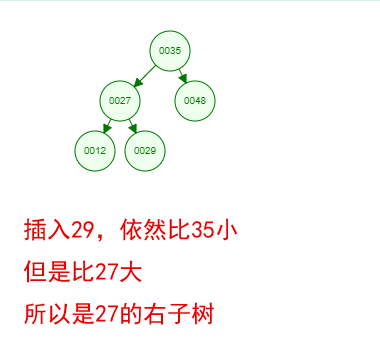
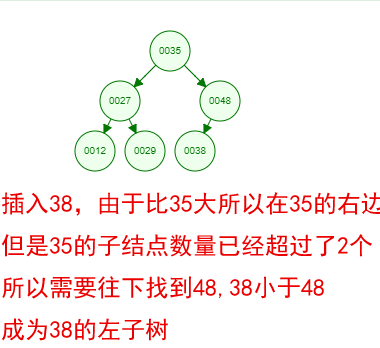
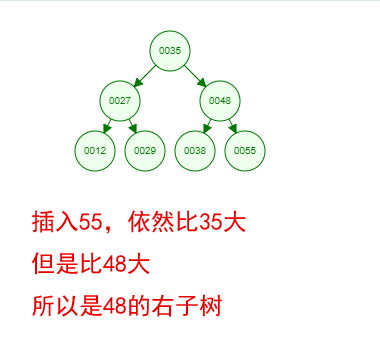
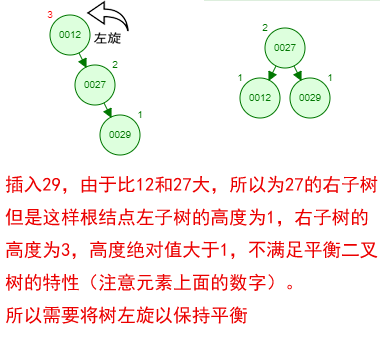
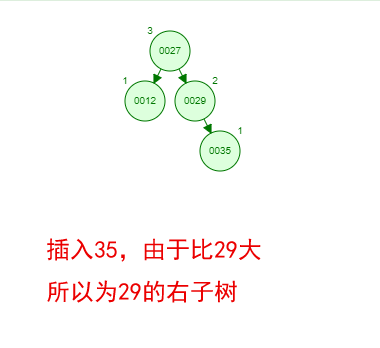
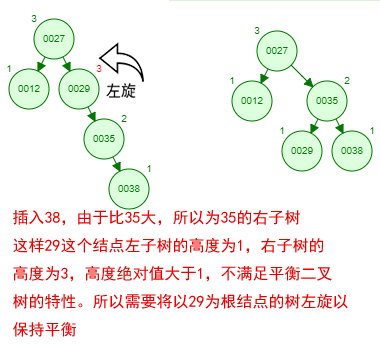
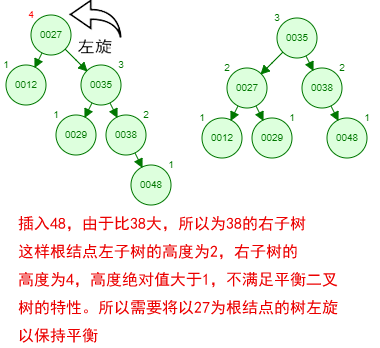
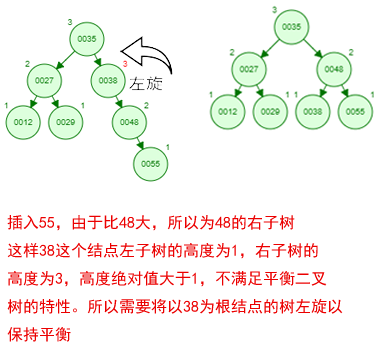
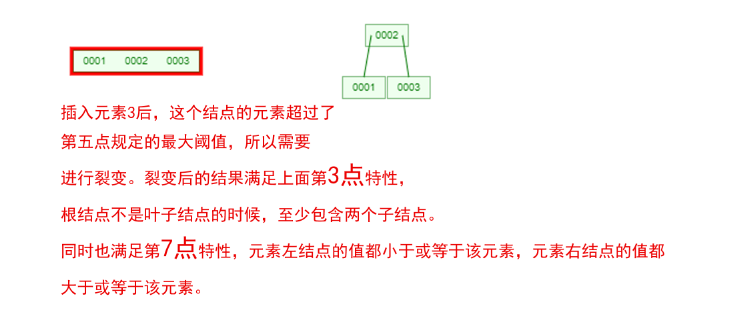
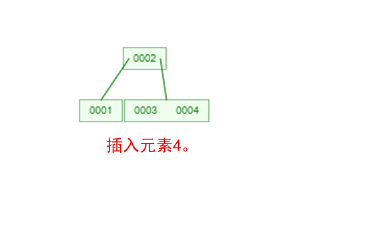
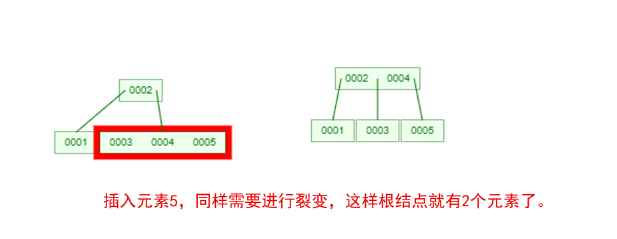
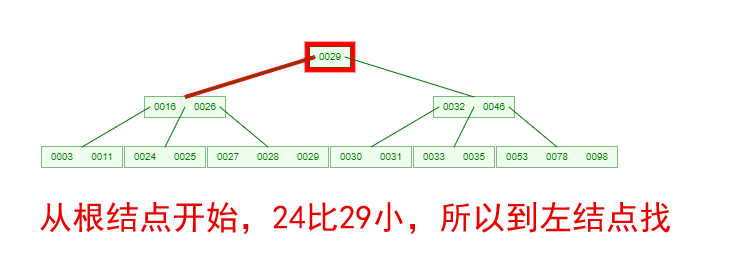
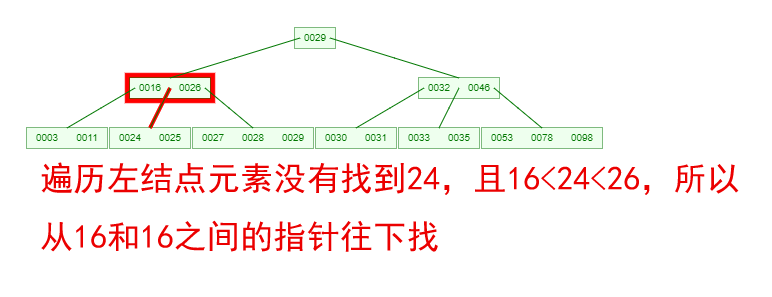
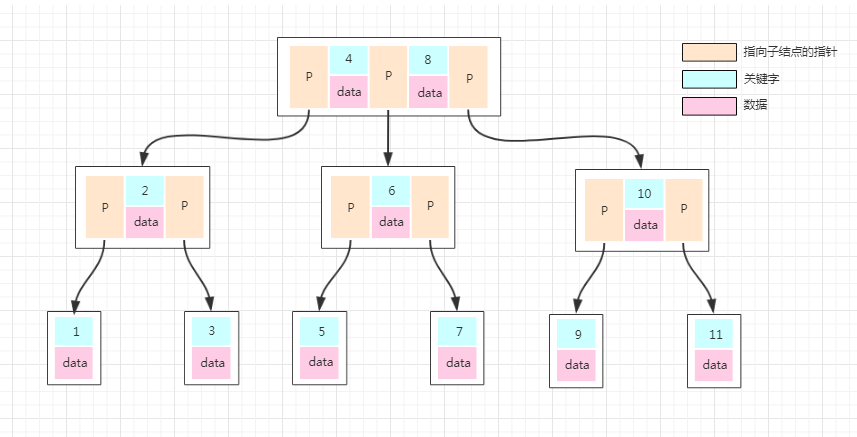
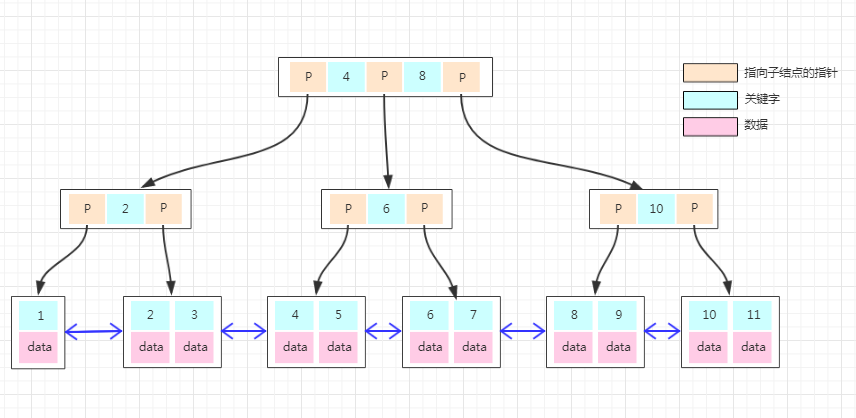
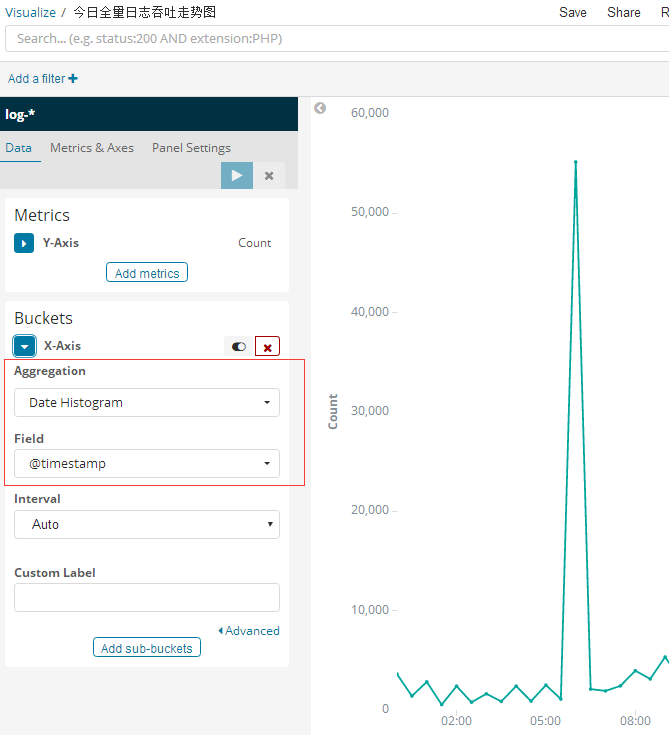
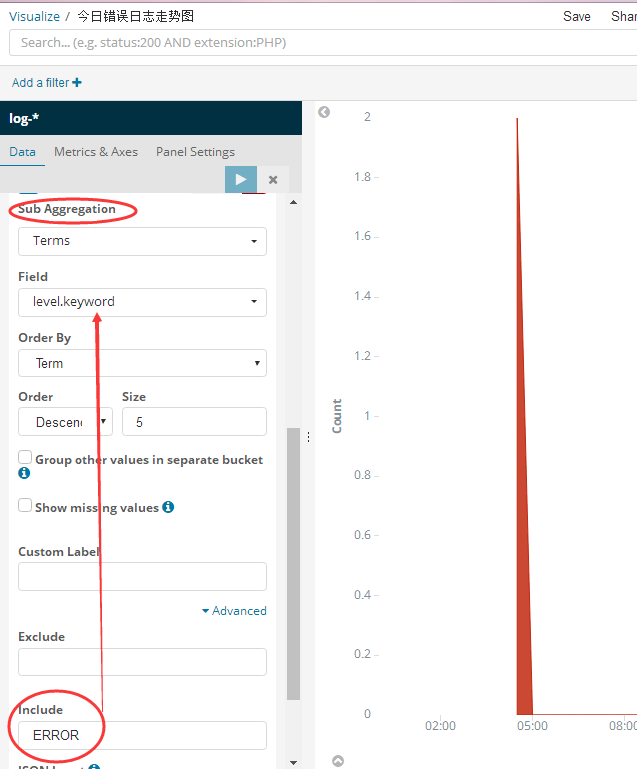
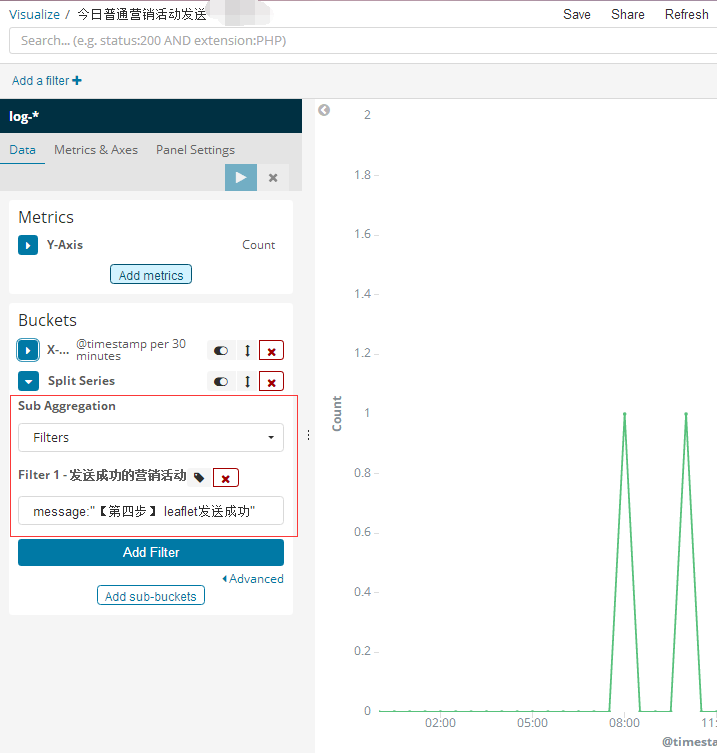
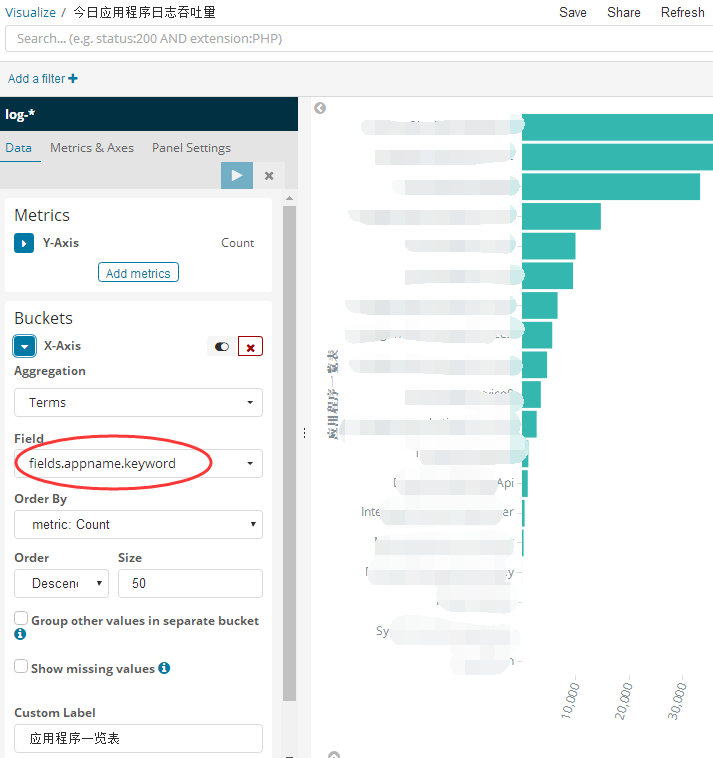
1 ProxySQL简介:
ProxySQL是一个高性能的MySQL中间件,拥有强大的规则引擎。
官方文档: https://github.com/sysown/proxysql/wiki/
下载地址: https://github.com/sysown/proxysql/releases/
2 环境:
- 系统:CentOS7.5
- ProxySQL版本:proxysql-1.4.8-1-centos7.x86_64.rpm
- Mysql版本:MySQL 5.7.22
- ProxySQL主机IP:192.168.1.101
- Mysql主库IP:192.168.1.102
- Mysql从库IP:192.168.1.103
3 前提条件:
- 防火墙和selinux已关闭;
- Mysql主从同步已经配置完成;
4 安装ProxySQL:
4.1 安装
# 配ProxySQL源
[root@ProxySQL ~]# cat <<EOF | tee /etc/yum.repos.d/proxysql.repo
[proxysql_repo]
name= ProxySQL
baseurl=http://repo.proxysql.com/ProxySQL/proxysql-1.4.x/centos/\$releasever
gpgcheck=1
gpgkey=http://repo.proxysql.com/ProxySQL/repo_pub_key
EOF
# 安装
[root@ProxySQL ~]# yum install proxysql -y
# 记一次安装依赖:
perl-Compress-Raw-Bzip2
perl-Compress-Raw-Zlib
perl-DBD-MySQL
perl-DBI
perl-IO-Compress
perl-Net-Daemon
perl-PlRPC
#安装生成的文件:
[root@ProxySQL ~]# rpm -ql proxysql
/etc/init.d/proxysql # 启动脚本
/etc/proxysql.cnf # 配置文件,仅在第一次(/var/lib/proxysql/proxysql.db文件不存在)启动时有效
# 启动后可以在proxysql管理端中通过修改数据库的方式修改配置并生效(官方推荐方式。)
/usr/bin/proxysql #主程序文件
/usr/share/proxysql/tools/proxysql_galera_checker.sh
/usr/share/proxysql/tools/proxysql_galera_writer.pl
或者直接下载rpm包或源码包:
github
官网
4.2 配置文件说明
[root@ProxySQL ~]# egrep -v "^#|^$" /etc/proxysql.cnf
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:admin" # 定义连接管理端口的用户名和密码
mysql_ifaces="0.0.0.0:6032" # 定义管理端口6032;用来连接proxysql的管理数据库,修改proxysql服务的设置以及路由策略
}
mysql_variables=
{
threads=4 # 定义每个转发端口开启多少个线程
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033" # 定义转发端口6033;用来连接后端的mysql实例,起到代理转发的作用;
default_schema="information_schema"
stacksize=1048576
server_version="5.7.22" # 设置后端mysql实例的版本号,仅起到comment的作用
connect_timeout_server=3000
monitor_username="monitor"
monitor_password="monitor"
monitor_history=600000
monitor_connect_interval=60000
monitor_ping_interval=10000
monitor_read_only_interval=1500
monitor_read_only_timeout=500
ping_interval_server_msec=120000
ping_timeout_server=500
commands_stats=true
sessions_sort=true
connect_retries_on_failure=10
}
mysql_servers =
(
)
mysql_users:
(
)
mysql_query_rules:
(
)
scheduler=
(
)
mysql_replication_hostgroups=
(
)
[root@ProxySQL ~]# sed -i 's#5.5.30#5.7.22#g' /etc/proxysql.cnf # 把5.5.30改为自己的版本
4.3 启动proxysql:
4.3.1 添加到开机自启动
[root@ProxySQL ~]# chkconfig proxysql on # 添加到开机自启动,默认已添加
[root@ProxySQL ~]# chkconfig --list |grep proxysql # 查看是否开机自启动
Note: This output shows SysV services only and does not include native
systemd services. SysV configuration data might be overridden by native
systemd configuration.
If you want to list systemd services use 'systemctl list-unit-files'.
To see services enabled on particular target use'systemctl list-dependencies [target]'.
proxysql 0:off 1:off 2:on 3:on 4:on 5:on 6:off
4.3.2 启动
默认情况下,rpm安装的ProxySQL只提供了SysV风格的服务脚本/etc/init.d/proxysql。
所以,可通过该脚本管理ProxySQL的启动、停止等功能。
[root@ProxySQL ~]# /etc/init.d/proxysql --help
Usage: ProxySQL {start|stop|status|reload|restart|initial}
# 启动
[root@ProxySQL ~]# service proxysql start
Starting ProxySQL: DONE!
# 查看
[root@tcloud-113 ~]# service proxysql status
ProxySQL is running (30422).
# 启动后会监听两个端口,默认为6032和6033。6032端口是ProxySQL的管理端口,6033是ProxySQL对外提供服务的端口。
[root@ProxySQL ~]# ss -lntup |grep proxysql
tcp LISTEN 0 128 *:6032 *:* users:(("proxysql",1322,20))
tcp LISTEN 0 128 *:6033 *:* users:(("proxysql",1322,19))
tcp LISTEN 0 128 *:6033 *:* users:(("proxysql",1322,18))
tcp LISTEN 0 128 *:6033 *:* users:(("proxysql",1322,17))
tcp LISTEN 0 128 *:6033 *:* users:(("proxysql",1322,16))
# 可以看到转发端口的6033开启了4个线程,线程数由全局变量"threads"控制,受cpu物理核心数的影响(每个端口下的线程数<=cpu物理核心数)
如果想要通过systemd管理ProxySQL,可在/usr/lib/systemd/system/proxysql.service中写入如下内容:
[root@ProxySQL ~]# vim /usr/lib/systemd/system/proxysql.service
[Unit]
Description=High Performance Advanced Proxy for MySQL
After=network.target
[Service]
Type=simple
User=mysql
Group=mysql
PermissionsStartOnly=true
LimitNOFILE=102400
LimitCORE=1073741824
ExecStartPre=/bin/mkdir -p /var/lib/proxysql
ExecStartPre=/bin/chown mysql:mysql -R /var/lib/proxysql /etc/proxysql.cnf
ExecStart=/usr/bin/proxysql -f
Restart=always
[root@ProxySQL ~]#
一般来说,ProxySQL很少停止或重启,因为绝大多数配置都可以在线修改。
5 配置proxysql
5.1 添加后端连接mysql主从数据库的配置
5.1.1 mysql主库添加proxysql可以增删改查的账号
例如:
user:proxysql;
password:pwproxysql
mysql> GRANT ALL ON *.* TO 'proxysql'@'192.168.1.%' IDENTIFIED BY 'pwproxysql';
5.1.2 登陆proxysql管理端
[root@ProxySQL ~]# yum install mysql -y # 安装mysql客户端命令;依赖:mysql-libs
[root@ProxySQL ~]# export MYSQL_PS1="(\u@\h:\p) [\d]> "
[root@ProxySQL ~]# mysql -uadmin -padmin -h127.0.0.1 -P6032 # 默认的用户名密码都是 admin。
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.5.30 (ProxySQL Admin Module)
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
(admin@127.0.0.1:6032) [(none)]> show databases;
+-----+---------------+-------------------------------------+
| seq | name | file |
+-----+---------------+-------------------------------------+
| 0 | main | |
| 2 | disk | /var/lib/proxysql/proxysql.db |
| 3 | stats | |
| 4 | monitor | |
| 5 | stats_history | /var/lib/proxysql/proxysql_stats.db |
+-----+---------------+-------------------------------------+
5 rows in set (0.00 sec)
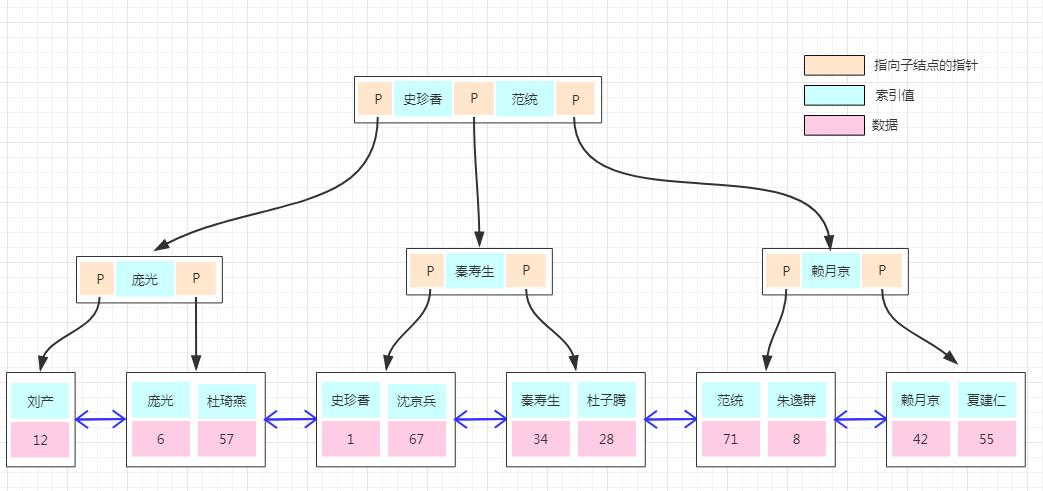
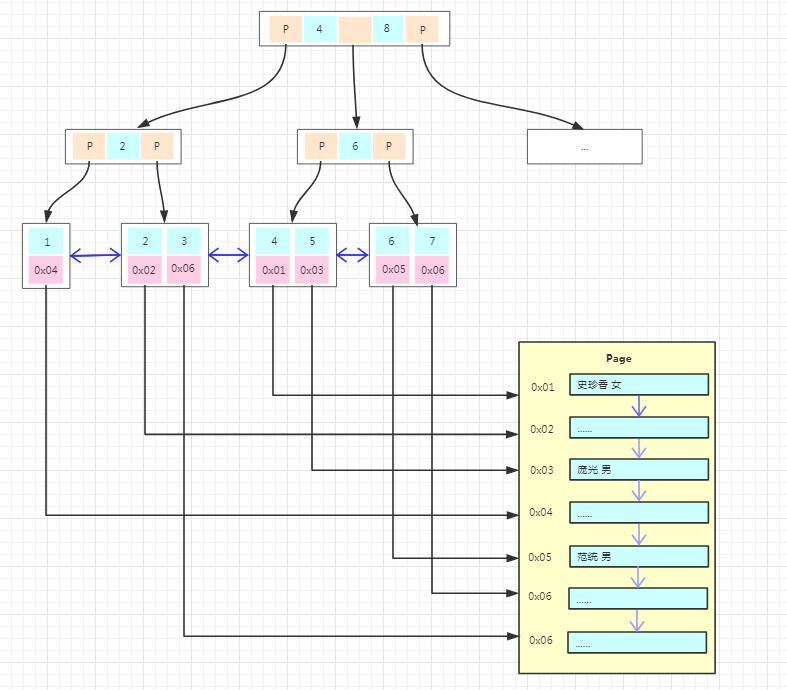
库说明:
- main 内存配置数据库,表里存放后端db实例、用户验证、路由规则等信息。表名以 runtime 开头的表示proxysql当前运行的配置内容,不能通过dml语句修改,只能修改对应的不以 runtime开头的(在内存)里的表,然后 LOAD 使其生效, SAVE 使其存到硬盘以供下次重启加载。
- disk 是持久化到硬盘的配置,sqlite数据文件。
- stats 是proxysql运行抓取的统计信息,包括到后端各命令的执行次数、流量、processlist、查询种类汇总/执行时间等等。
- monitor 库存储 monitor 模块收集的信息,主要是对后端db的健康/延迟检查。
- stats_history 统计信息历史库
5.1.3 Proxysql管理端添加后端连接mysql主从数据库的配置
(admin@127.0.0.1:6032) [(none)]> show tables from main;
+--------------------------------------------+
| tables |
+--------------------------------------------+
| global_variables | # ProxySQL的基本配置参数,类似与MySQL
| mysql_collations | # 配置对MySQL字符集的支持
| mysql_group_replication_hostgroups | # MGR相关的表,用于实例的读写组自动分配
| mysql_query_rules | # 路由表
| mysql_query_rules_fast_routing | # 主从复制相关的表,用于实例的读写组自动分配
| mysql_replication_hostgroups | # 存储MySQL实例的信息
| mysql_servers | # 现阶段存储MySQL用户,当然以后有前后端账号分离的设想
| mysql_users | # 存储ProxySQL的信息,用于ProxySQL Cluster同步
| proxysql_servers | # 运行环境的存储校验值
| runtime_checksums_values | #
| runtime_global_variables | #
| runtime_mysql_group_replication_hostgroups | #
| runtime_mysql_query_rules | #
| runtime_mysql_query_rules_fast_routing | #
| runtime_mysql_replication_hostgroups | # 与上面对应,但是运行环境正在使用的配置
| runtime_mysql_servers | #
| runtime_mysql_users | #
| runtime_proxysql_servers | #
| runtime_scheduler | #
| scheduler | # 定时任务表
+--------------------------------------------+
20 rows in set (0.00 sec)
runtime_开头的是运行时的配置,这些是不能修改的。要修改ProxySQL的配置,需要修改了非runtime_表,修改后必须执行LOAD ... TO RUNTIME才能加载到RUNTIME生效,执行save ... to disk才能将配置持久化保存到磁盘。
下面语句中没有先切换到main库也执行成功了,因为ProxySQL内部使用的SQLite3数据库引擎,和MySQL的解析方式是不一样的。即使执行了USE main语句也是无任何效果的,但不会报错。
使用insert语句添加mysql主机到mysql_servers表中,其中:hostgroup_id 1 表示写组,2表示读组。
(admin@127.0.0.1:6032) [(none)]> insert into mysql_servers(hostgroup_id,hostname,port,weight,comment) values(1,'192.168.1.102',3306,1,'Write Group');
Query OK, 1 row affected (0.00 sec)
(admin@127.0.0.1:6032) [(none)]> insert into mysql_servers(hostgroup_id,hostname,port,weight,comment) values(2,'192.168.1.103',3306,1,'Read Group');
Query OK, 1 row affected (0.00 sec)
(admin@127.0.0.1:6032) [(none)]> select * from mysql_servers;
+--------------+---------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+
| hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+---------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+
| 1 | 192.168.1.102 | 3306 | ONLINE | 1 | 0 | 1000 | 0 | 0 | 0 | Write Group |
| 2 | 192.168.1.103 | 3306 | ONLINE | 1 | 0 | 1000 | 0 | 0 | 0 | Read Group |
+--------------+---------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+-------------+
2 rows in set (0.00 sec)
修改后,加载到RUNTIME,并保存到disk。
(admin@127.0.0.1:6032) [(none)]> load mysql servers to runtime;
(admin@127.0.0.1:6032) [(none)]> save mysql servers to disk;
在proxysql主机的mysql_users表中添加刚才创建的账号,proxysql客户端需要使用这个账号来访问数据库。
default_hostgroup默认组设置为写组,也就是1;
当读写分离的路由规则不符合时,会访问默认组的数据库;
(admin@127.0.0.1:6032) [(none)]> insert into mysql_users(username,password,default_hostgroup,transaction_persistent)values('proxysql','pwproxysql',1,1);
Query OK, 1 row affected (0.00 sec)
(admin@127.0.0.1:6032) [(none)]> select * from mysql_users \G
*************************** 1. row ***************************
username: proxysql # 后端mysql实例的用户名
password: pwproxysql # 后端mysql实例的密码
active: 1 # active=1表示用户生效,0表示不生效
use_ssl: 0
default_hostgroup: 1 # 用户默认登录到哪个hostgroup_id下的实例
default_schema: NULL # 用户默认登录后端mysql实例时连接的数据库,这个地方为NULL的话,则由全局变量mysql-default_schema决定,默认是information_schema
schema_locked: 0
transaction_persistent: 1 # 如果设置为1,连接上ProxySQL的会话后,如果在一个hostgroup上开启了事务,那么后续的sql都继续维持在这个hostgroup上,不伦是否会匹配上其它路由规则,直到事务结束。虽然默认是0
fast_forward: 0 # 忽略查询重写/缓存层,直接把这个用户的请求透传到后端DB。相当于只用它的连接池功能,一般不用,路由规则 .* 就行了
backend: 1
frontend: 1
max_connections: 10000 # #该用户允许的最大连接数
1 row in set (0.00 sec)
修改后,加载到RUNTIME,并保存到disk。
(admin@127.0.0.1:6032) [(none)]> load mysql users to runtime;
(admin@127.0.0.1:6032) [(none)]> save mysql users to disk;
5.2 添加健康监测的账号
5.2.1 mysql端添加proxysql只能查的账号
首先在后端master节点上创建一个用于监控的用户名(只需在master上创建即可,因为会复制到slave上),这个用户名只需具有USAGE权限即可。如果还需要监控复制结构中slave是否严重延迟于master(先混个眼熟:这个俗语叫做"拖后腿",术语叫做"replication lag"),则还需具备replication client权限。这里直接赋予这个权限。
mysql> GRANT replication client ON *.* TO 'monitor'@'192.168.1.%' IDENTIFIED BY 'monitor';
5.2.2 proxysql端修改变量设置健康检测的账号
(admin@127.0.0.1:6032) [(none)]> set mysql-monitor_username='monitor';
Query OK, 1 row affected (0.00 sec)
(admin@127.0.0.1:6032) [(none)]> set mysql-monitor_password='monitor';
Query OK, 1 row affected (0.00 sec)
以上设置实际上是在修改global_variables表,它和下面两个语句是等价的:
(admin@127.0.0.1:6032) [(none)]> UPDATE global_variables SET variable_value='monitor' WHERE variable_name='mysql-monitor_username';
Query OK, 1 row affected (0.00 sec)
(admin@127.0.0.1:6032) [(none)]> UPDATE global_variables SET variable_value='monitor' WHERE variable_name='mysql-monitor_password';
Query OK, 1 row affected (0.00 sec)
修改后,加载到RUNTIME,并保存到disk。
(admin@127.0.0.1:6032) [(none)]> load mysql variables to runtime;
(admin@127.0.0.1:6032) [(none)]> save mysql variables to disk;
5.3 添加读写分离的路由规则:
- 将select语句全部路由至hostgroup_id=2的组(也就是读组)
- 但是select * from tb for update这样的语句是修改数据的,所以需要单独定义,将它路由至hostgroup_id=1的组(也就是写组)
- 其他没有被规则匹配到的组将会被路由至用户默认的组(mysql_users表中的default_hostgroup)
(admin@127.0.0.1:6032) [(none)]> insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)values(1,1,'^SELECT.*FOR UPDATE$',1,1);
Query OK, 1 row affected (0.00 sec)
(admin@127.0.0.1:6032) [(none)]> insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)values(2,1,'^SELECT',2,1);
Query OK, 1 row affected (0.00 sec)
(admin@127.0.0.1:6032) [(none)]> select rule_id,active,match_digest,destination_hostgroup,apply from mysql_query_rules;
+---------+--------+----------------------+-----------------------+-------+
| rule_id | active | match_digest | destination_hostgroup | apply |
+---------+--------+----------------------+-----------------------+-------+
| 1 | 1 | ^SELECT.*FOR UPDATE$ | 1 | 1 |
| 2 | 1 | ^SELECT | 2 | 1 |
+---------+--------+----------------------+-----------------------+-------+
2 rows in set (0.00 sec)
5.4 将刚才我们修改的数据加载至RUNTIME中(参考ProxySQL的多层配置结构):
5.4.1 load进runtime,使配置生效
(admin@127.0.0.1:6032) [(none)]> load mysql query rules to runtime;
(admin@127.0.0.1:6032) [(none)]> load admin variables to runtime;
5.4.2 save到磁盘(/var/lib/proxysql/proxysql.db)中,永久保存配置
(admin@127.0.0.1:6032) [(none)]> save mysql query rules to disk;
(admin@127.0.0.1:6032) [(none)]> save admin variables to disk;
6 测试读写分离
6.1 连接proxysql客户端:
登录用户是刚才我们在mysql_user表中创建的用户,端口为6033
[root@centos7 ~]#mysql -uproxysql -ppwproxysql -h127.0.0.1 -P6033
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 4
Server version: 5.5.30 (ProxySQL)
Copyright (c) 2000, 2017, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec)
MySQL [(none)]>
6.2 尝试修改数据库和查询:
创建两个数据库和查个表。
MySQL [(none)]> create database bigboss;
Query OK, 1 row affected (0.01 sec)
MySQL [(none)]> create database weijinyun;
Query OK, 1 row affected (0.00 sec)
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| bigboss |
| mysql |
| performance_schema |
| test |
| weijinyun |
+--------------------+
6 rows in set (0.01 sec)
MySQL [(none)]> select user,host from mysql.user;
+-------------+---------------+
| user | host |
+-------------+---------------+
| root | 127.0.0.1 |
| monitor | 192.168.1.% |
| proxysql | 192.168.1.% |
| repliaction | 192.168.1.% |
| root | ::1 |
| | centos7 |
| root | centos7 |
| | localhost |
| root | localhost |
+-------------+---------------+
9 rows in set (0.01 sec)
6.3 验证读写分离是否成功:
- proxysql有个类似审计的功能,可以查看各类SQL的执行情况。在proxysql管理端执行:
- 从下面的hostgroup和digest_text值来看,所有的写操作都被路由至1组,读操作都被路由至2组,
- 其中1组为写组,2组为读组!
(admin@127.0.0.1:6032) [(none)]> select * from stats_mysql_query_digest;
+-----------+--------------------+----------+--------------------+----------------------------------------+------------+------------+------------+----------+----------+----------+
| hostgroup | schemaname | username | digest | digest_text | count_star | first_seen | last_seen | sum_time | min_time| max_time |
+-----------+--------------------+----------+--------------------+----------------------------------------+------------+------------+------------+----------+----------+----------+
| 2 | information_schema | proxysql | 0x3EA85877510AC608 | select * from stats_mysql_query_digest | 2 | 1527233735 | 1527233782 | 4092 | 792| 3300 |
| 1 | information_schema | proxysql | 0x594F2C744B698066 | select USER() | 1 | 1527233378 | 1527233378 | 0 | 0| 0 |
| 1 | information_schema | proxysql | 0x02033E45904D3DF0 | show databases | 2 | 1527233202 | 1527233495 | 5950 | 1974| 3976 |
| 1 | information_schema | proxysql | 0x226CD90D52A2BA0B | select @@version_comment limit ? | 2 | 1527233196 | 1527233378 | 0 | 0| 0 |
+-----------+--------------------+----------+--------------------+----------------------------------------+------------+------------+------------+----------+----------+----------+
4 rows in set (0.00 sec)
(admin@127.0.0.1:6032) [(none)]>
读写分离成功!!!
7 参考:
https://blog.51cto.com/bigboss/2103290
http://www.cnblogs.com/f-ck-need-u/p/7586194.html#middleware
http://seanlook.com/2017/04/10/mysql-proxysql-install-config/



 (图片来自WillTran在slideshare分享)
(图片来自WillTran在slideshare分享)
 (图片来自WillTran在slideshare分享)
(图片来自WillTran在slideshare分享) (图片来自网络)
(图片来自网络)
 流程如上图。
流程如上图。 其流程就是:
其流程就是: 这种方式最容易理解了,直接使用用户的用户名/密码作为授权方式去访问 授权服务器,从而获取Access Token,这个方式因为需要用户给出自己的密码,所以非常的不安全性。一般仅在客户端应用与授权服务器、资源服务器是归属统一公司/团队,互相非常信任的情况下采用。
这种方式最容易理解了,直接使用用户的用户名/密码作为授权方式去访问 授权服务器,从而获取Access Token,这个方式因为需要用户给出自己的密码,所以非常的不安全性。一般仅在客户端应用与授权服务器、资源服务器是归属统一公司/团队,互相非常信任的情况下采用。 这是适用于服务器间通信的场景。客户端应用拿一个用户凭证去找授权服务器获取Access Token。
这是适用于服务器间通信的场景。客户端应用拿一个用户凭证去找授权服务器获取Access Token。