午休完上班后,同事说测试站点访问接口出现400 Bad Request Request Header Or Cookie Too Large提示,心想还好是测试服务器出现问题,影响不大,不过也赶紧上服务器进行测试查看,打开nginx与ugwsi日志与配置,发现后端服务日志记录正常,而测试站点的访问日志有7百多M(才运行两三天没几个访问,几M的话才是正常现象),在浏览器里直接访问后端服务接口也正常没有问题(我们的服务器软件架构是微服务架构,将很多模块分拆后分别部署,前端是一个纯HTML站点,通过AJAX访问后端各个服务,由于访问量不大,所以前端站点的nginx配置时,做了反向代理访问后端其他服务,这样就不会出现跨域和需要处理多子域名事情——即访问不同的服务时,只需要使用当前域名就可以了,这样前端开发人员不必要知道后端挂载了多少服务需要使用什么对应的域名访问)。访问这台服务器上的其他站点都能正常访问,而问题站点的html页面也能正常打开......在测试过程中发现,每访问一下问题接口,访问日志就增加30多M,刷了几次,nginx日志大小直线上升......
由于日志比较大,只能使用tail -n 5000 xxx_access.log >> xxx.log截取一下最新的日志记录下载下来,打开一看发现同一时间一个访问,生产了2000多条重复循环的访问记录,而日志尾部$http_x_forwarded_for部分,有规律的存储了相同的由多到少的IP字串,即:最后一条有一个IP字串(真实IP),倒数第二条有两个IP字串(真实IP + 服务器本地IP),倒数第三条有三个IP字串(真实IP + 两个服务器本地IP),以至类推
百度了一下“400 Bad Request Request Header Or Cookie Too Large”,查找出来的几乎都是说“nginx 400 Bad request是request header过大所引起,request过大,通常是由于cookie中写入了较大的值所引起。在nginx.conf中,将client_header_buffer_size和large_client_header_buffers都调大后可解决”,一看就知道这肯定不是我这种情况的解决办法,这是由于不知道什么原因引起的死循环将IP地址串写入请求头,直到缓存爆了才返回400,如果将缓存设置更大,只会造成日志增加速度变大而已。从分析来看应该是nginx出现的问题。
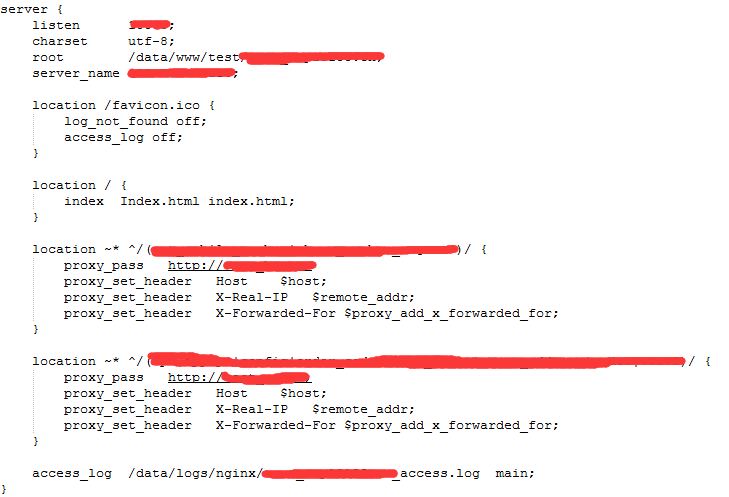
没有办法只能在打开nginx配置文件分析,问题站点的配置文件,如下图,并没有发现什么问题

打开nginx.conf进行慢慢研究,发现多了几行代码
proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
这是用来将当前访问用户的IP传给后端服务器用的,将它们删除重新启动一下服务器nginx后测试了一下,发现能正常访问了...o my god,再将它放回去,重启,访问,挂了,去掉,重启,访问,正常......重试了好几次,终于确定就是突然多出来的几行代码引起的。(后来问了一下同事才知道是他进服务器添加的)
难道真的是不能使用吗?记得以前用过还是正常的。尝试访问预生产环境接口,正常。打开预生产环境的nginx配置,包函有这三行代码,如下图
全面对比后发现,生产环境用的nginx配置是域名,而预生产环境用的是IP+端口,除此之外没有任何区别,使用跳转方式与反向代码方式测试,结果都是一样,添加port_in_redirect、server_name_in_redirect配置也没能解决
综合分析,应该是nginx在使用proxy_pass做跳转时,如果直接使用域名,且需要向后端提交当前访问的IP地址时,引发nginx的bug造成死循环,不知道大家有没有遇到过这种情况。
# 使用反向代理方式
# 正常的配置 upstream xxx{ server127.0.0.1:23456; } upstream yyy { server127.0.0.1:123455; } # 异常配置 upstream xxx1{ server xx.xxx.com; } upstream yyy2 { server yyy.xxx.com; }
# 使用跳转方式 # 正常配置 proxy_pass http://127.0.0.1:23456;# 异常配置 proxy_pass http://xx.xxx.com;
