 年 以上 的 差距 。 另外 , 它 对 美术馆 本身 也 是 一种 讽刺 , 装置 、 影像 艺术 等等 都 纳入 了 这次 展览 之中 。 3 . 这个 展览 另外 一个 更 重要 的 意义 在于 它 的 象征意义 。 而 在 中国 的 美术界 、 教育界 跨入 21 世纪 时 , 这样 一个 展览 至少 表现 出 一种 和 西方 各国 同步 的 文化 姿态 。 因为 这个 课题 也 是 同 时期 西方 关注 的 课题 , 在 国内 也 从未 提出 过 , 它 的 解决 程度 不管 如何 , 其 象征意义 必定 是 深远 的 。 出席 研讨会 的 还有 : 刘巨德 副 院长 、 包林 教授 、 陈瑞林 副教授 、 尚刚 副教授 等 。 ( 田君 、 海军 根据 录音 整理 , 未经 本人 审阅 。 标题 为 编者 所 加 ) Art
文本是通过空格进行了分词,最后的标签和文本之间用制表符进行了分割。
我们接下来要对标签映射成具体的数值,代码如下:
label = []
with open("/content/drive/My Drive/NLP/dataset/Fudan/train_jieba.txt","r",encoding="utf-8") as fp:
lines = fp.readlines()
for line in lines:
line = line.strip().split("\t")
if len(line) == 2:
label.append(line[1])
label = set(label)
label_to_idx = list(zip(label,range(len(label))))
label_to_idx_dict = {}
idx_to_label_dict = {}
for k,v in label_to_idx:
label_to_idx_dict[k] = v
idx_to_label_dict[v] = k
print(label_to_idx_dict)
print(idx_to_label_dict)结果:如果不想标签对应的值每次都变,最好将其保存在txt中
{'Energy': 0, 'Enviornment': 1, 'Computer': 2, 'Education': 3, 'Military': 4, 'Philosophy': 5, 'Law': 6, 'Electronics': 7, 'Sports': 8, 'History': 9, 'Space': 10, 'Communication': 11, 'Economy': 12, 'Mine': 13, 'Agriculture': 14, 'Medical': 15, 'Art': 16, 'Transport': 17, 'Literature': 18, 'Politics': 19}
{0: 'Energy', 1: 'Enviornment', 2: 'Computer', 3: 'Education', 4: 'Military', 5: 'Philosophy', 6: 'Law', 7: 'Electronics', 8: 'Sports', 9: 'History', 10: 'Space', 11: 'Communication', 12: 'Economy', 13: 'Mine', 14: 'Agriculture', 15: 'Medical', 16: 'Art', 17: 'Transport', 18: 'Literature', 19: 'Politics'}接下来我们构建真正的训练集和测试集,首先是训练集:
train_data = []
train_label = []
with open("/content/drive/My Drive/NLP/dataset/Fudan/train_jieba.txt","r",encoding="utf-8") as fp:
lines = fp.readlines()
for line in lines:
line = line.strip().split("\t")
if len(line) == 2:
train_data.append([line[0]])
train_label.append([label_to_idx_dict[line[1]]])
train_data = np.array(train_data)
train_label = np.array(train_label)
print(train_data.shape)
print(train_label.shape)
print(train_data[:2])
print(train_label[:2])![复制代码]()
(9803, 1)
(9803, 1)
[['【 文献号 】 3 - 525 【 原文 出处 】 《 文艺报 》 【 原刊 地名 】 京 【 原刊 期号 】 20010705 【 原刊 页 号 】 ④ 【 分 类 号 】 J7 【 分 类 名 】 造型艺术 【 复印 期号 】 200105 【 标 题 】 关于 “ 艺术 与 科学 ” — — 《 艺术 与 科学 国际 作品展 》 理论 研讨会 纪要 【 正 文 】 杭 \u3000 间 ( 清华大学美术学院 艺术 史论 系主任 ) : 由 清华大学 主办 、 我院 承办 的 《 艺术 与 科学 国际 作品展 》 已 在 中国美术馆 开幕 。 艺术 与 科学 的 关系 的 探讨 , 不仅 是 我们 此次 展览 的 命题 , 而且 也 是 全人类 发展 需要 探索 的 重要 主题 之一 , 因此 我们 希望 此 论题 能够 在 学术 层面 得到 更 深入 的 探讨 , 从而 为 未来 社会 发展 积累 充分 的 思想 资源 。 鉴于 此 , 我们 举办 了 这次 由 知名 批评家 参加 的 小型 理论 研讨会 , 希望 各位 踊跃发言 。 ( 以下 以 发言 先后 为序 ) 张凤昌 ( 清华大学美术学院 党委书记 ) : 我院 主办 的 这次 《 艺术 与 科学 国际 作品展 》 得到 了 社会各界 的 大力支持 , 展览 达到 了 预期 的 效果 。 对此 , 我 代表 学院 向 各位 理论家 的 支持 表示 最 衷心 的 感谢 。 艺术 与 科学 这个 命题 的 讨论 早已有之 , 但 在 我国 举办 如此 大规模 的 作品展 与 研讨会 , 这是 第一次 。 这是 一项 长期 的 任务 , 今后 还应 继续 发展 。 因为 我们 的 出发点 是 立足于 教育 , 因此 研究 艺术 与 科学 这个 命题 是 要 重点 考虑 怎样 培养 人 , 培养 德 、 智 、 体 全面 发展 的 人才 。 我 觉得 理论 在 其 中起 着 重要 的 作用 , 它 是 旗帜 , 是 实践 的 指导 。 我们 希望 能 得到 理论家 更 多 的 支持 和 帮助 。 王明 旨 ( 清华大学 副校长 、 美术学院 院长 ) : 非常高兴 众 位 美术 理论家 来 参加 这次 研讨 , 实际上 这次 “ 艺术 与 科学 ” 的 讨论 还 刚刚 起步 , 希 望 将来 能 与 众 兄弟 院校 共同 进行 进一步 的 研究 。 我院 提出 这个 大 的 理想化 的 主题 与 多年 的 学科 设置 和 专业 基础 有关 , 并入 清华大学 后 , 我们 处处 感到 了 清华大学 对 交叉性 的 综合 学科 的 重视 。 科学 本身 同 艺术 一样 是 广泛 而 生动 的 , 这是 二者 结合 的 基础 。 这次 的 展品 偏重于 美术 、 造型艺术 和 科技 之间 , 从小 的 切入点 来 探讨 大 的 课题 。 展品 从 内容 上 可以 分为 三个 方面 : 一部分 表达 了 艺术家 内心 对 科学 的 理解 , 另 一部分 是 科学家 通过 艺 术 表达 的 科学 成果 , 第三 部分 是 与 科学技术 结合 的 艺术设计 作品 。 可以 说 , 介入 科学 是 艺术 永恒 的 命题 , 也 是 新 时代 的 艺术家 了解 生活 的 不可 回 避 的 问题 , 艺术 教育 也 必须 作出 相应 的 调整 。 这次 展览 虽然 只是 初步 探讨 , 并非 十分 完善 和 理想 , 但 毕竟 是 正式 的 起步 , 我们 希望 诸位 能 从 理论 上 提出批评 和 指导 , 以利于 这项 工作 的 深入 发展 。 范迪安 ( 中央美术学院 副 院长 ) : 刚才 王 院长 介绍 了 主办 的 宗旨 、 构想 , 使 我们 对 这次 活动 有 了 更 深入 的 了解 。 我 认为 这次 展览 是 21 世纪 初 大型 的 社会 文化 活动 , 展览 热烈 , 观众 情绪高涨 , 接受度 和 欣喜 度均 超过 以往 。 其 意义 在于 : 第一 , 它 是 清华大学美术学院 多年 教育 积累 的 必然 结果 。 第二 , 它 完成 了 20 世纪 中国 本应 完成 的 命题 , 非常 具有 价值 。 既 完成 了 公众 多年 的 夙愿 , 又 是 引导 新世纪 对 该 命题 关注 的 起点 , 体现 了 学 院 领导班子 的 前瞻性 和 战略性 。 观众 通过 展览 , 不仅 学到 科学知识 , 而且 看到 了 艺术 创造 , 这种 艺术 的 、 文化 的 营养 是 社会 大众 所 需要 的 。 第三 , 展品 多以 视觉 传达 形式 出现 , 是 最 广泛 的 视觉 传达 发射 体 , 形式 前所未有 , 体现 了 当代 文化 传播 手段 。 总之 , 作为 一个 展览 , 能够 基于 一个 最 广泛 的 文化 层面 , 并 具有 相当 的 文化 前瞻性 、 当代 性是 其它 展览 少有 的 。 但是 , 对 具体 命题 的 艺术化 创作 , 在 艺术 与 科学 原理 上 的 思考 还有 待 提 高 。 程 大利 ( 中国 美术 出版 集团 副总 编辑 ) : 上个世纪 提出 的 “ 科学 与 民主 ” 与 “ 艺术 与 科学 ” 一样 , 是 一种 文化 理想 , 具有 指向性 。 看 了 这个 展览 , 我 首先 感到 这是 一个 非常 了不起 的 展览 , 是 一个 经过 精心 准备 的 有 理性 思考 的 展览 , 清华大学 提出 这个 题目 , 是 一个 非常 宏大 的 命题 , 具 有 长远 意义 。 另外 我 想 提出 一个 问题 , 即 艺术 不 应该 仅 是 科学 的 注脚 , 科学 也 不 应仅 是 艺术 的 拐杖 。 去年 《 中国 文化 报 》 有 一个 讨论 , 讨论 科学 与 人文 的 关系 , 可惜 它 浅尝辄止 ; 科学 使人 认识 物质 世界 , 但 科学 的 高度 发展 带来 了 许多 负面 问题 , 艺术 使人 认识 美 , 它 的 最大 功能 应是 净化 人 、 抒发 人类 的 情感 , 二者 的 结合 是 人类 的 理想 , 如果 结合 得 好 了 , 人类 就 进步 了 。 今天 艺术 教育 最 失败 的 地方 是 忽略 了 情感 教育 , 艺术 教育 的 问 题 是 培养 真正 的 人 。 长期以来 , 理工科 学生 的 艺术 素质 薄弱 是 我国 教育界 的 突出 问题 之一 , 大大 限制 了 科学 的 发展 。 应该 看到 , 科学 本身 也 是 美 的 , 量子 物理 、 纳米 世界 都 是 美的 , 科学 与 艺术 是 两翼 , 缺一不可 , 没有 人文 指向 的 科学 的 发展 是 多么 可怕 。 因此 , 这次 展览 是 个 创举 , 在 对 年 轻 科学家 的 培养 方面 有 巨大 的 促进作用 。 如果 我们 真正 弄清 了 艺术 与 科学 的 关系 , 其 意义 是 不可估量 的 。 林 \u3000 木 ( 四川大学 艺术系 教授 ) : 我 注意 到 这次 “ 艺术 与 科学 ” 研讨会 发言 的 构成 人 主要 是 科学家 、 画家 , 思维 导向 主要 是 自然科学 。 可以 说 , 20 世纪 人们 对 科学 的 强调 非常 突出 。 值得注意 的 是 , “ 五四 ” 的 两面 旗帜 “ 民主 ” 和 “ 科学 ” 在 当时 的 美术界 是 对立 的 。 他们 张扬 人性 、 民 主 、 生命 意识 , 反对 科学 的 写实主义 , 这种 对立 很 奇怪 。 科学主义 对 科学研究 的 方法论 、 价值观 较为 关注 , 它 利用 科学 的 权威 做 与 科学 无关 的 事 , 在 20 世纪 较为 普遍 , 这是 应该 注意 的 问题 。 我 认为 , 人文科学 应 在 科学 与 艺术 的 结合 中 产生 重要 的 作用 。 人们 对 科学 的 宏观 与 微观 的 思考 演化 为 哲学 、 宗教 、 历史 的 思考 , 反过来 形成 对 艺术 的 引导 。 这次 展览 的 作品 , 不少 很 新颖 , 但 也 有 很多 只是 对 科学 进行 了 图解 , 比较 牵强 , 因此 值 得 进一步 研究 。 岛 \u3000 子 ( 四川 美术学院 美术学 系主任 、 教授 ) : 我 认为 这次 “ 艺术 与 科学 ” 大展 开启 了 21 世纪 艺术 教育 的 思路 和 框架 。 1998 年 我 到 川美 任教 以来 , 深刻 地 感到 了 美术 学科 缺少 科学性 , 即 国家教委 的 学科 目录 与 社会 需求 有 很大 的 矛盾 , 美术学 的 分类 既 高度 分化 又 高度 融合 。 在 我国 , 人 文 科学 的 范围 界定 还有 待 研究 。 我们 应 关注 学科 内部 的 科学 问题 。 21 世纪 的 素质教育 应 包括 哪些 内容 呢 ? 我 注意 到 清华大学美术学院 艺术 史论 系 开设 了 社会学 课程 , 这 一点 值得 学习 。 人文科学 跟 自然科学 、 社会科学 需要 融合 。 21 世纪 我们 学院 的 建设者 任务 将会 十分艰巨 , 因为 高科技 的 信 息 时代 对 教学 的 冲击 是 不可避免 的 。 它 所 带来 的 知识 传承 问题 , 使 人文 学者 回归 到 前 现代 的 角色 , 即 成为 世界 意义 的 守护者 和 阐释 者 。 水天 中 ( 中国艺术研究院 美术 研究所 研究员 ) : 《 艺术 与 科学 国际 作品展 》 和 “ 艺术 与 科学 理论 研讨会 ” 是 近年 国内 美术界 规模 最大 、 规格 最高 的 学术活动 。 展览 与 研讨会 都 有 许多 使人 耳目一新 的 内容 , 打破 了 艺术 活动 只 着眼于 艺术 圈 之内 的 局限 , 开辟 了 美术 教学 、 美术 实践 、 美术 理论 与 姐妹 学科 交流 借鉴 的 局面 , 为 中国 美术 引来 一股 清风 。 对于 艺术 的 发展 来说 , 它 的 意义 是 在 艺术 与 社会 、 艺术 与 政治 、 艺术 与 个人 感情 … … 之外 , 引导 人们 注视 一条 新 的 思路 , 尝试 一种 新 的 艺术 活动 方式 , 走出 新 的 艺术 通道 。 这是 一条 有 生气 、 有 活力 的 通道 , 它 的 价值 不会 在 其它 通道 之下 。 对于 清华大学美术学院 来说 , “ 艺术 与 科学 ” 还 可以 成为 一个 长期 发展 目标 , 成为 学术 和 办学 风格 上 的 一种 理想 。 当 我们 说 “ 高雅 艺术 ” 的 时候 , 往往 联想起 传统 的 、 古老 的 文化 情趣 。 实际上 艺术 与 科学 也 可以 达到 一种 高雅 的 文化 情趣 ; 当 我们 说 “ 先锋 艺术 ” 的 时候 , 往往 联想起 对 社会 生活 的 反讽 和 对 个人 处境 的 焦虑 , 实际上 艺术 与 科学 、 科学 与 人 的 复杂 关系 , 也 应该 成为 艺术创作 上 的 “ 先锋 问题 ” 。 展览会 的 作品 多 , 中国美术馆 的 场地 小 , 这使 展出 效果 不够 理想 。 除了 展出 场馆 条件 的 限制 外 , 从 艺术 水平 或者 展览会 的 主题 看 , 如果 将 一 些 可有可无 的 作品 删减 ( 如果 减去 四分之一 ) , 展览 的 整体 水准 就 会 明显 提升 。 作品 的 评奖 结果 也 值得 进一步 讨论 , 有些 获奖作品 并 不 具有 艺术 或者 科学 思想 方面 的 创造性 , 有些 作品 甚至 不能 代表 作者 原有 的 艺术 水平 。 在 题材 和 作品 的 人文精神 方面 , 宜作 周密 的 考量 , 例如 科学研究 和 科 技 运用 的 伦理 问题 , 这 已 是 全球性 的 不容 回避 的 话题 。 从 展览 作品 和 研讨会 发言 看 , 这是 一次 称颂 科学 与 艺术 的 集会 , 大家 主要 着眼于 两者 的 光明面 , 而 忽视 了 它们 目前 发展 的 问题 。 在 观察 角度 上 , 国内 艺术家 和 学者 偏向 于 称颂 历史 , 回顾 往昔 的 辉煌 , 在 思路 上 习惯于 绪论 、 概说 式 的 “ 宏大 叙事 ” , 缺少 国外 艺术家 和 学者 那种 对 具体 问 题 的 深入研究 。 这 已经 成为 中国 美术 理论界 的 流弊 。 丁 \u3000 宁 ( 北京大学 艺术 学系 教授 ) : 我 想 谈 以下几点 : 第一 , 艺术 的 发展 要 进入 公众 领域 。 可以 说 , 这次 展览 引起 了 久违 的 关注 , 它 打破 了 近年 美术 领域 的 圈子 化 , 使得 艺术 进入 了 公众 的 精神 领域 , 随着 时间 的 推移 , 其 价值 会 逐渐 彰显 出来 。 第二 , 这次 展览 把 “ 艺术 与 科学 ” 作为 主 题 阐述 是 90 年代 以来 美术界 的 高峰 事件 , 可以 改变 当代 美术 的 专家 化 思路 , 具有 鲜明 的 时代感 和 重要 的 启示 作用 。 第三 , 展览 提出 了 艺术 教育 的 新 方向 , 有助于 改变 对纯 艺术 的 过分 倚重 。 艺术 要 走向 现实 的 发展 , 离不开 科学 的 成分 。 第四 , 这是 一次 美术 活动 国际性 的 探索 。 希望 今后 能继 续 进行 下去 。 第五 , 展览 的 不足 在于 对 研究 的 前沿 情况 把握 不够 , 新思路 不足 。 刘 龙庭 ( 人民美术出版社 编审 ) : 这次 展览 的 命题 是 社会 大 发展 的 产物 。 展览 既 具有 前瞻性 、 开创性 , 又 具有 总结性 、 启示 性 , 对 公众 产生 了 不可 忽视 的 影响 。 中央 工艺 美院 虽然 并入 清华大学 的 时间 并 不长 , 但 贡献 很大 。 我们 也 应该 看到 , 科学 与 艺术 毕竟 不同 , 在 强调 联系 时 , 也 有 区别 。 这是 一个 很大 的 命题 , 需要 继续 深入 讨论 下去 。 在 当前 中国 科学 比较落后 的 情况 下 , 人文科学 也 并 不 先进 , 希望 清华 美院 继续 张扬 自己 的 艺术 个性 , 取得 更大 的 发展 。 吕品 田 ( 中国艺术研究院 美术 研究所 研究员 ) : 清华大学 花 了 如此 大 的 力气 和 声势 , 用 展览 和 研讨会 的 形式 提出 “ 艺术 与 科学 ” 这样 一个 命 题 , 是 具有 历史性 的 、 前瞻性 的 。 但 对 中国 来讲 , 历史性 这 一块 确实 是 中国 的 问题 , 因为 西方 对 “ 艺术 与 科学 ” 的 关注 在 20 世纪 就 大量 地 展开 了 。 而 中国 在 20 世纪 还 并未 真正 地 意识 到 这样 一种 关系 , 并 把 它 作为 一个 命题 提出 来 。 因此 , 这个 命题 的 前瞻性 我 认为 是 国际性 的 , 全球性 的 。 不 仅 是 中国 人 , 整个 生活 在 地球 上 的 人 都 在 关注 这样 一对 关系 。 在我看来 , 不管 是 科学 还是 艺术 , 这 两个 概念 都 是 西方式 的 。 甚至 把 它 作为 一种 关 系 问题 摆出来 , 也 是 一种 西方式 的 思想 。 在 这种 思想 贯穿 着 一种 形而上学 的 传统 , 从 古希腊 到 今天 信息时代 的 二进位制 语言 , 这 中间 是 有着 深刻 联系 的 。 但 实际上 西方 这种 思想 从 一 开始 就 包含 一种 矛盾 。 一方面 , 它 把 人 解释 成 一种 自由 的 存在 , 具有 无限 发展性 、 丰富性 、 非 专门化 的 存在 , 而 另一方面 它 在 解释 自然 、 探索 自然 时 , 又 把 这个 世界 理解 为 有 一个 最终 的 终极 时代 。 在 自然科学 上要 探讨 物质 的 终极 时代 , 在 人文科学 上要 探讨 体现 、 反映 这种 终极 时代 的 真理 。 因此 , 无论 自然科学 , 还是 人文科学 , 在 西方 人 看来 是 一 回事 , 本质 上 它 有 一种 大 科学 思想 。 由此 , 矛盾 从 一 开始 便 产生 了 。 在 古典 时代 , 这样 一种 矛盾 是 不 明显 的 , 文艺复兴 后 , 随着 西方 对 人 的 强调 , 所谓 人文主义 崛起 后 , 必然 就 会 把 这种 矛盾 带 出来 。 对 世界 认识 的 问题 和 人 对 自己 本身 认识 的 问题 矛盾重重 。 这种 矛盾 导致 科学 与 艺术 从 原有 的 混沌 状态 分裂 出来 , 并 产生 科学 与 艺术 。 而 在 今天 大谈 科学 与 艺术 , 它 实际上 反映 了 我们 现在 的 一种 生存 状态 , 一种 力图 改变 我们 现在 对 世界 认识 和 把握 的 矛盾 状态 。 20 世纪 上半叶 , 人类 对 科学 、 现代文明 是持 一种 乐观 的 态度 的 , 中叶 以后 , 这样 一种 状态 发生 了 变化 , 科学 所 带来 的 一些 现实 问题 迫使 我们 去 回头 反思 , 这 是 由 生存环境 引发 的 一种 物质性 问题 。 只有 这些 物质性 的 问题 才能 在 科学时代 打动 这些 被 科学 思 想 所 占领 、 控制 的 人群 。 由此 , 科学 与 艺术 作为 一种 关系 命题 暴露 出来 。 从 这样 一种 意义 上 说 , 提出 这样 一个 前瞻性 的 命题 , 是 非常 有 价值 的 。 从 展览 来说 , 我 感觉 有 三种 类型 的 作品 : 1 . 把 科学 思想 、 科学知识 加以 阐释 、 介绍 , 实际上 带有 一定 程度 的 科学 色彩 。 而 在 当下 , 它 又 具有 意识 形态 的 色彩 。 2 . 表现 现代科技 或用 现代科技 来 辅助 制作 的 作品 , 它 在 某种程度 上 显示 着 现代科技 的 力量 。 3 . 在 科学 的 条件 下 , 强调 对 人 的 生存 状 态 的 关注 , 强调 人 的 现实 体验 的 作品 。 实际上 , 从 艺术 与 科学 的 关系 的 角度看 , 这 一部分 作品 更 有 价值 。 如果 在 以后 还 将 继续 进行 展开讨论 , 我 认为 更应 关注 人 的 生存 状态 , 因为 在 让 人 生存 得 更 幸福 、 更好 的 目标 上 , 无论 科学 还是 艺术 , 它们 都 是 统一 的 。 邵大箴 ( 中央美术学院 教授 ) : 这次 展览 社会 反响 很大 , 收到 了 很 好 的 效果 。 虽然 也 有 不少 缺点 , 当 总的来说 还是 很 不错 的 。 科学 与 艺术 的 关系 问题 谈 不 清楚 , 已经 有 很多 的 讨论 , 李政道 先生 已经 是 第三次 提出 这个 问题 , 这次 是 最 重要 的 一次 , 并且 是 最大 的 一次 国际 研讨会 。 他 主要 强调 智慧 和 情感 , 艺术 也 是 , 科学 也 是 , 它们 本质 上 是 一样 的 , 讲得 很 对 。 而且 李政道 先生 讲 的 是 科学 、 自然科学 而 不是 讲 技术 。 科学 与 艺术 的 关系 发展 到 现在 , 包括 科学技术 与 艺术 的 关系 , 这个 问题 带有 一定 片面性 , 但 又 有 合理性 , 前面 有人 说 到 的 命题 的 公众 性 , 它 带有 普遍性 , 这是 一个 国际性 的 潮流 。 听说 浙江美术学院 曾经 请 哲学家 去 讲课 , 讲得 很 好 , 但是 有 的 艺术家 发问 : 你 懂 笔墨 吗 ? 这 很 可笑 , 哲学家 讲 的 是 普遍性 的 东西 , 艺术家 问 的 问题 有 一定 的 合理性 , 但 哲学家 谈 的 是 普遍性 的 东西 , 艺术家 谈 的 是 个别性 的 东西 。 这个 普遍性 的 东西 如果 我们 不去 研究 , 就 要 落后 。 个别性 的 东西 也 要 关注 , 例如 民族化 , 但是 要 在 普遍性 的 原则 下 。 科学 与 艺术 不管 以 何种 形式 发展 , 这个 命题 的 提出 都 带有 一定 前沿性 , 它 也 一定 会 推动 科学 与 艺术 的 发展 , 它们 的 结合 一定 会 产生 新 的 东西 。 西 \u3000 川 ( 中央美术学院 副教授 ) : 刚才 各位 的 发言 已经 把 我 想到 的 一些 问题 差不多 都 谈到 了 , 活动 成功 的 地方 我 就 不 重复 了 。 我 没 参加 清华 的 讨论会 , 因此 , 只 根据 展览 谈 我 当时 产生 的 几个 印象 。 一 , 这是 一个 美术学院 所 做 的 跟 科学 有 关系 的 展览 , 而 不是 科学院 做 的 跟 艺术 有 关系 的 展览 。 因此 , 艺术 很 显然 地 呈现 一种 向 科学 靠拢 的 姿态 。 通过 现代科技 手段 , 把 一些 存在 于 现代 艺术 之中 的 现代 观念 介绍 给 大家 。 另外 , 艺术 本 身 显得 不 自然 , 由于 艺术 与 科学 在 社会 发展 中 的 不 对称 比例 , 似乎 艺术 观念 落后 于 科学 的 观念 。 同时 , 通过 这样 一个 展览 , 使 艺术 本身 表现 出来 的 科学 似乎 已经 落后 当代 科学 所 达到 的 水准 。 因为 当代 科学 的 技术 层面 , 它 所 达到 的 形而上 的 层面 都 已 远远 超出 我们 的 想象 。 二 , 作品 不看 标示 牌 , 基本上 能 猜测出 是 哪 国人 所 做 , 尤其 是 中国 人 的 作品 更为 明显 。 为什么 会 如此 ? 这 里面 实际上 存在 一个 观念 置换 的 过程 , 中国 人 的 作品 不是 以 科学 精神 来 指导 , 而是 把 科学 与 艺术 的 空间概念 置换 成 古代 与 现代 的 时间 概念 。 三 , 科学 本身 在 其 现代 研究 中 已经 实现 了 科学 本身 的 转身 。 比 如 物理学 走到 核 物理学 , 最后 变成 对 社会 生活 的 破坏 , 这种 科学 转身 所 引起 的 当代 科学 对 伦理学 所 产生 的 挑战 , 事实上 在 这个 展览 中 很少 涉及 , 这个 展览 基本上 是 艺术 向 科学 靠拢 , 艺术 为 科学 唱赞歌 。 科学 本身 所 包含 的 那些 复杂 命题 、 转身 、 悖论 基本上 艺术家 没有 触及 到 。 四 , 在 科学 与 艺术 这样 一个 大题目 下 , 还 可以 分列 一些 小题目 进行 。 张晓凌 ( 中国艺术研究院 美术 研究所 研究员 ) : 我 最早 介入 “ 艺术 与 科学 ” 这个 主题 是 作为 撰稿人 为 这个 展览 搞 一个 专题片 , 一共 五集 , 我 写 第一集 , 介绍 艺术 与 科学 的 历史 关系 及 发展 脉落 , 并 由此 引发 一些 问题 。 艺术 与 科学 本身 一样 , 最早 的 艺术家 就是 科学家 , 直到 近代 科学 产生 以后 , 才 出现 一些 问题 , 艺术 与 科学 正式 分离 。 展览 有 不足 也 有 价值 的 地方 。 1 . 展品 可 减掉 三分之一 , 一些 作品 与 主题 没有 太大 的 关系 , 而且 质 量 平庸 。 另外 , 700 件 作品 使得 展厅 太 拥挤 , 展览 效果 不是太好 。 2 . 这次 展览 是 一个 开端 , 是 一个 仪式 。 但 进入 仪式 后 , 它 对 科学 、 科学 本身 的 一些 问题 , 对 当代人 的 生存 状态 反思 不够 , 艺术 与 科学 共同 作用 产生 力量 , 并 带来 震撼 的 作品 太 少 。 意义 : 尽管 有些 不足 , 但 其 成绩 、 价值 、 意 义 仍 远远 超过 不足 。 1 . 通过 这个 展览 , 它 表明 艺术 不是 点缀 、 美化 , 也 不是 装饰 , 它 是 一种 生存 方式 、 思维 方式 , 而 这种 方式 可以 通过 科学 的 方 式 展示 给 人们 。 2 . 这个 展览 完成 后 , 全国 美展 与 它 的 距离 至少 有 10 年 以上 的 差距 。 另外 , 它 对 美术馆 本身 也 是 一种 讽刺 , 装置 、 影像 艺术 等等 都 纳入 了 这次 展览 之中 。 3 . 这个 展览 另外 一个 更 重要 的 意义 在于 它 的 象征意义 。 而 在 中国 的 美术界 、 教育界 跨入 21 世纪 时 , 这样 一个 展览 至少 表现 出 一种 和 西方 各国 同步 的 文化 姿态 。 因为 这个 课题 也 是 同 时期 西方 关注 的 课题 , 在 国内 也 从未 提出 过 , 它 的 解决 程度 不管 如何 , 其 象征意义 必定 是 深远 的 。 出席 研讨会 的 还有 : 刘巨德 副 院长 、 包林 教授 、 陈瑞林 副教授 、 尚刚 副教授 等 。 ( 田君 、 海军 根据 录音 整理 , 未经 本人 审阅 。 标题 为 编者 所 加 )']
['【 文献号 】 1 - 1659 【 原文 出处 】 黄钟 【 原刊 地名 】 武汉 【 原刊 期号 】 199801 【 原刊 页 号 】 3 ~ 8 【 分 类 号 】 J6 【 分 类 名 】 音乐 、 舞蹈 研究 【 复印 期号 】 199804 【 标 题 】 20 世纪 的 中国 二胡 艺术 【 作 者 】 冯光钰 【 作者简介 】 冯光钰 , 男 , 1935 年生 ; 中国音乐家协会 教授 ( 北京 100026 ) 【 内容提要 】 本文 回顾 了 20 世纪 中国 现代 二胡 艺术 从 草创 到 逐渐 成熟 的 历程 。 着重 叙述 了 近百年来 中国 二胡 界 出现 的 华彦钧 、 刘天华 、 吕 文成 “ 二胡 三杰 ” 的 成就 。 并 从 演奏 人才 的 涌现 、 创作 大量 二胡曲 两个 方面 , 论述 50 年代 以来 二胡 艺术 的 全面 发展 。 还 就 力求 二胡 艺术 的 雅俗共赏 、 充 分 发挥 二胡 的 歌唱性 特点 、 体现 出 浓郁 的 民族风格 与 鲜明 的 时代精神 相结合 等 三个 问题 , 分析 了 二胡 艺术 审美 价值 的 创造 。 【 关 键 词 】 二胡 20 世纪 回顾 二胡 三杰 审美 价值 【 正 文 】 [ 分类号 ] J632.21 20 世纪 的 中国 音乐 , 走过 了 一条 既 曲折 艰辛 , 又 充满 了 希望 的 道路 。 现代 二胡 艺术 的 发展 , 也 经历 了 从 草创 到 逐渐 成熟 的 历程 。 近 百年 以 来 , 许多 二胡 艺术家 为了 二胡 演奏 、 创作 的 提高 和 繁荣 , 付出 了 很多 努力 , 做出 了 很大 贡献 。 一 在 谈到 二胡 艺术 审美 价值 时 , 不能不 提到 20 世纪 以来 中国 二胡 界 出现 的 三位 杰出人物 , 这 就是 华彦钧 、 刘天华 、 吕 文成 “ 二胡 三杰 ” 。 在 历代 统治者 的 眼里 , 二胡 是 一件 鄙俗 的 乐器 , 甚至 为 叫化子 乞讨 时所 操拉 , 不能 登 大雅之堂 。 正如 刘天华 在 《 月夜 及 除夜 小唱 说明 》 一文 中 所说 : “ 论及 胡琴 这 乐器 , 从前 国乐 盛行 时代 , 以其为 胡乐 , 都 鄙视 之 ; 今人 误以为 国乐 , 一般 贱视 国乐 者 , 亦 连累 及 之 , 故 自来 很少 有人 将 它 作为 一件 正式 乐器 讨论 过 , 这 真是 胡琴 的 不幸 ” ( 1928 年 2 月 《 音乐 杂志 》 ) 。 所以 , 在 一些 人 看来 , 二胡 只有 帮助 讨饭 的 功能 , 根本 谈不上 什么 审美 价值 。 但 20 世纪 “ 二胡 三杰 ” 的 出现 , 在 很大 程度 上 改变 了 二胡 “ 不幸 ” 的 命运 , 使 二胡 发生 了 历史性 的 变化 , 二胡 艺术 在 群众 的 音乐 生活 中 占有 了 不可或缺 的 地位 。 华彦钧 ( 阿炳 , 1893 — 1950 ) 是 一位 具有 多方面 才能 的 天才 民间 音乐家 。 他 在 二胡 上 的 造诣 使 这件 古老 的 乐器 焕发 了 新 的 艺术 生命力 。 他 的 成功 , 得益于 他 一直 浸泡 在 民间 音乐 的 海洋 里 。 他 从 宗教音乐 、 江南 丝竹 、 民歌 、 戏曲 滩簧 、 曲艺 评弹 、 说 因果 、 小 热昏 、 卖 梨膏 糖 的 叫卖 音乐 中 吸取 了 丰富 的 养料 。 早 在 华彦钧 还是 无锡 道观 雷尊殿 的 小 道童 时 , 便 能 演奏 竹笛 、 胡琴 、 琵琶 、 三弦 、 打击乐 等 乐器 , 受到 道士 们 的 赞赏 , 被 同行 褒誉 为 “ 小天 师 ” 。 在 二胡 演奏 和 创作 方面 , 他 的 功力 尤为 突出 。 原先 的 民间 二胡 , 多 是 在 原 把 位 上 演奏 , 而 阿炳 却 常 在 内外 弦 的 高 把 位 上 灵活运用 。 特别 是 充分发挥 了 内 弦 厚朴 深沉 的 音色 , 以及 空弦上 轻巧 的 弹拨 技巧 , 这 在 他 演奏 的 《 二泉映月 》 及 《 听松 》 、 《 寒 春风 曲 》 中 可以 领略到 。 他 的 作品 , 在 继承 民间 传统 技法 的 基础 上 进行 了 极大 的 突破 。 同时 , 阿炳 还是 一个 技艺 精湛 的 作曲家 。 不过 他 创作 的 许多 二胡 、 琵琶曲 不是 记录 在 乐谱 上 , 而是 凭 他 惊人 的 记忆力 保存 在 琴弦 上 。 从 一些 口碑 材料 可以 看出 , 他 的 艺术 生涯 可 分 两个 阶段 : 前期 ( 大约 1928 年 , 35 岁 双目失明 之前 ) 多 是 道教 音乐 、 江南 民间 乐曲 如 《 三 六 》 、 《 行街 》 、 《 四合 》 、 《 湘江 浪 》 等 , 还有 听 唱片 学来 的 《 小 桃红 》 、 《 昭君 怨 》 、 《 雨 打 芭蕉 》 、 《 三潭印月 》 等 ; 后期 ( 大约 是 35 岁 以后 ) 经常 演奏 的 是 许多 他 自己 经过 长期 积累 、 反复 琢磨 创作 而成 的 乐曲 。 但 当 人们 听到 这些 不曾 听过 的 曲子 问 他 是 什么 名字 时 , 他 总是 喃喃地 说 “ 是 我 瞎 拉 瞎 拉 的 ” , 或 “ 是 向 乡下人 家学来 的 ” 。 但 我们 从 1950 年 由 杨 荫 浏 、 曹安 和 先生 抢 录下来 的 三首 二胡曲 和 三首 琵琶曲 ( 《 大浪淘沙 》 、 《 龙船 》 、 《 昭君 出塞 》 ) 中 , 找不出 与 他 演奏 的 道教 音乐 和 民间 音乐 有 什么 雷同 之 处 , 足以 说明 这些 乐曲 确是 出自 阿炳之手 。 可惜 的 是 , 由于 阿炳 病体 急 剧 恶化 , 加之 抢录 工作 未 抓紧 进行 , 以致 他 的 许多 得意之作 失传 了 。 尽管如此 , 我们 从 阿炳 的 《 二泉映月 》 等 瑰宝 中 , 仍 可以 了解 到 他 不愧 是 一 位 出类拔萃 的 二胡 艺术 巨匠 。 他 对 二胡 艺术 的 发展 作出 了 卓越贡献 。 江阴 才子 刘天华 ( 1895 — 1932 ) , 也 是 发展 二胡 艺术 的 划时代 人物 。 在 中国 音乐史 上 , 他 是 把 民间 乐器 — — 二胡 引进 现代 高等 音乐 学府 教学 和 音乐会 演奏 的 第一 人 , 是 创立 专业 二胡 学派 的 奠基人 。 刘天华 对 二胡 艺术 的 提高 和 发展 , 是从 演奏 和 创作 两 方面 着手 的 。 刘天华 在 演奏 方面 , 首先 潜心 向 著名 江南 丝竹 名家 周少梅 ( 1884 — 1938 ) 学 习 二胡 , 并 经常 在 江阴 寺庙 中 与 和尚 们 一道 演奏 佛曲 , 从中 学习 佛教 音乐 的 二胡 演奏 。 1922 年 刘天华 应聘 到 北京大学 音乐 研究会 任教 后 , 为 提高 和 丰富 二胡 演奏 技法 , 向 俄籍 教授 托诺夫 学习 小提琴 长达 9 年 时间 , 有意识 地 从 西洋 音乐 中 吸取 有益 的 养料 。 这 期间 , 他 对 制作 二胡 琴筒 、 琴杆 、 琴轴 、 琴码 、 弓子 等 工艺 选料 及 定弦 、 揉 弦 、 换 把 等 演奏 技法 进行 了 革新 , 使 二胡 的 表现力 明显 地 得到 了 提高 。 与此同时 , 他 结合 二胡 演奏 技 法 的 改进 , 于 1915 年 蕴酿 创作 《 病中吟 》 开始 , 陆续 写作 了 47 首 二胡 练习曲 及 乐曲 《 月夜 》 、 《 空山鸟 语 》 、 《 苦闷 之 讴 》 、 《 悲歌 》 、 《 闲居 吟 》 、 《 良宵 》 、 《 光明行 》 、 《 独弦操 》 、 《 烛影摇红 》 。 从 这些 乐曲 中 可以 看出 , 刘天华 是 一位 富有 深厚 文化 传统 和 民间 音乐 基础 , 又 十分 善于 巧妙 地 借鉴 西洋 音乐 技巧 的 作曲家 。 他 的 创作 具有 独创性 , 其 旋律 流畅 生动 , 手法 简炼 朴实 , 音乐 结构 严谨 , 形象 鲜明 感人 。 通过 他 的 创作 和 演奏 革新 , 把 二胡 艺术 推向 了 一个 新 的 阶段 , 使 二胡 成为 专业化 的 独奏 乐器 。 吕 文成 ( 1898 — 1981 年 ) 是 一位 有 “ 二胡 博士 ” 美誉 的 音乐家 。 他 在 二胡 、 高胡 、 扬琴 演奏 及 广东音乐 创作 方面 均 有 很 深 的 造诣 , 尤 以 二胡 、 高胡 的 改革 及 演奏 的 贡献 最为 突出 。 他 创作 的 《 步步高 》 、 《 平湖 秋月 》 、 《 渔 歌唱 晚 》 等 名曲 早已 蜚声 海内外 , 然而 我们 以往 对 他 在 二胡 艺 术 上 的 成就 却 重视 得 不够 , 对 他 的 历史 地位 也 肯定 得 不够 。 吕 文成 的 二胡 艺术 成就 与 他 青少年 时代 在 上海 度过 是 分不开 的 。 他 从 1901 年 ( 3 岁 ) 至 1932 年 一直 随父 从 广东 中山 县 旅居 上海 。 他 自幼 喜爱 音乐 。 在 沪 的 30 年间 , 他 向 人 学习 二胡 演奏 , 熟练地 掌握 了 江南 丝竹 中 的 二胡 演奏 技巧 。 并于 1919 年 参加 上海 有名 的 中华 音乐会 。 20 年代 又 与 广 东 音乐家 尹 自重 、 何大 傻 等 人 组成 粤乐组 , 在 上海 、 北京 、 天津 等 地 演奏 广东音乐 , 还 与 小提琴家 司徒 梦岩 合作 同台 演出 。 这些 活动 , 使 吕 文成 积累 了 丰富 的 传统 民间 音乐 与 西洋 音乐 知识 。 在 此基础 上 , 他 对 二胡 进行 了 改革 , 突破 了 传统 二胡 的 局限性 。 首先 是 把 传统 二胡 的 琴杆 适当 缩短 , 将 二胡 外弦 的 丝线 改换 为 钢丝 弦 , 并 将 传统 二胡 的 定弦 提高 四度 , 与 小提琴 的 二弦 、 三弦 的 定弦 相同 ; 还 把 音域 扩展 到 二 、 三把位 , 自由 换 把 , 发展 了 滑 指 、 走 指 、 擞 音 等 技法 , 创制 新 的 乐器 高胡 。 最为 突出 的 是 , 他 将 琴筒 夹于 两腿间 拉奏 , 因为 两腿 可以 自如 地 控制 音量 、 音色 的 变化 , 使得 高胡 风格 华美 流丽 , 音色 明亮 清脆 。 吕 文成 1926 年 赴 广东 巡回演出 时 , 运用 他 改革 的 高胡 演奏 广东音乐 , 代替 了 原来 广东音乐 “ 五架 头 ” 中 二弦 的 地位 , 而 成为 主奏 乐器 , 使广 东 音乐 这 一乐种 得到 很大 的 发展 。 他 的 《 步步高 》 等 正是 为了 发挥 高胡 的 演奏 技能 而 创作 的 乐曲 。 30 年代 后 , 吕 文成 定居 香港 , 专事 粤乐 创作 和 演奏 。 经过 不断 的 艺术 实践 , 使 他 在 技艺 上 日趋 成熟 并 达到 了 炉火纯青 的 境地 。 在 此后 的 几十年 间 , 吕 文成 改革 创造 的 高胡 , 已 在 全国 各地 各种 编制 的 民族 乐队 中 广泛 运用 , 极大 地 丰富 了 乐队 的 表现力 。 这 是 吕 文成 对 发展 二胡 艺术 不可磨灭 的 贡献 , 从而 使 他 成为 与 华彦钧 、 刘天华 并 驾齐 驱 的 20 世纪 中国 “ 二胡 三杰 ” 之一 。 二 “ 二胡 三杰 ” 的 出现 , 乃是 20 世纪 中国 民族音乐 发展 的 必然 现象 。 20 世纪 是 中国 音乐 历史长河 中 十分 重要 的 阶段 。 持续 几千年 的 封建社会 在 本世纪初 崩溃 解体 , 引起 了 文化 的 转型 。 这 期间 音乐 产生 了 很大 的 变化 , 为 “ 二胡 三杰 ” 的 产生 提供 了 历史 机遇 。 这 三位 二胡 杰出人物 , 虽然 在 所处 的 文化 环境 、 成长 际遇 、 师承 关系 、 艺术 活动 等 方面 各不相同 , 但 也 有 许多 共同 的 因素 , 促使 他们 差不多 在 同一 时期 中 趋于 成熟 。 这些 共同点 是 : 第一 , “ 二胡 三杰 ” 都 先后 出 生于 19 世纪 90 年代 。 在 他们 悟事 之时 , 都 经历 了 20 世纪 初叶 的 两大 政治 事件 。 一是 1911 ( 辛亥 ) 年 10 月 10 日爆 发 的 震撼 世界 的 资产阶级 革命 。 辛亥革命 结束 了 中国 两千多年 的 封建 君主专制 制度 。 二是 1919 年 5 月 4 日 爆发 的 中国 人民 反对 帝国主义 和 封建主义 的 伟大 民主革命 运动 。 五四运动 成为 中国新民主主义革命 的 开端 。 华彦钧 、 刘天华 、 吕 文成 在 这 历史性 的 变革 中 , 都 不同 程度 地 接受 了 爱国主义 、 民族主义 、 民主自由 解放 的 思想 的 影响 。 这 对 他们 的 艺术 生涯 , 包括 演奏 和 创作 均 带来 了 直接 的 影响 。 特别 有意思 的 是 , 他们 的 生命 虽然 有长 有 短 , 但 纵观 他们 在 二胡 艺术 上 的 成熟 和 辉煌 时期 , 不约而同 的 都 是 本世纪 二三十 年代 。 刘天华 在 30 年代 初因 收集 民间 锣鼓 音乐 , 不幸 染上 猩红 热而 英年早逝 , 终年 只有 37 岁 。 华彦钧 和 吕 文成 虽然 分别 活 了 58 岁 和 83 岁 , 但 他俩 对 二胡 的 改革 成就 和 创作 上 的 精品 , 都 主要 产生 在 这 一时期 。 特别 是 “ 二胡 三杰 ” 创作 的 二胡 及 高胡 曲 , 都 是从 不同 角度 反映 这 一时期 人们 的 生活 和 思想感情 。 可以 说 , 经受 辛亥革命 和 五四运动 洗礼 的 华彦 钧 、 刘天华 和 吕 文成 , 在 艺术 上 的 创造 , 无不 受益 于 时代 的 给予 。 第二 , 中国 传统 音乐 经过 数千年 的 积累 和 发展 , 具有 巨大 的 艺术 能量 。 每 一个 时代 有 作为 的 音乐家 , 都 会 从 传统 音乐 中 吮吸 丰富 的 养料 。 华 彦 钧 、 刘天华 和 吕 文成 也 是 这样 。 他们 都 从 孩提 之时 起 直接 受到 传统 音乐 的 熏陶 。 特别 是 民间 音乐 、 宗教音乐 对 他们 的 成长 起到 了 十分 关键 的 作 用 。 华彦钧 自幼 就 生活 在 农村 和 道观 , 以 道教 乐手 和 民间 音乐 艺人 为师 , 学习 各种 传统 音乐 。 刘天华 在 江阴 和 常州 的 中学 教 音乐 时 , 便 抽出 大量 时间 向 各地 的 民间 音乐家 学习 二胡 、 琵琶 、 古琴 、 三弦 拉戏 及 昆曲 等 , 还 经常 到 江阴 涌塔庵 学习 佛教 音乐 。 1930 年 他 为 京剧 名家 梅兰芳 记录 唱腔 , 编成 《 梅兰芳 歌曲 谱 》 一册 。 他 的 不幸 早逝 , 也 是 因 赴 北京 天桥 收集 锣鼓 谱 , 罹病 不治 所致 。 吕 文成 也 是 浸泡 在 江南 丝竹 、 广东音乐 和 粤曲 演 奏 演唱 中 成长 起来 的 。 他 不仅 二胡 、 高胡 、 扬琴 的 技艺 娴熟 , 而且 还 擅长 演唱 粤曲 “ 子喉 ” 。 他 演唱 的 《 潇湘 琴怨 》 、 《 燕子 楼 》 、 《 离天 恨 》 等 曲目 , 情意 缠绵 、 悠扬 抒情 。 这 对 他 创作 的 由 高胡 领奏 的 许多 广东音乐 乐曲 有着 直接 的 影响 。 特别 是 一些 富于 歌唱性 的 广东音乐 乐曲 , 可以 听 出 , 有 不少 是 吸取 的 粤曲 唱腔 旋律 , 有 的 甚至 就是 模拟 唱腔 发展 而成 。 第三 , 20 世纪 初始 西洋 音乐 大量 传入 中国 。 中西 音乐 的 融合 , 是 促使 中国 音乐 在 20 世纪 转型 的 因素 之一 。 “ 二胡 三杰 ” 的 演奏 和 创作 , 都 不 同 程度 直接 或 间接 受到 西洋 音乐 的 影响 。 刘天华 16 岁 时 在 江阴 的 中学 参加 军乐队 , 吹奏 小号 , 开始 接触 西洋 音乐 。 如前所述 , 他 在 北京 的 10 年间 ( 1922 — 1932 ) 从未 间断 学习 小提琴 。 同时 , 他 还 很 重视 西洋 音乐 理论 的 学习 和 研究 , 努力 从中 借鉴 外国 乐曲 的 音乐 结构 及 表现 方法 。 在 他 创作 的 二胡 练习曲 及 乐曲 中 , 明显 地 吸收 了 西洋 音乐 的 经验 。 吕 文成 将 二胡 改革 为 高胡 , 从 将 外 弦 改为 钢丝 弦 到 把 定弦 提高 四度 , 无一不是 受到 小提琴 的 启示 。 从 他 创作 的 《 步步高 》 等 乐曲 中 , 也 可 看出 其 曲式 结构 及 旋律 发展 手法 , 均 有 借鉴 西洋 音乐 的 因素 。 华彦钧 虽未 直接 学习 过 西洋 音乐 , 但 从 他 对 新 事物 的 敏感 和 接受 能力 来看 , 从 接触 当时 的 唱片 及 广播电台 播放 的 音乐 中 , 也许 会 间接 地 受到 一些 外国 音乐 及 新 音乐 的 影响 , 并 有机 地 吸收 到 他 的 创作 及 演奏 中 去 。 “ 二胡 三杰 ” 的 这些 共同 特点 的 形成 , 归根到底 乃 时代 所 使然 。 他们 在 风起云涌 的 时代 浪潮 中 , 从 关心 国家 、 民族 的 命运 出发 , 对 中国 民族 音乐 事业 克尽 所能 , 发挥 了 自己 的 聪明才智 , 使 二胡 艺术 在 20 世纪 获得 了 空前 的 发展 。 三 华彦钧 、 刘天华 、 吕 文成 “ 二胡 三杰 ” 对 20 世纪 中国 二胡 艺术 的 贡献 , 不仅 给 我们 留下 了 珍贵 的 二胡 艺术 遗产 , 还 在 他们 直接 培育 或 积极 影 响下 , 造就 了 一批 从事 二胡 艺术 的 人才 。 成长 于 三四十 年代 的 二胡 家 , 成 了 这 一时期 传播 和 发展 二胡 艺术 的 中坚力量 。 二三十 年代 有 陈振铎 、 储 师竹 、 蒋风 之 、 刘北茂 、 陆修堂 、 刘 天一 、 朱海 等 人 ; 40 年代 有王 乙 、 丁 d ā n g @ ① 、 黎松寿 、 俞鹏 、 张锐 、 朱郁 之 、 闵季 骞 、 段启诚 、 刘明 沅 、 张韶 、 陈朝儒 等 人 。 他们 直接 或 间接 地 承袭 了 “ 二胡 三杰 ” 的 优良传统 , 不仅 在 二胡 演奏 和 创作 方面 取得 了 很大 的 成绩 , 还 在 二胡 教学 上 做 了 许多 有益 的 探索 , 培养 了 一些 后起之秀 。 特别 引人注目 的 是 , 50 年代 以来 的 近 半个世纪 , 中国 二胡 艺术 水平 得到 了 飞速 的 提高 , 可以 说 , 这是 二胡 艺术 发生 整体性 变革 与 全面 发展 的 黄金 季节 。 主要 表现 在 两个 方面 : 一是 演奏 人才 的 涌现 。 各 高等 音乐 院校 的 本科 和 附中 , 及 一些 师范院校 音乐系 , 乃至 省 、 地级 艺术 学校 , 都 开设 了 二胡 演奏 课程 。 从 练习曲 到 乐曲 的 教学 的 逐步 规 范化 , 为 学习者 打下 扎实 的 基本功 创造 了 条件 。 经过 严格 的 专业训练 , 五六十年代 涌现 了 一批 富有 才华 的 二胡 家 , 如 唐毓斌 、 牛 巨贵 、 黄海 怀 、 项祖英 、 汪炳炎 、 王宜勤 、 鲁日融 、 甘尚时 、 黄日进 、 孙 文明 、 甘柏霖 、 王国 潼 、 蒋巽风 、 陈 耀星 、 肖白庸 、 舒昭 、 周耀锟 、 闵惠芬 、 蒋才 如 等 人 。 在 很长 一段时间 里 , 他们 是 二胡 界 的 中流砥柱 式 的 人物 , 对 推动 二胡 艺术 的 进一步 发展 , 起到 了 积极 的 作用 。 80 年代 以来 , 二胡 乐坛 上 又 出 现了 一批 熠熠生辉 的 新星 , 如余 其伟 、 陈 国产 、 姜 建华 、 朱昌耀 、 周维 、 欧 景星 、 宋飞 、 李小萍 等 人 , 这 标志 着 二胡 艺术 后继有人 , 且 青出于蓝 而胜于蓝 。 二是 创作 了 大量 的 二胡曲 。 这 一时期 的 二胡曲 , 有 的 出自 二胡 演奏家 之手 , 有 的 则 是 专业 作曲家 的 创作 。 前者 如 《 田野 小曲 》 ( 王乙曲 ) 、 《 大凉山 狂想曲 》 ( 段启诚 曲 ) 、 《 苍山 抒怀 》 ( 舒昭曲 ) 、 《 梆子 风 》 ( 项祖英 编曲 ) 、 《 鱼游 春水 》 ( 刘天 一曲 ) 、 《 江河水 》 ( 黄海 怀 移植 改编 ) 、 《 赛马 》 ( 黄海 怀曲 ) 、 《 秦腔 主题 随想曲 》 ( 鲁日融 、 赵震霄曲 ) 、 《 洪湖 人民 的 心愿 》 ( 闵惠芬 编曲 ) 、 《 流波曲 》 ( 孙 文明 曲 ) 、 《 弹乐 》 ( 孙 文明 曲 ) 、 《 草原 新 牧民 》 ( 刘长 福曲 ) 、 《 战马 奔腾 》 ( 陈 耀星 曲 ) 、 《 江南 春色 》 ( 朱昌耀曲 ) 等等 ; 后者 如 《 豫北 叙事曲 》 ( 刘文金 曲 ) 、 《 三门 峡 畅想曲 》 ( 刘文金 曲 ) 、 二胡 协奏曲 《 长城 随想 》 ( 刘文金 曲 ) 、 《 一枝花 》 ( 张式业 编曲 ) 、 《 子弟兵 和 老百姓 》 ( 晨耕 、 唐诃 编曲 ) 、 《 拉 骆驼 》 ( 曾 寻曲 ) 、 《 山村 变了样 》 ( 曾 加庆曲 ) 、 《 赶集 》 ( 瞿春泉曲 ) 、 《 湘江 乐 》 ( 时乐 m é n g @ ② y í n g @ ③ 曲 ) 、 《 春诗 》 ( 钟义 良曲 ) 、 《 金珠玛米 赞 》 ( 王 竹林 曲 ) 、 《 春到 田间 》 ( 林韵曲 ) 、 《 春郊 试马 》 ( 陈德钜曲 ) 、 高胡 、 古筝 三重奏 《 春天 来 了 》 ( 雷雨 声 曲 ) 等等 。 新 的 二胡曲 的 创作 , 一方面 增添 和 积累 了 二胡 的 演奏 曲目 , 另一方面 也 推动 了 二胡 演奏 技法 的 不断改进 和 丰富 。 在 继承 “ 二胡 三态 ” 的 基础 上 , 现代 二胡 演奏 又 获得 了 较大 的 提高 和 发展 , 这 与 二胡曲 新作 的 不断 出现 是 分不开 的 。 四 近 一个 世纪 以来 , “ 二胡 三杰 ” 及 他们 的 后继者 在 发展 二胡 艺术 的 道路 上 , 历尽艰辛 所 取得 的 成就 , 从根本上 来说 是 一种 审美活动 。 而 二胡 艺术 的 这种 审美 价值 的 创造 , 无论是 演奏 , 还是 创作 , 都 是 特殊 的 生产性 审美活动 。 从 审美 价值 的 角度 来 审视 现代 二胡 艺术 , 可以 归纳 为 如下 几 个 特点 : 1 . 力求 二胡 艺术 的 雅俗共赏 传统 的 二胡 , 是 一件 在 民间 广为流传 的 乐器 。 由于 制作 简便 , 价格低廉 , 很 容易 为 一般 平民百姓 所 掌握 。 自 20 世纪 “ 二胡 三杰 ” 出现 后 , 使 二胡 艺术 发展 到 较 高 的 品位 , 从此 使 一个 民间 的 俗 乐器 登上 了 大雅之堂 。 “ 二胡 三杰 ” 以来 的 近百 年间 , 二胡 艺术 之所以 深受 广大群众 的 喜爱 , 主要 在于 它 既 保持 了 传统 的 “ 俗 ” 音乐 的 面貌 , 又 有 “ 雅 ” 音乐 的 审 美 追求 , 使雅 、 俗 音乐 在 二胡 艺术 中 走向 合流 , 两者 相互 借鉴 、 交叉 渗透 、 取长补短 , 达到 了 一定 程度 的 融合 。 这样 的 例子 很多 。 如 《 二泉映月 》 是 出自 民间 音乐家 阿炳之手 , 其 成功 之 处 , 便是 它 具有 雅俗共赏 的 艺术 魅力 。 这首 既 通俗 又 深刻 反映 广大 低层 大众 的 思想感情 的 乐曲 , 在 阿炳 经年累月 演奏 于 大街小巷 时 , 深受 寻常 老百姓 的 欢迎 。 这首 乐曲 经 录音 记录 出版 后 , 得到 更加 广泛 的 传播 。 通过 在 音乐会 上 演奏 和 广播电视 的 播放 , 在 高层次 文化圈 内 也 引起 了 强烈 共鸣 , 人们 无不 为 阿炳 的 音乐 所 倾倒 , 甚至 使 日本 著名 指挥家 小泽征尔 感动 得 不禁 潸然泪下 , 他 说 : “ 这种 音乐 只 应该 跪 着 听 。 ” 可见 《 二泉映月 》 的 艺术 感染力 强烈 。 刘天华 、 吕 文成 以及 黄海 怀等 人 的 音乐 得以 久远 的 流传 , 也 证明 二胡 艺术 发展 中 的 雅俗 彼此 相渗 、 交相 为用 , 达到 了 雅俗 相通 的 艺术境界 。 本世纪 涌现 的 许多 优秀 的 二胡 作品 , 都 有着 一个 共同 的 特点 , 这是 力求 做到 雅俗共赏 。 2 . 充分发挥 二胡 的 歌唱性 特点 二胡 千百年来 能 长久 流行 在 民间 , 本世纪 以来 又 不断 登上 大雅之堂 , 一个 重要 原因 是 它 具有 歌唱性 的 特点 。 这 就 使得 二胡 艺术 的 价值 表现 为 : 以 作品 的 丰富 内容 及 富于 歌唱性 的 艺术 感染力 赢得 人们 的 喜爱 。 “ 二胡 三杰 ” 的 作品 及 演奏 之所以 经久不衰 , 百听不厌 , 一是 乐曲 的 旋律 性 很 强 , 音乐 主题 优美 动听 , 听众 可以 “ 过耳 成诵 ” ; 二是 在 演奏 技法 上 充分发挥 了 两根 琴弦 的 歌唱性 特点 , 奏 出 人们 的 心声 , 引起共鸣 。 黄海 怀及 许多 二胡曲 作家 的 作品 都 充分体现 了 这种 特点 。 黄海 怀 移植 改编 的 《 江河水 》 , 在 同名 民间 双管 曲 的 基础 上 , 着力 发挥 二胡 的 特性 , 无论是 指法 的 揉 颤 吟咏 , 还是 各种 弓法 的 强弱 力度 对比 , 都 把 乐曲 的 音乐 形象 表现 得 淋漓尽致 , 音乐 好像 是 一位 古代 妇女 不幸 人生 的 悲泣 、 倾诉 , 震撼 着 人 们 的 心灵 。 他 的 《 赛马 》 ( 原作 ) 在 表现 内蒙古草原 骏马奔驰 的 热烈 场面 时 , 一方面 在 前后 乐段 运用 了 复杂多变 的 快 弓 、 跳弓 及顿 弓 , 同时 在 中 段 十分 注重 在 琴弦 上奏出 悠扬 舒畅 的 蒙古族 民歌 旋律 , 既 增强 了 音乐 的 紧松 快慢 对比 , 又 刻画 了 草原 牧民 的 豪迈 性格 。 另一方面 , 我们 也 看到 , 有些 二胡曲 的 创作 和 演奏 , 不同 程度 地 存在 着 脱离 内容 的 单纯 技巧 表现 , 乃至 炫耀 的 倾向 。 其 原因 在于 没有 扬 二胡 艺术 之 所长 , 反而 弄巧成拙 。 3 . 体现 出 浓郁 的 民族风格 与 鲜明 的 时代精神 相结合 “ 二胡 三杰 ” 和 他们 的 后继者 的 许多 成功 之作 , 在 这方面 做出 了 可贵 的 艺术 实践 。 他们 在 作品 中 , 采用 群众 喜闻 乐听 的 音乐 语言 表现 各个 时 代 的 现实生活 , 说明 他们 在 取之不尽 的 生活源泉 中 , 选取 最 富于 时代 意义 的 题材 , 并 认真 从 丰富多彩 的 民族民间 音乐 中 吸取 营养 , 将 其 发展 变化 成 特有 的 二胡 音乐 语言 。 这样 的 例子 不胜枚举 。 从 以上 可见 , 二胡 艺术 和 其他 姊妹 艺术 一样 , 其 价值 只有 当 它 被 人们 欣赏 、 评论 , 真正 得到 检验 和 承认 , 其 潜在 的 价值 才能 转化 成为 现实 的 价值 , 从而 形成 一种 社会 效应 。 20 世纪 的 中国 二胡 艺术 的 迅速 发展 , 正是 由于 “ 二胡 三杰 ” 和 等 众多 的 二胡 艺术家 , 以 其 孜孜不倦 的 精神 , 不断创新 的 结果 。 当然 , 二胡 在 未来 的 岁月 中要 实现 艺术 上 的 更加 完善 , 还 需要 不断 地 超越 。 二胡 艺术 的 审美 价值 , 就 会 在 这种 超越 、 升华 和 融汇 中 获得 充分 的 实现 。 【 责任编辑 】 蔡际洲 字库 未存 字 注释 : @ ① 原字 王右 加当 @ ② 原字 氵 右 加蒙 @ ③ 原字 氵 右 加莹']]
[[16]
[16]]
![复制代码]()
然后是构建测试集:
test_data = []
test_label = []
with open("/content/drive/My Drive/NLP/dataset/Fudan/test_jieba.txt","r",encoding="utf-8") as fp:
lines = fp.readlines()
for line in lines:
line = line.strip().split("\t")
if len(line) == 2:
test_data.append([line[0]])
test_label.append([label_to_idx_dict[line[1]]])
test_data = np.array(test_data)
test_label = np.array(test_label)
print(test_data.shape)
print(test_label.shape)
print(test_data[:2])
print(test_label[:2])按照惯例,我们还需要将训练集打乱:要同时将数据和标签进行打乱
shuffle_ix = np.random.permutation(np.arange(len(train_data)))
train_row = list(range(len(train_data)))
random.shuffle(train_row)
print(train_row)
train_data = train_data[train_row,:]
train_label = train_label[train_row,:]
print(train_data[:2])
print(train_label[:2])
3、搭建模型
接下来就可以搭建模型了,这里需要将二维数组转换一维数组,同时要将numpy数组转换为列表:
from sklearn.feature_extraction.text import TfidfVectorizer
train_data = train_data.reshape(len(train_data)).tolist()
print(train_data[:2])
tfidf_model = TfidfVectorizer()
sparse_result = tfidf_model.fit_transform(train_data) # 得到tf-idf矩阵,稀疏矩阵表示法
打印一下看看:
for k,v in tfidf_model.vocabulary_.items():
print(k,v)
心理负荷 215604
打破常规 224020
环境压力 283954
起新 341654
救弱 234689
抑强 225392
亚稳态 114323
醒觉 353619
能态 317052
特异功能 280313
。。。。。。
同样的,我们也需要对测试集进行相同的转换:
test_data = test_data.reshape(len(test_data)).tolist()
print(test_data[:2])
test_sparse_result = tfidf_model.transform(test_data)
最后是使用朴素贝叶斯进行分类:
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
mnb_count = MultinomialNB()
mnb_count.fit(sparse_result, train_label) # 学习
mnb_count_y_predict = mnb_count.predict(test_sparse_result) # 预测
classification_report(mnb_count_y_predict, test_label)
结果:
precision recall f1-score support
0 1.00 0.44 0.61 3662
1 0.00 0.00 0.00 0
2 0.81 0.90 0.85 1104
3 0.00 0.00 0.00 0
4 0.44 0.97 0.60 461
5 0.96 0.81 0.88 1608
6 0.00 0.00 0.00 0
7 0.62 0.85 0.72 752
8 0.00 0.00 0.00 0
9 0.36 0.99 0.53 236
10 0.00 0.00 0.00 0
11 0.00 0.00 0.00 0
12 0.00 0.00 0.00 0
13 0.00 0.00 0.00 0
14 0.00 0.00 0.00 0
15 0.87 0.90 0.88 1214
16 0.00 0.00 0.00 0
17 0.00 0.00 0.00 0
18 0.86 0.81 0.83 795
19 0.00 0.00 0.00 0
accuracy 0.71 9832
macro avg 0.30 0.33 0.30 9832
weighted avg 0.87 0.71 0.74 9832至此,将整个流程打通了。如果想提高分类的性能,则需要进一步的数据预处理以及模型的调参了。
4、进一步调优
为了避免每次再运行时标签映射发生变化,我们将标签映射存入到txt中:
label = []
with open("/content/drive/My Drive/NLP/dataset/Fudan/train_jieba.txt","r",encoding="utf-8") as fp:
lines = fp.readlines()
for line in lines:
line = line.strip().split("\t")
if len(line) == 2:
label.append(line[1])
label = set(label)
label_to_idx = list(zip(label,range(len(label))))
with open("/content/drive/My Drive/NLP/dataset/Fudan/label.txt","w",encoding="utf-8") as fp:
for k,v in label_to_idx:
fp.write(k+"\t"+str(v)+"\n")接下里我们要仔细研究一下sklearn自带的TfidfVectorizer()了。
(1)fit()、fit_transform()以及transform()
这里要额外提到fit()、fit_transform()以及transform():简单的说下自己的理解,具体的还是百度吧
fit():输入要拟合的数据
transform():对拟合的数据进行转换
fit_transform():拟合和转换的结合
一般是这么使用的:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit_tranform(X_train)
sc.tranform(X_test)
一般是对训练集进行拟合和转换,然后对测试集进行转换即可,如果我们再使用sc.fit_transform(X_test)就会报错。具体对于不同的函数,稍微有所区别,这里就不展开了。
(2)参数:token_pattern
接下来看以下代码:
from sklearn.feature_extraction.text import TfidfVectorizer
document = ['我 是 一条 天狗 呀 !', '我 把 月 来 吞 了 ,', '我 把 日来 吞 了 ,', '我 把 一切 的 星球 来 吞 了 ,', '我 把 全宇宙 来 吞 了 。', '我 便是 我 了 !'
]
tfidf = TfidfVectorizer()
tfidf_model = tfidf.fit(document)
tfidf_model.vocabulary_输出:{'一切': 0, '一条': 1, '便是': 2, '全宇宙': 3, '天狗': 4, '日来': 5, '星球': 6}
也就是之前我们没有进行任何处理,直接使用TfidfVectorizer(),那么单词长度为1的就自动被过滤掉了,控制这个的参数是:token_pattern,其默认匹配长度>=2的单词。
其默认参数为r"(?u)\b\w\w+\b",其中的两个\w决定了其匹配长度至少为2的单词。
我们改为以下即可匹配出一个词的:
tfidf = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b")
输出:{'一切': 0, '一条': 1, '了': 2, '便是': 3, '全宇宙': 4, '吞': 5, '呀': 6, '天狗': 7, '我': 8, '把': 9, '日来': 10, '星球': 11, '是': 12, '月': 13, '来': 14, '的': 15}
看一下转换之后的结果:
tfidf_model.transform(document).todense()
matrix([[0. , 0.48812169, 0. , 0. , 0. ,
0. , 0.48812169, 0.48812169, 0.2166769 , 0. ,
0. , 0. , 0.48812169, 0. , 0. ,
0. ],
[0. , 0. , 0.31515212, 0. , 0. ,
0.36493681, 0. , 0. , 0.27305977, 0.36493681,
0. , 0. , 0. , 0.61513894, 0.42586833,
0. ],
[0. , 0. , 0.34831708, 0. , 0. ,
0.40334084, 0. , 0. , 0.30179515, 0.40334084,
0.67987295, 0. , 0. , 0. , 0. ,
0. ],
[0.4641016 , 0. , 0.23777166, 0. , 0. ,
0.27533252, 0. , 0. , 0.2060144 , 0.27533252,
0. , 0.4641016 , 0. , 0. , 0.32130331,
0.4641016 ],
[0. , 0. , 0.31515212, 0. , 0.61513894,
0.36493681, 0. , 0. , 0.27305977, 0.36493681,
0. , 0. , 0. , 0. , 0.42586833,
0. ],
[0. , 0. , 0.35776647, 0.69831701, 0. ,
0. , 0. , 0. , 0.61996492, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. ]])说明:我们有6个句子,共有16个词组,因此形状是(6,16)。
(3)参数:min_df/max_df
我们可以通过min_df/max_df参数:默认是0-1的浮点数或者是一个整数,如果是浮点数,则是将低于某比例或者高于某比例的词移除,如果是整数,则是将低于一定频数或者高于一定频数的词进行移除。我们接下来试试:
tfidf = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b",min_df=0.1,max_df=0.5)
输出:{'一切': 0, '一条': 1, '便是': 2, '全宇宙': 3, '呀': 4, '天狗': 5, '日来': 6, '星球': 7, '是': 8, '月': 9, '来': 10, '的': 11}
过滤掉了一些词。
(4)参数:ngram_range
tfidf = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b",ngram_range=(1,2))
输出:{'一切': 0, '一切 的': 1, '一条': 2, '一条 天狗': 3, '了': 4, '便是': 5, '便是 我': 6, '全宇宙': 7, '全宇宙 来': 8, '吞': 9, '吞 了': 10, '呀': 11, '天狗': 12, '天狗 呀': 13, '我': 14, '我 了': 15, '我 便是': 16, '我 把': 17, '我 是': 18, '把': 19, '把 一切': 20, '把 全宇宙': 21, '把 日来': 22, '把 月': 23, '日来': 24, '日来 吞': 25, '星球': 26, '星球 来': 27, '是': 28, '是 一条': 29, '月': 30, '月 来': 31, '来': 32, '来 吞': 33, '的': 34, '的 星球': 35}
该参数的意思是1个到2个词组之间的组合。
(5)参数:stop_words=[]
tfidf = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b",ngram_range=(1,2),stop_words=['我','来','把','的'])
输出:{'一切': 0, '一切 星球': 1, '一条': 2, '一条 天狗': 3, '了': 4, '便是': 5, '便是 了': 6, '全宇宙': 7, '全宇宙 吞': 8, '吞': 9, '吞 了': 10, '呀': 11, '天狗': 12, '天狗 呀': 13, '日来': 14, '日来 吞': 15, '星球': 16, '星球 吞': 17, '是': 18, '是 一条': 19, '月': 20, '月 吞': 21}
该参数的意思是过滤掉一些词语,传入一个列表。
(6)参数:max_features:int
tfidf = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b",ngram_range=(1,2),stop_words=['我','来','把','的'],max_features=10)
输出:{'了': 0, '吞': 1, '吞 了': 2, '天狗 呀': 3, '日来': 4, '日来 吞': 5, '星球': 6, '星球 吞': 7, '是': 8, '是 一条': 9}
该参数的意思是使用前多少个词语,传入一个整型。
5、优化结果
我们重新运行一下程序,使用我们之前存储大label.txt中的映射关系,同时使用默认的TfidfVectorizer()。
,结果如下:
precision recall f1-score support
0 0.00 0.00 0.00 0
1 0.44 0.97 0.60 461
10 0.00 0.00 0.00 0
11 0.00 0.00 0.00 0
12 0.81 0.90 0.85 1104
13 0.36 0.99 0.53 236
14 0.00 0.00 0.00 0
15 0.00 0.00 0.00 0
16 1.00 0.44 0.61 3662
17 0.00 0.00 0.00 0
18 0.00 0.00 0.00 0
19 0.00 0.00 0.00 0
2 0.00 0.00 0.00 0
3 0.87 0.90 0.88 1214
4 0.00 0.00 0.00 0
5 0.62 0.85 0.72 752
6 0.96 0.81 0.88 1608
7 0.00 0.00 0.00 0
8 0.00 0.00 0.00 0
9 0.86 0.81 0.83 795
accuracy 0.71 9832
macro avg 0.30 0.33 0.30 9832
weighted avg 0.87 0.71 0.74 9832接下来我们先读取停止词列表:
stopwords = []
with open("/content/drive/My Drive/NLP/dataset/Fudan/stopwords.txt","r",encoding="utf-8") as fp:
lines = fp.readlines()
for line in lines:
line = line.strip()
stopwords.append(line)
print(stopwords)部分结果:['$', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '?', '【', '】', '_', '“', '”', '、', '。', '《', '》', '一', '一些', '一何', '一切', '一则', '一方面', '一旦']
然后我们构建带参数的TfidfVectorizer():代码如下:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_model2 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b",ngram_range=(1,2),stop_words=stopwords,max_features=40000)
sparse_result2 = tfidf_model2.fit_transform(train_data) # 得到tf-idf矩阵,稀疏矩阵表示法
test_sparse_result2 = tfidf_model2.transform(test_data)
mnb_count2 = MultinomialNB()
mnb_count2.fit(sparse_result2, train_label) # 学习
mnb_count_y_predict2 = mnb_count2.predict(test_sparse_result2) # 预测
classification_report(mnb_count_y_predict2, test_label)
结果:
precision recall f1-score support
0 0.00 0.00 0.00 0
1 0.82 0.88 0.85 958
10 0.00 0.00 0.00 0
11 0.00 0.00 0.00 0
12 0.89 0.91 0.90 1190
13 0.59 0.98 0.73 384
14 0.00 0.00 0.00 0
15 0.00 0.00 0.00 0
16 0.95 0.76 0.84 2019
17 0.00 0.00 0.00 0
18 0.00 0.00 0.00 0
19 0.21 0.96 0.35 103
2 0.00 0.00 0.00 0
3 0.94 0.76 0.84 1545
4 0.00 0.00 0.00 0
5 0.89 0.77 0.83 1184
6 0.97 0.85 0.91 1548
7 0.00 0.00 0.00 0
8 0.00 0.00 0.00 0
9 0.92 0.75 0.83 901
accuracy 0.82 9832
macro avg 0.36 0.38 0.35 9832
weighted avg 0.90 0.82 0.85 9832确实是有很大的提升,至此,本文就结束了,接下来准备捣鼓捣鼓词嵌入以及深度学习的一些网络啦。
参考:
https://blog.csdn.net/blmoistawinde/article/details/80816179
https://blog.csdn.net/yuyanyanyanyanyu/article/details/84026485











































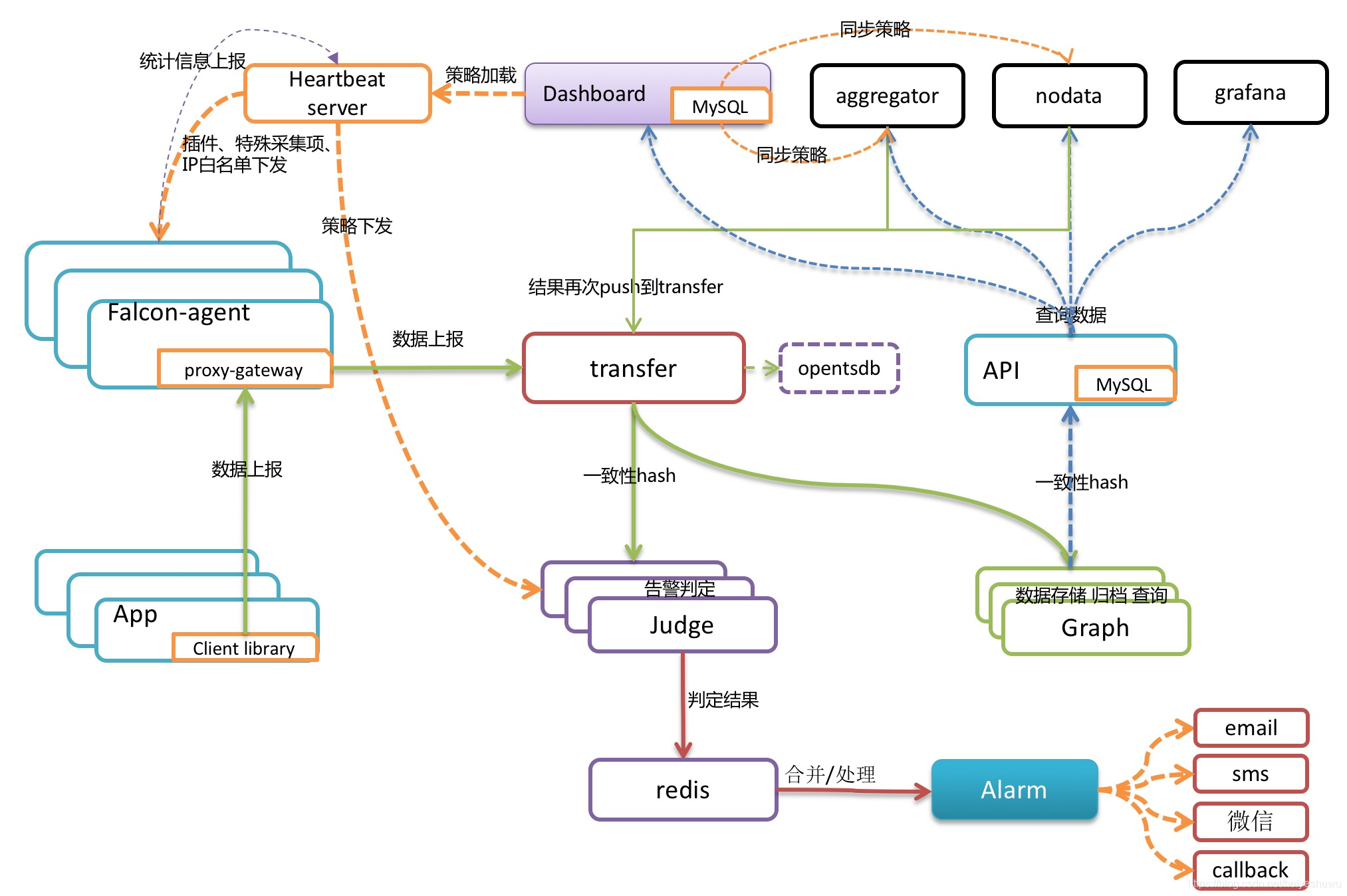
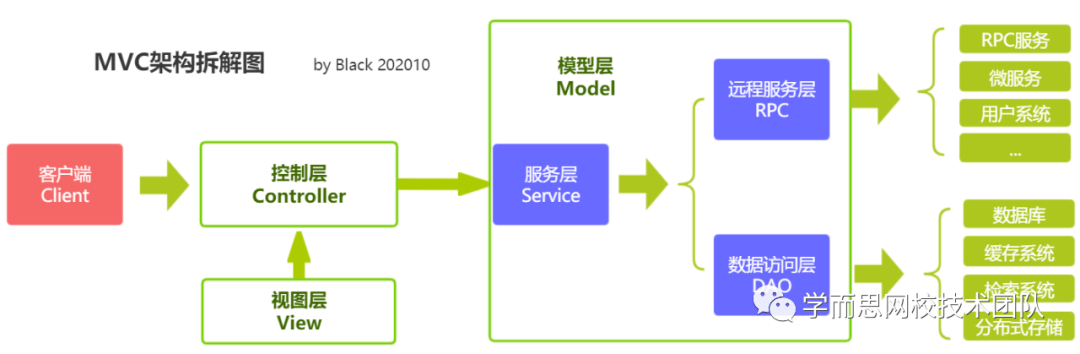
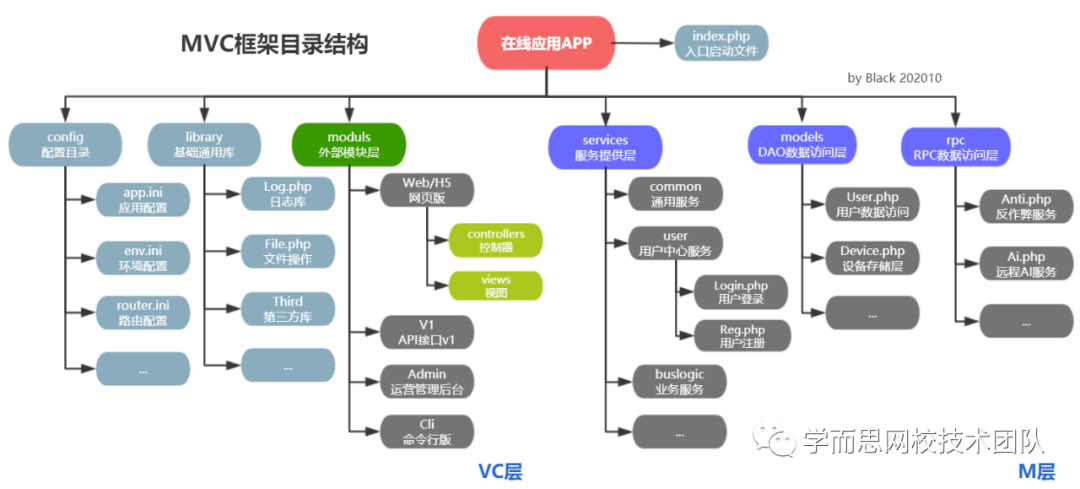
 微软:微服务设计模式
微软:微服务设计模式 在不同的子系统之间放置防损层以将其隔离
在不同的子系统之间放置防损层以将其隔离